Review: Cyteen, by C.J. Cherryh
| Series: |
Cyteen #1 |
| Publisher: |
Warner Aspect |
| Copyright: |
1988 |
| Printing: |
September 1995 |
| ISBN: |
0-446-67127-4 |
| Format: |
Trade paperback |
| Pages: |
680 |
The main text below is an edited version of my original review of
Cyteen written on 2012-01-03. Additional comments
from my re-read are after the original review.
I've reviewed several other C.J. Cherryh books somewhat negatively, which
might give the impression I'm not a fan. That is an artifact of when I
started reviewing. I first discovered Cherryh with Cyteen some 20
years ago, and it remains one of my favorite SF novels of all time. After
finishing my reading for 2011, I was casting about for what to start next,
saw Cyteen on my parents' shelves, and decided it was past time for
my third reading, particularly given the recent release of a sequel,
Regenesis.
Cyteen is set in Cherryh's Alliance-Union universe following the
Company Wars. It references several other books in that universe, most
notably Forty Thousand in Gehenna but also
Downbelow Station and others. It also
has mentions of the Compact Space series (The Pride of Chanur and
sequels). More generally, almost all of Cherryh's writing is loosely tied
together by an overarching future history. One does not need to read any
of those other books before reading Cyteen; this book will fill you
in on all of the politics and history you need to know. I read
Cyteen first and have never felt the lack.
Cyteen was at one time split into three books for publishing
reasons: The Betrayal, The Rebirth, and The
Vindication. This is an awful way to think of the book. There are no
internal pauses or reasonable volume breaks; Cyteen is a single
coherent novel, and Cherryh has requested that it never be broken up that
way again. If you happen to find all three portions as your reading copy,
they contain all the same words and are serviceable if you remember it's a
single novel under three covers, but I recommend against reading the
portions in isolation.
Human colonization of the galaxy started with slower-than-light travel
sponsored by the private Sol Corporation. The inhabitants of the far-flung
stations and the crews of the merchant ships that supplied them have
formed their own separate cultures, but initially remained attached to
Earth. That changed with the discovery of FTL travel and a botched attempt
by Earth to reassert its authority. At the time of Cyteen, there
are three human powers: distant Earth (which plays little role in this
book), the merchanter Alliance, and Union.
The planet Cyteen is one of only a few Earth-like worlds discovered by
human expansion, and is the seat of government and the most powerful force
in Union. This is primarily because of Reseune: the Cyteen lab that
produces the azi.
If Cyteen is about any one thing, it's about azi: genetically
engineered human clones who are programmed via intensive psychological
conditioning starting before birth. The conditioning uses a combination of
drugs to make them receptive and "tape," specific patterns of instruction
and sensory stimulation. They are designed for specific jobs or roles,
they're conditioned to be obedient to regular humans, and they're not
citizens. They are, in short, slaves.
In a lot of books, that's as deep as the analysis would go. Azi are
slaves, and slavery is certainly bad, so there would probably be a plot
around azi overthrowing their conditioning, or around the protagonists
trying to free them from servitude. But Cyteen is not any SF novel,
and azi are considerably more complex and difficult than that analysis. We
learn over the course of the book that the immensely powerful head of
Reseune Labs, Ariane Emory, has a specific broader purpose in mind for the
azi. One of the reasons why Reseune fought for and gained the role of
legal protector of all azi in Union, regardless of where they were
birthed, is so that Reseune could act to break any permanent dependence on
azi as labor. And yet, they are slaves; one of the protagonists of
Cyteen is an experimental azi, which makes him the permanent
property of Reseune and puts him in constant jeopardy of being used as a
political prisoner and lever of manipulation against those who care about
him.
Cyteen is a book about manipulation, about programming people,
about what it means to have power over someone else's thoughts, and what
one can do with that power. But it's also a book about connection and
identity, about what makes up a personality, about what constitutes
identity and how people construct the moral codes and values that they
hold at their core. It's also a book about certainty. Azi are absolutely
certain, and are capable of absolute trust, because that's part of their
conditioning. Naturally-raised humans are not. This means humans can do
things that azi can't, but the reverse is also true. The azi are not
mindless slaves, nor are they mindlessly programmed, and several of the
characters, both human and azi, find a lot of appeal in the core of
certainty and deep self-knowledge of their own psychological rules that
azis can have. Cyteen is a book about emotions, and logic, and
where they come from and how to balance them. About whether emotional pain
and uncertainty is beneficial or damaging, and about how one's experiences
make up and alter one's identity.
This is also a book about politics, both institutional and personal. It
opens with Ariane Emory, Councilor for Science for five decades and the
head of the ruling Union Expansionist party. She's powerful, brilliant,
dangerously good at reading people, and dangerously willing to manipulate
and control people for her own ends. What she wants, at the start of the
book, is to completely clone a Special (the legal status given to the most
brilliant minds of Union). This was attempted before and failed, but
Ariane believes it's now possible, with a combination of tape, genetic
engineering, and environmental control, to reproduce the brilliance of the
original mind. To give Union another lifespan of work by their most
brilliant thinkers.
Jordan Warrick, another scientist at Reseune, has had a long-standing
professional and personal feud with Ariane Emory. As the book opens, he is
fighting to be transferred out from under her to the new research station
that would be part of the Special cloning project, and he wants to bring
his son Justin and Justin's companion azi Grant with them. Justin is a PR,
a parental replicate, meaning he shares Jordan's genetic makeup but was
not an attempt to reproduce the conditions of Jordan's rearing. Grant was
raised as his brother. And both have, for reasons that are initially
unclear, attracted the attention of Ariane, who may be using them as
pawns.
This is just the initial setup, and along with this should come a warning:
the first 150 pages set up a very complex and dangerous political
situation and build the tension that will carry the rest of the book, and
they do this by, largely, torturing Justin and Grant. The viewpoint jumps
around, but Justin and Grant are the primary protagonists for this first
section of the book. While one feels sympathy for both of them, I have
never, in my multiple readings of the book, particularly liked them.
They're hard to like, as opposed to pity, during this setup; they have
very little agency, are in way over their heads, are constantly making
mistakes, and are essentially having their lives destroyed.
Don't let this turn you off on the rest of the book. Cyteen takes a
dramatic shift about 150 pages in. A new set of protagonists are
introduced who are some of the most interesting, complex, and delightful
protagonists in any SF novel I have read, and who are very much worth
waiting for. While Justin has his moments later on (his life is so hard
that his courage can be profoundly moving), it's not necessary to like him
to love this book. That's one of the reasons why I so strongly dislike
breaking it into three sections; that first section, which is mostly
Justin and Grant, is not representative of the book.
I can't talk too much more about the plot without risking spoiling it, but
it's a beautiful, taut, and complex story that is full of my favorite
things in both settings and protagonists. Cyteen is a book about
brilliant people who think on their feet. Cherryh succeeds at showing this
through what they do, which is rarely done as well as it is here. It's a
book about remembering one's friends and remembering one's enemies, and
waiting for the most effective moment to act, but it also achieves some
remarkable transformations. About 150 pages in, you are likely to loathe
almost everyone in Reseune; by the end of the book, you find yourself
liking, or at least understanding, nearly everyone. This is extremely
hard, and Cherryh pulls it off in most cases without even giving the
people she's redeeming their own viewpoint sections. Other than perhaps
George R.R. Martin I've not seen another author do this as well.
And, more than anything else, Cyteen is a book with the most
wonderful feeling of catharsis. I think this is one of the reasons why I
adore this book and have difficulties with some of Cherryh's other works.
She's always good at ramping up the tension and putting her characters in
awful, untenable positions. Less frequently does she provide the emotional
payoff of turning the tables, where you get to watch a protagonist do
everything you've been wanting them to do for hundreds of pages, except
even better and more delightfully than you would have come up with.
Cyteen is one of the most emotionally satisfying books I've ever
read.
I could go on and on; there is just so much here that I love. Deep
questions of ethics and self-control, presented in a way that one can see
the consequences of both bad decisions and good ones and contrast them.
Some of the best political negotiations in fiction. A wonderful look at
friendship and loyalty from several directions. Two of the best semi-human
protagonists I've seen, who one can see simultaneously as both wonderful
friends and utterly non-human and who put nearly all of the androids in
fiction to shame by being something trickier and more complex. A wonderful
unfolding sense of power. A computer that can somewhat anticipate problems
and somewhat can't, and that encapsulates much of what I love about
semi-intelligent bases in science fiction. Cyteen has that rarest
of properties of SF novels: Both the characters and the technology meld in
a wonderful combination where neither could exist without the other, where
the character issues are illuminated by the technology and the technology
supports the characters.
I have, for this book, two warnings. The first, as previously mentioned,
is that the first 150 pages of setup is necessary but painful to read, and
I never fully warmed to Justin and Grant throughout. I would not be
surprised to hear that someone started this book but gave up on it after
50 or 100 pages. I do think it's worth sticking out the rocky beginning,
though. Justin and Grant continue to be a little annoying, but there's so
much other good stuff going on that it doesn't matter.
The other warning is that part of the setup of the story involves the rape
of an underage character. This is mostly off-camera, but the emotional
consequences are significant (as they should be) and are frequently
discussed throughout the book. There is also rather frank discussion of
adolescent sexuality later in the book. I think both of these are relevant
to the story and handled in a way that isn't gratuitous, but they made me
uncomfortable and I don't have any past history with those topics.
Those warnings notwithstanding, this is simply one of the best SF novels
ever written. It uses technology to pose deep questions about human
emotions, identity, and interactions, and it uses complex and interesting
characters to take a close look at the impact of technology on lives. And
it does this with a wonderfully taut, complicated plot that sustains its
tension through all 680 pages, and with characters whom I absolutely love.
I have no doubt that I'll be reading it for a fourth and fifth time some
years down the road.
Followed by Regenesis, although
Cyteen stands well entirely on its own and there's no pressing need
to read the sequel.
Rating: 10 out of 10
Some additional thoughts after re-reading Cyteen in
2025:
I touched on this briefly in my original review, but I was really struck
during this re-read how much the azi are a commentary on and a
complication of the role of androids in earlier science fiction. Asimov's
Three Laws of Robotics were an attempt to control the risks of robots, but
can also be read as turning robots into slaves. Azis make the slavery more
explicit and disturbing by running the programming on a human biological
platform, but they're more explicitly programmed and artificial than a lot
of science fiction androids.
Artificial beings and their relationship to humans have been a recurring
theme of SF since Frankenstein, but I can't remember a novel that
makes the comparison to humans this ambiguous and conflicted. The azi not
only like being azi, they can describe why they prefer it. It's clear that
Union made azi for many of the same reasons that humans enslave other
humans, and that Ariane Emory is using them as machinery in a larger (and
highly ethically questionable) plan, but Cherryh gets deeper into the
emergent social complications and societal impact than most SF novels
manage. Azi are apparently closer to humans than the famous SF examples
such as Commander Data, but the deep differences are both more subtle and
more profound.
I've seen some reviewers who are disturbed by the lack of a clear moral
stance by the protagonists against the creation of azi. I'm not sure what
to think about that. It's clear the characters mostly like the society
they've created, and the groups attempting to "free" azi from their
"captivity" are portrayed as idiots who have no understanding of azi
psychology. Emory says she doesn't want azi to be a permanent aspect of
society but clearly has no intention of ending production any time soon.
The book does seem oddly unaware that the production of azi is unethical
per se and, unlike androids, has an obvious exit ramp: Continue cloning
gene lines as needed to maintain a sufficient population for a growing
industrial civilization, but raise the children as children rather than
using azi programming. If Cherryh included some reason why that was
infeasible, I didn't see it, and I don't think the characters directly
confronted it.
I don't think societies in books need to be ethical, or that Cherryh
intended to defend this one. There are a lot of nasty moral traps that
civilizations can fall into that make for interesting stories. But the
lack of acknowledgment of the problem within the novel did seem odd this
time around.
The other part of this novel that was harder to read past in this re-read
is the sexual ethics. There's a lot of adolescent sexuality in this book,
and even apart from the rape scene — which was more on-the-page than I had
remembered and which is quite (intentionally) disturbing — there is a
whole lot of somewhat dubious consent. Maybe I've gotten older or just
more discriminating, but it felt weirdly voyeuristic to know this much
about the sex lives of characters who are, at several critical points in
the story, just a bunch of kids.
All that being said, and with the repeated warning that the first 150
pages of this novel are just not very good, there is still something magic
about the last two-thirds of this book. It has competence porn featuring a
precociously brilliant teenager who I really like, it has one of
the more interesting non-AI programmed computer systems that I've read in
SF, it has satisfying politics that feel like modern politics
(media strategy and relationships and negotiated alliances, rather than
brute force and ideology), and it has a truly excellent feeling of
catharsis. The plot resolution is a bit too abrupt and a bit
insufficiently explained (there's more in Regenesis), but even
though this was my fourth time through this book, the pacing grabbed me
again and I could barely put down the last part of the story.
Ethics aside (and I realize that's quite the way to start a sentence), I
find the azi stuff fascinating. I know the psychology in this book is not
real and is hopelessly simplified compared to real psychology, but there's
something in the discussions of value sets and flux and self-knowledge
that grabs my interest and makes me want to ponder. I think it's the
illusion of simplicity and control, the what-if premise of thought where
core motivations and moral rules could be knowable instead of endlessly
fluid the way they are in us humans. Cherryh's azi are some of the most
intriguing androids in science fiction to me precisely because they don't
start with computers and add the humanity in, but instead start with
humanity and overlay a computer-like certainty of purpose that's fully
self-aware. The result is more subtle and interesting than anything
Star Trek managed.
I was not quite as enamored with this book this time around, but it's
still excellent once the story gets properly started. I still would
recommend it, but I might add more warnings about the disturbing parts.
Re-read rating: 9 out of 10















































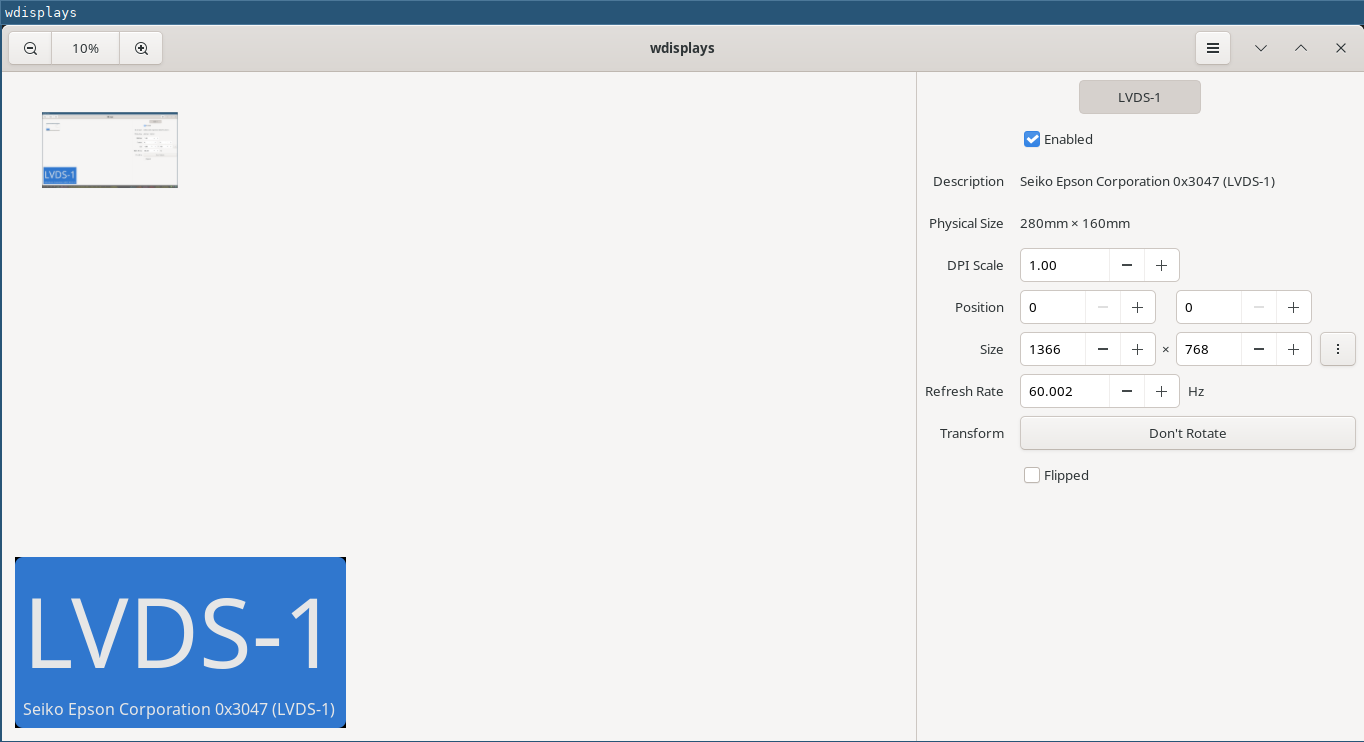
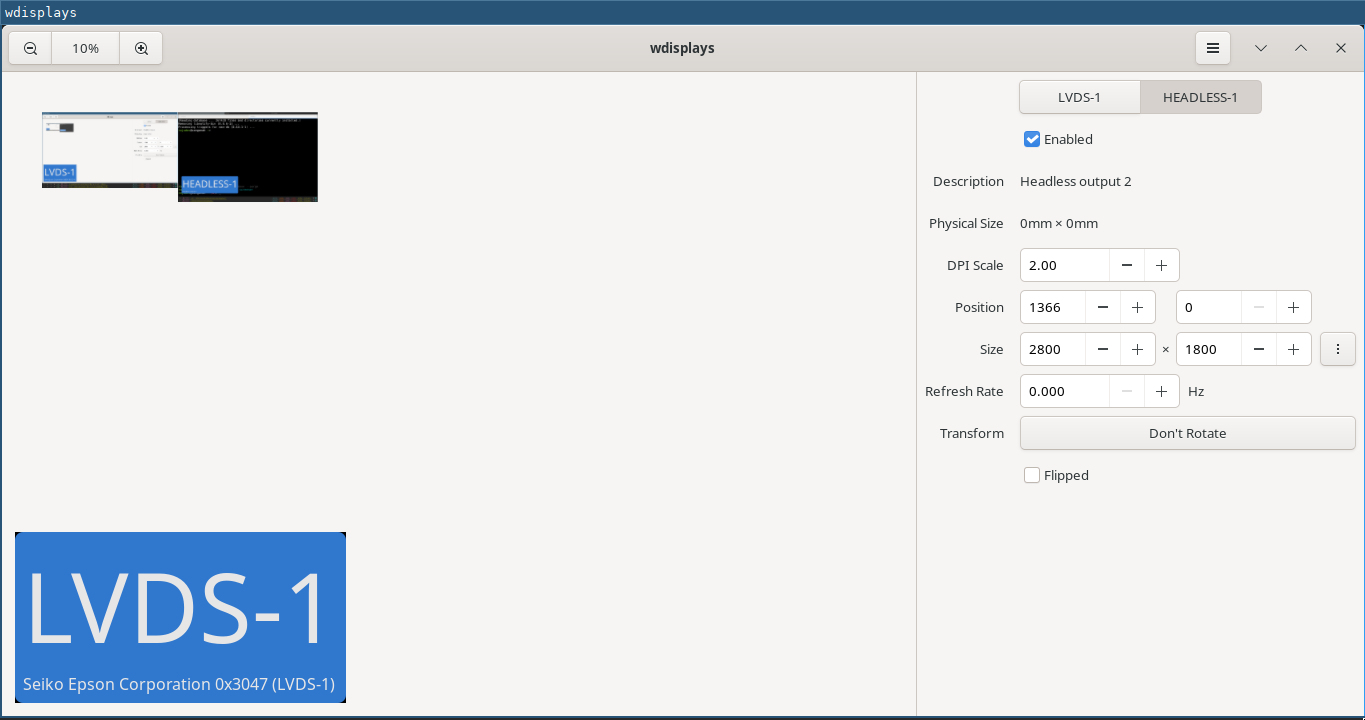
 There's a lovely device called a
There's a lovely device called a  Partners holding big jigsaw puzzle pieces flat vector illustration. Successful partnership, communication and collaboration metaphor. Teamwork and business cooperation concept.
Partners holding big jigsaw puzzle pieces flat vector illustration. Successful partnership, communication and collaboration metaphor. Teamwork and business cooperation concept.






 What a surprise it's August already.
What a surprise it's August already.









 Pollito and the gang of DebConf mascots wearing their conference badges (photo: Christoph Berg)
Pollito and the gang of DebConf mascots wearing their conference badges (photo: Christoph Berg) F/DF7CB in Brest (photo: Evangelos Ribeiro Tzaras)
F/DF7CB in Brest (photo: Evangelos Ribeiro Tzaras)
 The northern coast of Ushant (photo: Christoph Berg)
The northern coast of Ushant (photo: Christoph Berg)
 Having a nice day (photo: Christoph Berg)
Having a nice day (photo: Christoph Berg)
 Pollito on stage (photo: Christoph Berg)
Pollito on stage (photo: Christoph Berg)