I have bought myself an expensive ARM64 workstation, the System 76 Thelio Astra that I intend to use as my main desktop computer for the next 15 years, running Debian.
The box is basically a server motherboard repurposed in a good desktop chassis. In Europe it seems you can order similar ready systems here.
The hardware is well supported by Debian 12 and Debian testing.I had some initial issues with graphics, due to the board being designed for a server use, but I am solving these as we go.
Annoyances I got so far:
When you power on the machine using the power supply switch, you have to wait for the BMC to finished its startup sequence, before the front power button does anything. As starting the BMC can take 90 seconds, I thought initially the machine was dead on arrival.
The default graphical output is redirected to the BMC Serial over LAN, which means if you want to install Debian using an attached display you need to force the output on the attached display passing console=tty0 as an installer parameter.
Finally the Xorg Nouveau driver does not work with the Nvidia A400 GPU I got with the machine.
After passing nodemodeset as a kernel parameter, I can force Xorg to use an unaccelerated framebuffer, which at least displays something. I passed this parameter to the installer, so that I could install in graphical mode.
The driver from Nvidia works, but I’d like very much to get Nouveau running.
Ugly point
A server mother board we said. This mean there is NO suspend to RAM, you have to power off if you don’t want to keep the machine on all the time.
As the boot sequence is long (server board again) I am pondering setting a startup time in the UEFI firmware to turn the box on at specific usage time.
Good points
The firmware of the machine is a standard EFI, which means you can use the debian arm64 installer on an USB stick straight away, without any kind of device tree / bootloader fiddling.
The 3 Nics, Wifi, bluetooth were all recognized on first boot.
I was afraid the machine would be loud. However it is quiet, you hear the humming of a fan, but it is quieter than most desktops I owned, from the Atari TT to an all in one Lenovo M92z I used for 10 years. I am certainly not a hardware and cooling specialist, but meseems the quietness comes from slow rotating but very large fans.
Due the clean design of Linux and Debian, thousands of packages working correctly on ARM64, starting with the Gnome desktop environment and Firefox.
The documentation from system76 is fine, their Ubuntu 20.04 setup guide was helpful to understand the needed parameters mentioned above.
I hope to make a correct DebianOn wiki article once I am done through the configuration issues.
Another short status update of what happened on my side last
month. Larger blocks besides the Phosh 0.47 release are on screen
keyboard and cell broadcast improvements, work on separate volume
streams, the switch of phoc to wlroots to 0.19.0 and effort to make
Phosh work on Debian's upcoming stable release (Trixie) out of the
box. Trixie will ship with Phosh 0.46, if you want to try out 0.47
you can fetch it from Debian's experimental suite.
Standardize audio stream roles (MR). Otherwise we'll have a hard time
with e.g. WirePlumbers role based policy linking as apps might use all kinds of types.
Reviews
This is not code by me but reviews on other peoples code. The list is
(as usual) slightly incomplete. Thanks for the contributions!
Author: Aubrey Williams I’ve been looking for work for months now. After the chip company got all-new machinery, the bean-counters did a review, and I was one of the names that got a red strikethrough. I can’t live on redundancy forever, and I’m not poor enough to get a rare welfare payment, so I need […]
1. Please don't use the TACO slur. It may amuse you and irk your enemy, sure. But this particular mockery has one huge drawback. It might taunt him into not backing down ('chickening out') some time when it's really needed, in order to save all our lives. So... maybe... grow up and think tactics?
A far more effective approach is to hammer hypocrisy!
Yeah, sure. Many have tried that. Though never with the relentless consistency that cancels their tactic of changing the subject.
I've never seen it done with the kind of harsh repetitive simplicity that I recommended in Polemical Judo. Repetitive simplicity that is the tactic that the Foxites perfected! As when all GOPpers repeat the same party line all together - like KGB metronomes - all on the same morning.
And hence...
2. ... and hence, here is a litany of hypocrisy and poor memory that is capsulated enough to be shouted!
These are challenges that might reach a few of your getting-nervous uncles. especially as a combined list!
Ten years ago, Donald Trump promised proof that Barack Obama was born in Kenya.
“Soon! The case is water-tight and ready. I'll present it next week!”The same promise got repeated, week after week, month after month. And sure, his dittohead followers relished not facts, but the hate mantra, so they never kept track...
Also ten years ago Beck and Hannity etc. declared "George Soros personally toppled eight foreign governments!" (Actually, it's sort of true!) They promised to list those eight Soros-toppled victims! Only they never did. Because providing that list would have left Fox a smoldering ruin.
Nine years ago, running against H Clinton, Donald Trump declared I will build a Big Beautiful WALL!" From sea to shining sea.
Funny how he never asked his GOP-run Congress, later, for the money. And he still hasn't. Clinton and Obama each built more fences & surveillance systems to control the border than Trump ever did.
Also nine years ago,"You’ll never see me on a golf course, I’ll be working so hard for you!” Um...
Eight years ago - after inauguration and taking over the US government, he vowed: “Within weeks the indictments will roll in a great big wave. You’ll see the Obama Administration was the most corrupt ever!”
(Real world: there were zero indictments of the most honest and least blemished national administration in all of human history. Bar none. In fact, grand juries - consisting mostly of white retirees in red states - have indicted FORTY TIMES as many high Republicans as Democrats. Care to offer wager stakes?)
Also eight years ago, his 1st foreign guests in the White House - Lavrov and Kisliak, giggled with him ecstatically (see below), thinking their KGB tricks had captured the USA. Alas for Putin's lads, it took them 8 more years.
Seven years ago, ol’ Two Scoops promised a “terrific health care bill for everyone!” to replace ‘horrible Obamacare!’ And repeatedly for the next six years he declared “You’ll see it in two weeks!” And then... in 2 weeks. And then... in 2 weeks. And then in 2 weeks… twenty... fifty more times.
Also seven years ago,"Kim Jong Un and I fell in love!" (see above).
Six years ago, Fox “News” declared in court “we don’t do news, we are an entertainment company,” in order to writhe free of liability and perjury for oceans of lies. And still Fox had to pay $150 millions.
Five years ago Trump’s son-in-law was “about to seal the deal on full peace in the Middle East!”
Four years ago, Don promised “Absolute proof the election was stolen by Biden and the dems!"
Howl after howl by Foxite shills ensued, and yet, not one scintilla of credible evidence was ever presented. While blowhards and blockheads fulminated into secessionist fury, all courts – including many GOP appointed judges - dismissed every 'case' as ludicrous, and several of them fined Trumpist shriekers for frivolous lying. Oh, the screeches and spumes! But not…one…shred of actual evidence. Ever.
Three years ago, three different GOP Congressmen alluded-to or spoke-of how sex orgies are rife among top DC Republicans. And two of them alluded to resulting blackmail.
Trump demanded “release the Epstein Files!”... then filed every lawsuit that his lawyers could concoct, in order to prevent it. And to protect an ocean of NDAs.
Oh, and he promised “Great revelations!” on UFOs and the JFK assassination, just as soon as he got back in office. Remember that? Disappointed, a little? And Epstein's pal is still protected.
Two years ago, Paul Ryan and Mitt Romney and even Mitch McConnell were hinting at a major push to reclaim the Republican Party - or at least a vestigially non-traitor part of it - from the precipice where fanaticism and blackmail and treason had taken it.
If necessary - (it was said) - they would form a new, Real Rebublican Party, where a minority of decent adults remaining in the GOP 'establishment' might find refuge and begin rebuilding.
Only it seems that crown prince Ryan & co. chickened out, as he always has... RACO.
One year ago... actually less... the Economist offered this cover plus detailed stats, showing what always happens. That by the end of every Democratic administration, most things - certainly the economy and yes, deficits - are better. And they always get worse across the span of GOP admins. Care to bet this time?
Alas, now the bitterly laughingstock of the world, deliberately immolating the universities and science and professions that truly Made America Great.
There's your year-by year Top Ten Hypocricies countdown. And it's worth a try, to see if hammering the same things over and over - which worked so well for the Foxites might be worth a try?
Oh, sure. Those aren’t my paramount complaints against Putin’s lackey and his shills.
My main gripe is the one thing that unites them all -- Trump’s oligarchs with foreign enemies and with MAGA groundlings.
That one goal? Shared hatred of every single fact using profession, from science and civil service to the FBI/intel/military officer corps who won the Cold War and the War on Terror…
... the very ones standing between YOU and a return to feudal darkness.*
These reminder samplers of promises never kept are still valid. They could be effective if packaged properly, And will someone please show me who – in this wilderness – is pointing at them?
== Final lagniappe... a reminder of the most-loathesome of all... ==
* And yeah... here again in the news is the would-be Machiavelli/Wormtongue who flatter-strokes the ingrate, would-be lords who are seeking to betray the one renaissance that gave them everything they have.
Okay, I was planning to finish with a riff (again) on teleologies or notions of TIME. Very different notions that are clutched by the far-left, by today's entire right, and by the beleaguered liberal/middle.
Is there a best path to getting both individuals and societies to behave honestly and fairly?
That goal -- attaining fact-based perception -- was never much advanced by the ‘don’t lie’ commandments of finger-wagging moralists and priests.
Sure, for 6000 years, top elites preached and passed laws against lies and predation... only to become the top liars and self-deceivers, bringing calamities down upon the nations and peoples that they led.
Laws can help. But the ’essential trick’ that we’ve gradually become somewhat good-at is reciprocal accountability (RA)… keeping an eye on each other laterally and speaking up when we see what we perceive as mistakes.
It was recommended by Pericles around 300 BCE… then later by Adam Smith and the founders of our era. Indeed, humanity only ever found one difficult but essential trick for getting past our human yen for lies and delusion.
Yeah, sometimes it’s the critic who is wrong! Still, one result is a system that’s open enough to spot most errors – even those by the mighty – and criticize them (sometimes just in time and sometimes too late) so that many get corrected. We aren’t yet great at it! Though better than all prior generations. And at the vanguard in this process is science.
Sure, scientists are human and subject to the same temptations to self-deceive or even tell lies. In training*, we are taught to recite the sacred catechism of science: “I might be wrong!” That core tenet – plus piles of statistical and error-checking techniques – made modern science different – and vastly more effective (and less hated) -- than all or any previous priesthoods. Still, we remain human. And delusion in science can have weighty consequences.
(*Which may help explain the oligarchy's current all-out war against science and universities.)
He notes, “Science has a fraud problem. Highly cited research is often based on faked data, which causes other researchers to pursue false leads. In medical research, the time wasted by followup studies can delay the discovery of effective treatments for serious diseases, potentially causing millions of lives to be lost.”
As I said: that’s an exaggeration – one that feeds into today’s Mad Right in its all-out war vs every fact-using profession. (Not just science, but also teaching, medicine and law and civil service to the heroes of the FBI/Intel/Military officer corps who won the Cold War and the War on terror.) The examples that he cites were discovered and denounced BY science! And the ratio of falsehood is orderd of magnitude less than any other realm of huiman endeavor.
Still, the essay is worth reading for its proposed solution. Which boils down to do more reciprocal accountability, only do it better!
The proposal would start with the powerful driver of scientific RA – the fact that most scientists are among the most competitive creatures that this planet ever produced – nothing like the lemming, paradigm-hugger disparagement-image that's spread by some on the far-left and almost everyone on today’s entire gone-mad right.
Only this author proposes we then augment that competitiveness with whistle blower rewards, to incentivize the cross-checking process with cash prizes.
Do you know the “hype cycle curve”? That’s an observational/pragmatic correlation tool devised by Gartner in the 90s, for how new technologies often attract heaps of zealous attention, followed by a crash of disillusionment, when even the most promising techs encounter obstacles to implementation, and many just prove wrong. This trough is followed, in a few cases, by a more grounded rise in solid investment, as productivity takes hold. (It happened repeatedly with railroads and electricity.) The inimitable Sabine Hossenfelder offers a podcast about this, using recent battery tech developments as examples.
The takeaways: yes, it seems that some battery techs may deliver major good news pretty soon. And remember this ‘hype cycle’ thing is correlative, not causative. It has almost no predictive utility in individual cases.
But the final take-away is also important. That progress IS being made! Across many fronts and very rapidly. And every single thing you are being told about the general trend toward sustainable technologies by the remnant, withering denialist cult is a pants-on-fire lie.
Take this jpeg I just copied from the newsletter of Peter Diamandis, re: the rapidly maturing tech of perovskite based solar cells, which have a theoretically possible efficiency of 66%, double that of silicon.
(And many of you first saw the word “perovskite” in my novel Earth, wherein I pointed out that most high-temp superconductors take that mineral form… and so does most of the Earth’s mantle. Put those two together! As I did, in that novel.)
Dosubscribeto Peter’s Abundance Newsletter, as an antidote to the gloom that’s spread by today’s entire right and much of today’s dour, farthest-fringe-left. The latter are counter-productive sanctimony junkies, irritating but statistically unimportant as we make progress without much help from them.
The former are a now a science-hating treason-cult that’s potentially lethal to our civilization and world and our children. And for those neighbors of ours, the only cure will be victory – yet again, and with malice toward none – by the Union side in this latest phase of our recurring confederate fever.
== A final quirky thought ==
Has anyone else noticed how many traits of AI chat/image-generation etc - including the delusions, the weirdly logical illogic, and counter-factual internal consistency - are very similar to dreams?
Addendum: When (seldom) a dream is remembered well, the narrative structure can be recited and recorded. 100 years of freudian analysts have a vast store of such recitations that could be compared to AI-generated narratives. Somebody unleash the research!
It bugs me: all the US civil servants making a 'gesture' of resigning, when they are thus undermining the standing of the Civil Service Act, under which they can demand to be fired only for cause. And work to rule, stymieing the loony political appointees, as in YES, MINISTER.
Or moronic media who are unable to see that most of the firings are for show, to distract from the one set that matters to the oligarchs. Ever since 2021 they have been terrified of the Pelosi bill that fully funded the starved and bedraggled IRS for the 1st time in 30 years. The worst oligarchs saw jail - actual jail - looming on the horizon and are desperate to cripple any looming audits. All the other 'doge' attacks have that underlying motive, to distract from what foreign and domestic oligarchs care about..
Weakening the American Pax -which gave humanity by far its greatest & best era - IS the central point. Greenland is silliness, of course. The Mercator projection makes DT think he'd be making a huge Louisiana Purchase. But he's too cheap to make the real deal... offer each Greenland native $1million. Actually, just 55% of the voters. That'd be $20 Billion. Heck it's one of the few things where I hope he succeeds. Carve his face on a dying glacier.
Those mocking his Canada drool are fools. Sure, it's dumb and Canadians want no part of it. But NO ONE I've seen has simply pointed out .. that Canada has ten provinces, and three territories, all with more population than Greenland. 8 of ten would be blue and the other two are Eisenhowe or Reagan red and would tire of DT, fast. So, adding Greenlan,d we have FOURTEEN new states, none of whom would vote for today's Putin Party. That one fact would shut down MAGA yammers about Canada instantly.
Ukraine is simple: Putin is growing desperate and is demanding action from his puppet. I had fantasized that Trump might now feel so safe that he could ride out any blackmail kompromat that Vlad is threatening him with. But it's pretty clear that KGB blackmailers run the entire GOP.
Author: Eva C. Stein After the service, they didn’t speak much. They walked through the old arcade – a fragment of the city’s former network. The glass canopy had long since shattered. Bio-moss cushioned the broken frames. Vines, engineered to reclaim derelict structures, crept along the walls. Mae’s jacket was too thin for the chill […]
Have you ever found yourself in the situation where you had no or
anonymized logs and still wanted to figure out where your traffic was
coming from?
Or you have multiple upstreams and are looking to see if you can save
fees by getting into peering agreements with some other party?
Or your site is getting heavy load but you can't pinpoint it on a
single IP and you suspect some amoral corporation is training their
degenerate AI on your content with a bot army?
(You might be getting onto something there.)
If that rings a bell, read on.
TL;DR:
... or just skip the cruft and install asncounter:
pip install asncounter
Also available in Debian 14 or later, or possibly in Debian 13
backports (soon to be released) if people are interested:
tcpdump -q -i eth0 -n -Q in "tcp and tcp[tcpflags] & tcp-syn != 0 and (port 80 or port 443)" | asncounter --input-format=tcpdump --repl
Read on for why this matters, and why I wrote yet another weird tool
(almost) from scratch.
Background and manual work
This is a tool I've been dreaming of for a long, long time. Back in
2006, at Koumbit a colleague had setup TAS ("Traffic
Accounting System", "Система учета трафика" in Russian, apparently), a
collection of Perl script that would do per-IP accounting. It was
pretty cool: it would count bytes per IP addresses and, from that, you
could do analysis. But the project died, and it was kind of bespoke.
Fast forward twenty years, and I find myself fighting off bots at the
Tor Project (the irony...), with our GitLab suffering pretty bad
slowdowns (see issue tpo/tpa/team#41677 for the latest public
issue, the juicier one is confidential, unfortunately).
(We did have some issues caused by overloads in CI, as we host, after
all, a fork of Firefox, which is a massive repository, but the
applications team did sustained, awesome work to fix issues on that
side, again and again (see tpo/applications/tor-browser#43121 for
the latest, and tpo/applications/tor-browser#43121 for some
pretty impressive correlation work, I work with really skilled
people). But those issues, I believe were fixed.)
So I had the feeling it was our turn to get hammered by the AI
bots. But how do we tell? I could tell something was hammering at
the costly /commit/ and (especially costly) /blame/ endpoint. So
at first, I pulled out the trusted awk, sort | uniq -c | sort -n |
tail pipeline I am sure others have worked out before:
For people new to this, that pulls the first field out of web server
log files, sort the list, counts the number of unique entries, and
sorts that so that the most common entries (or IPs) show up first,
then show the top 10.
That, other words, answers the question of "which IP address visits
this web server the most?" Based on this, I found a couple of IP
addresses that looked like Alibaba. I had already addressed an abuse
complaint to them (tpo/tpa/team#42152) but never got a response,
so I just blocked their entire network blocks, rather violently:
for cidr in 47.240.0.0/14 47.246.0.0/16 47.244.0.0/15 47.235.0.0/16 47.236.0.0/14; do
iptables-legacy -I INPUT -s $cidr -j REJECT
done
That made Ali Baba and his forty thieves (specifically their
AL-3 network go away, but our load was still high, and I was
still seeing various IPs crawling the costly endpoints. And this time,
it was hard to tell who they were: you'll notice all the Alibaba IPs
are inside the same 47.0.0.0/8 prefix. Although it's not a /8
itself, it's all inside the same prefix, so it's visually easy to
pick it apart, especially for a brain like mine who's stared too long
at logs flowing by too fast for their own mental health.
What I had then was different, and I was tired of doing the stupid
thing I had been doing for decades at this point. I had recently
stumbled upon pyasn recently (in January, according to my notes)
and somehow found it again, and thought "I bet I could write a quick
script that loops over IPs and counts IPs per ASN".
(Obviously, there are lots of other tools out there for that kind of
monitoring. Argos, for example, presumably does this, but it's a kind
of a huge stack. You can also get into netflows, but there's serious
privacy implications with those. There are also lots of per-IP
counters like promacct, but that doesn't scale.
Or maybe someone already had solved this problem and I just wasted a
week of my life, who knows. Someone will let me know, I hope, either
way.)
ASNs and networks
A quick aside, for people not familiar with how the internet
works. People that know about ASNs, BGP announcements and so on can
skip.
The internet is the network of networks. It's made of multiple
networks that talk to each other. The way this works is there is a
Border Gateway Protocol (BGP), a relatively simple TCP-based protocol,
that the edge routers of those networks used to announce each other
what network they manage. Each of those network is called an
Autonomous System (AS) and has an AS number (ASN) to uniquely identify
it. Just like IP addresses, ASNs are allocated by IANA and local
registries, they're pretty cheap and useful if you like running your
own routers, get one.
When you have an ASN, you'll use it to, say, announce to your BGP
neighbors "I have 198.51.100.0/24" over here and the others might
say "okay, and I have 216.90.108.31/19 over here, and I know of this
other ASN over there that has 192.0.2.1/24 too! And gradually, those
announcements flood the entire network, and you end up with each BGP
having a routing table of the global internet, with a map of which
network block, or "prefix" is announced by which ASN.
It's how the internet works, and it's a useful thing to know, because
it's what, ultimately, makes an organisation responsible for an IP
address. There are "looking glass" tools like the one provided by
routeviews.org which allow you to effectively run "trace routes"
(but not the same as traceroute, which actively sends probes from
your location), type an IP address in that form to fiddle with it. You
will end up with an "AS path", the way to get from the looking glass
to the announced network. But I digress, and that's kind of out of
scope.
Point is, internet is made of networks, networks are autonomous
systems (AS) and they have numbers (ASNs), and they announced IP
prefixes (or "network blocks") that ultimately tells you who is
responsible for traffic on the internet.
Introducing asncounter
So my goal was to get from "lots of IP addresses" to "list of ASNs",
possibly also the list of prefixes (because why not). Turns out pyasn
makes that really easy. I managed to build a prototype in probably
less than an hour, just look at the first version, it's 44 lines
(sloccount) of Python, and it works, provided you have already
downloaded the required datafiles from routeviews.org. (Obviously, the
latest version is longer at close to 1000 lines, but it downloads the
datafiles automatically, and has many more features).
The way the first prototype (and later versions too, mostly) worked is
that you feed it a list of IP addresses on standard input, it looks up
the ASN and prefix associated with the IP, and increments a counter
for those, then print the result.
That showed me something like this:
root@gitlab-02:~/anarcat-scripts# tcpdump -q -i eth0 -n -Q in "(udp or tcp)" | ./asncounter.py --tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
INFO: collecting IPs from stdin, using datfile ipasn_20250523.1600.dat.gz
INFO: loading datfile /root/.cache/pyasn/ipasn_20250523.1600.dat.gz...
INFO: loading /root/.cache/pyasn/asnames.json
ASN count AS
136907 7811 HWCLOUDS-AS-AP HUAWEI CLOUDS, HK
[----] 359 [REDACTED]
[----] 313 [REDACTED]
8075 254 MICROSOFT-CORP-MSN-AS-BLOCK, US
[---] 164 [REDACTED]
[----] 136 [REDACTED]
24940 114 HETZNER-AS, DE
[----] 98 [REDACTED]
14618 82 AMAZON-AES, US
[----] 79 [REDACTED]
prefix count
166.108.192.0/20 1294
188.239.32.0/20 1056
166.108.224.0/20 970
111.119.192.0/20 951
124.243.128.0/18 667
94.74.80.0/20 651
111.119.224.0/20 622
111.119.240.0/20 566
111.119.208.0/20 538
[REDACTED] 313
Even without ratios and a total count (which will come later), it was
quite clear that Huawei was doing something big on the server. At that
point, it was responsible for a quarter to half of the traffic on our
GitLab server or about 5-10 queries per second.
But just looking at the logs, or per IP hit counts, it was really hard
to tell. That traffic is really well distributed. If you look more
closely at the output above, you'll notice I redacted a couple of
entries except major providers, for privacy reasons. But you'll also
notice almost nothing is redacted in the prefix list, why? Because
all of those networks are Huawei! Their announcements are kind of
bonkers: they have hundreds of such prefixes.
Now, clever people in the know will say "of course they do, it's an
hyperscaler; just ASN14618 (AMAZON-AES) there is way more
announcements, they have 1416 prefies!" Yes, of course, but they are
not generating half of my traffic (at least, not yet). But even then:
this also applies to Amazon! This way of counting traffic is way
more useful for large scale operations like this, because you group by
organisation instead of by server or individual endpoint.
And, ultimately, this is why asncounter matters: it allows you to
group your traffic by organisation, the place you can actually
negociate with.
Now, of course, that assumes those are entities you can talk with. I
have written to both Alibaba and Huawei, and have yet to receive a
response. I assume I never will. In their defence, I wrote in English,
perhaps I should have made the effort of translating my message in
Chinese, but then again English is the Lingua Franca of the
Internet, and I doubt that's actually the issue.
The Huawei and Facebook blocks
Another aside, because this is my blog and I am not looking for a
Pullitzer here.
So I blocked Huawei from our GitLab server (and before you tear your
shirt open: only our GitLab server, everything else is still
accessible to them, including our email server to respond to my
complaint). I did so 24h after emailing them, and after examining
their user agent (UA) headers. Boy that was fun. In a sample of 268
requests I analyzed, they churned out 246 different UAs.
At first glance, they looked legit, like:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36
Saferi on a Mac, so far so good. But when you start digging, you
notice some strange things, like here's Safari running on Linux:
Mozilla/5.0 (X11; U; Linux i686; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.457.0 Safari/534.3
Was Safari ported to Linux? I guess that's.. possible?
But here here Safari running on a 15 year old Ubuntu release (10.10):
Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Ubuntu/10.10 Chromium/12.0.702.0 Chrome/12.0.702.0 Safari/534.24
Speaking of old, here's Safari again, but this time running on Windows
NT 5.1, AKA Windows XP, released 2001, EOL since 2019:
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-CA) AppleWebKit/534.13 (KHTML like Gecko) Chrome/9.0.597.98 Safari/534.13
Really?
Here's Firefox 3.6, released 14 years ago, there werequite a lot of
those:
Mozilla/5.0 (Windows; U; Windows NT 6.1; lt; rv:1.9.2) Gecko/20100115 Firefox/3.6
I remember running those old Firefox releases, those were the days.
But to me, those look like entirely fake UAs, deliberately rotated to
make it look like legitimate traffic.
In comparison, Facebook seemed a bit more legit, in the sense that
they don't fake it. most hits are from:
crawls the web for use cases such as training AI models or improving products by indexing content directly
From what I coult tell, it was even respecting our rather liberal
robots.txt rules, in that it wasn't crawling the sprawling /blame/
or /commit/ endpoints, explicitly forbidden by robots.txt.
So I've blocked the Facebook bot in robots.txt and, amazingly, it
just went away. Good job Facebook, as much as I think you've given the
empire to neo-nazis, cause depression and genocide, you know how to
run a crawler, thanks.
Huawei was blocked at the webserver level, with a friendly 429 status
code telling people to contact us (over email) if they need help. And
they don't care: they're still hammering the server, from what I can
tell, but then again, I didn't block the entire ASN just yet, just the
blocks I found crawling the server over a couple hours.
A full asncounter run
So what does a day in asncounter look like? Well, you start with a
problem, say you're getting too much traffic and want to see where
it's from. First you need to sample it. Typically, you'd do that with
tcpdump or tailing a logfile:
If you really get a lot of traffic, you might want to get a subset
of that to avoid overwhelming asncounter, it's not fast enough to do
multiple gigabit/second, I bet, so here's only incoming SYN IPv4
packets:
tcpdump -q -n -Q in "tcp and tcp[tcpflags] & tcp-syn != 0 and (port 80 or port 443)" | asncounter --input-format=tcpdump --repl
In any case, at this point you're staring at a process, just sitting
there. If you passed the --repl or --manhole arguments, you're
lucky: you have a Python shell inside the program. Otherwise, send
SIGHUP to the thing to have it dump the nice tables out:
pkill -HUP asncounter
Here's an example run:
> awk '{print $2}' /var/log/apache2/*access*.log | asncounter
INFO: using datfile ipasn_20250527.1600.dat.gz
INFO: collecting addresses from <stdin>
INFO: loading datfile /home/anarcat/.cache/pyasn/ipasn_20250527.1600.dat.gz...
INFO: finished reading data
INFO: loading /home/anarcat/.cache/pyasn/asnames.json
count percent ASN AS
12779 69.33 66496 SAMPLE, CA
3361 18.23 None None
366 1.99 66497 EXAMPLE, FR
337 1.83 16276 OVH, FR
321 1.74 8075 MICROSOFT-CORP-MSN-AS-BLOCK, US
309 1.68 14061 DIGITALOCEAN-ASN, US
128 0.69 16509 AMAZON-02, US
77 0.42 48090 DMZHOST, GB
56 0.3 136907 HWCLOUDS-AS-AP HUAWEI CLOUDS, HK
53 0.29 17621 CNCGROUP-SH China Unicom Shanghai network, CN
total: 18433
count percent prefix ASN AS
12779 69.33 192.0.2.0/24 66496 SAMPLE, CA
3361 18.23 None
298 1.62 178.128.208.0/20 14061 DIGITALOCEAN-ASN, US
289 1.57 51.222.0.0/16 16276 OVH, FR
272 1.48 2001:DB8::/48 66497 EXAMPLE, FR
235 1.27 172.160.0.0/11 8075 MICROSOFT-CORP-MSN-AS-BLOCK, US
94 0.51 2001:DB8:1::/48 66497 EXAMPLE, FR
72 0.39 47.128.0.0/14 16509 AMAZON-02, US
69 0.37 93.123.109.0/24 48090 DMZHOST, GB
53 0.29 27.115.124.0/24 17621 CNCGROUP-SH China Unicom Shanghai network, CN
Those numbers are actually from my home network, not GitLab. Over
there, the battle still rages on, but at least the vampire bots are
banging their heads against the solid Nginx wall instead of eating the
fragile heart of GitLab. We had a significant improvement in latency
thanks to the Facebook and Huawei blocks... Here are the "workhorse
request duration stats" for various time ranges, 20h after the block:
range
mean
max
stdev
20h
449ms
958ms
39ms
7d
1.78s
5m
14.9s
30d
2.08s
3.86m
8.86s
6m
901ms
27.3s
2.43s
We went from two seconds mean to 500ms! And look at that stdev!
39ms! It was ten seconds before! I doubt we'll keep it that way very
long but for now, it feels like I won a battle, and I didn't even have
to setup anubis or go-away, although I suspect that will
unfortunately come.
Note that asncounter also supports exporting Prometheus metrics, but
you should be careful with this, as it can lead to cardinal explosion,
especially if you track by prefix (which can be disabled with
--no-prefixes.
Folks interested in more details should read the fine manual for
more examples, usage, and discussion. It shows, among other things,
how to effectively block lots of networks from Nginx, aggregate
multiple prefixes, block entire ASNs, and more!
So there you have it: I now have the tool I wish I had 20 years
ago. Hopefully it will stay useful for another 20 years, although I'm
not sure we'll have still have internet in 20
years.
I welcome constructive feedback, "oh no you rewrote X", Grafana
dashboards, bug reports, pull requests, and "hell yeah"
comments. Hacker News, let it rip, I know you can give me another
juicy quote for my blog.
This work was done as part of my paid work for the Tor Project,
currently in a fundraising drive, give us money if you like what you
read.
I previously wrote a blog post Why Clusters Usually Don’t Work [2] and I believe that all the points there are valid today – and possibly exacerbated by clusters getting less direct use as clustering is increasingly being done by hyperscale providers.
Take a basic need, a MySQL or PostgreSQL database for example. You want it to run and basically do the job and to have good recovery options. You could set it up locally, run backups, test the backups, have a recovery plan for failures, maybe have a hot-spare server if it’s really important, have tests for backups and hot-spare server, etc. Then you could have documentation for this so if the person who set it up isn’t available when there’s a problem they will be able to find out what to do. But the hyperscale option is to just select a database in your provider and have all this just work. If the person who set it up isn’t available for recovery in the event of failure the company can just put out a job advert for “person with experience on cloud company X” and have them just immediately go to work on it.
I don’t like hyperscale providers as they are all monopolistic companies that do anti-competitive actions. Google should be broken up, Android development and the Play Store should be separated from Gmail etc which should be separated from search and adverts, and all of them should be separated from the GCP cloud service. Amazon should be broken up, running the Amazon store should be separated from selling items on the store, which should be separated from running a video on demand platform, and all of them should be separated from the AWS cloud. Microsoft should be broken up, OS development should be separated from application development all of that should be separated from cloud services (Teams and Office 365), and everything else should be separate from the Azure cloud system.
But the cloud providers offer real benefits at small scale. Running a MySQL or PostgreSQL database for local services is easy, it’s a simple apt command to install it and then it basically works. Doing backup and recovery isn’t so easy. One could say “just hire competent people” but if you do hire competent people do you want them running MySQL databases etc or have them just click on the “create mysql database” option on a cloud control panel and then move on to more important things?
The Debian packaging of Open Stack looks interesting [4], it’s a complete setup for running your own hyper scale cloud service. For medium and large organisations running Open Stack could be a good approach. But for small organisations it’s cheaper and easier to just use a cloud service to run things.
The issue of when to run things in-house and when to put them in the cloud is very complex. I think that if the organisation is going to spend less money on cloud services than on the salary of one sysadmin then it’s probably best to have things in the cloud. When cloud costs start to exceed the salary of one person who manages systems then having them spend the extra time and effort to run things locally starts making more sense. There is also an opportunity cost in having a good sysadmin work on the backups for all the different systems instead of letting the cloud provider just do it. Another possibility of course is to run things in-house on low end hardware and just deal with the occasional downtime to save money. Knowingly choosing less reliability to save money can be quite reasonable as long as you have considered the options and all the responsible people are involved in the discussion.
The one situation that I strongly oppose is having hyper scale services setup by people who don’t understand them. Running a database server on a cloud service because you don’t want to spend the time managing it is a reasonable choice in many situations. Running a database server on a cloud service because you don’t understand how to setup a database server is never a good choice. While the cloud services are quite resilient there are still ways of breaking the overall system if you don’t understand it. Also while it is quite possible for someone to know how to develop for databases including avoiding SQL injection etc but be unable to setup a database server that’s probably not going to be common, probably if someone can’t set it up (a generally easy task) then they can’t do the hard tasks of making it secure.
High-roller
Matthew D.
fears Finance.
"This is from our corporate expense system. Will they flag my expenses in the April-December quarter as too high? And do we really need a search function for a list of 12 items?"
Tightfisted
Adam R.
begrudges a trifling sum.
"The tipping culture is getting out of hand. After I chose 'Custom Tip'
for some takeout, they filled out the default tip with a few extra femtocents. What a rip!"
Cool Customer
Reinier B.
sums this up:
"I got some free B&J icecream a while back. Since one of them was
priced at €0.01, the other one obviously had to cost zero
point minus 1 euros to make a total of zero euro. Makes sense. Or
probably not."
An anonymous browniedad is ready to pack his poptart off for the summer.
"I know {First Name} is really excited for camp..."
Kudos on getting Mom to agree to that name choice!
Finally, another anonymous assembler's retrospective visualisation.
"CoPilot rendering a graphical answer of the semantics of a pointer.
Point taken. "
There's no error'd
here really, but I'm wondering how long before this kind of
wtf illustration lands somewhere "serious".
[Advertisement]
Keep the plebs out of prod. Restrict NuGet feed privileges with ProGet. Learn more.
This approach of having 2 AI systems where one processes user input and the second performs actions on quarantined data is good and solves some real problems. But I think the bigger issue is the need to do this. Why not have a multi stage approach, instead of a single user input to do everything (the example given is “Can you send Bob the document he requested in our last meeting? Bob’s email and the document he asked for are in the meeting notes file”) you could have “get Bob’s email address from the meeting notes file” followed by “create a new email to that address” and “find the document” etc.
A major problem with many plans for ML systems is that they are based around automating relatively simple tasks. The example of sending an email based on meeting notes is a trivial task that’s done many times a day but for which expressing it verbally isn’t much faster than doing it the usual way. The usual way of doing such things (manually finding the email address from the meeting notes etc) can be accelerated without ML by having a “recent documents” access method that gets the notes, having the email address be a hot link to the email program (IE wordprocessor or note taking program being able to call the MUA), having a “put all data objects of type X into the clipboard (where X can be email address, URL, filename, or whatever), and maybe optimising the MUA UI. The problems that people are talking about solving via ML and treating everything as text to be arbitrarily parsed can in many cases by solved by having the programs dealing with the data know what they have and have support for calling system services accordingly.
The blog post suggests a problem of “user fatigue” from asking the user to confirm all actions, that is a real concern if the system is going to automate everything such that the user gives a verbal description of the problem and then says “yes” many times to confirm it. But if the user is at every step of the way pushing the process “take this email address” “attach this file” it won’t be a series of “yes” operations with a risk of saying “yes” once too often.
I think that one thing that should be investigated is better integration between services to allow working live on data. If in an online meeting someone says “I’ll work on task A please send me an email at the end of the meeting with all issues related to it” then you should be able to click on their email address in the meeting software to bring up the MUA to send a message and then just paste stuff in. The user could then not immediately send the message and clicking on the email address again would bring up the message in progress to allow adding to it (the behaviour of most MUAs of creating a new message for every click on a mailto:// URL is usually not what you desire). In this example you could of course use ALT-TAB or other methods to switch windows to the email, but imagine the situation of having 5 people in the meeting who are to be emailed about different things and that wouldn’t scale.
Another thing for the meeting example is that having a text chat for a video conference is a standard feature now and being able to directly message individuals is available in BBB and probably some other online meeting systems. It shouldn’t be hard to add a feature to BBB and similar programs to have each user receive an email at the end of the meeting with the contents of every DM chat they were involved in and have everyone in the meeting receive an emailed transcript of the public chat.
In conclusion I think that there are real issues with ML security and something like this technology is needed. But for most cases the best option is to just not have ML systems do such things. Also there is significant scope for improving the integration of various existing systems in a non-ML way.
Author: David C. Nutt It was an alien invasion, not in the sense of “War of the Worlds” but more like what historians called the “British Invasion” but without the Beatles. What invaded us was close to five million overprivileged alien tourists, all here for one reason: to inhale us. No, this is no metaphor. […]
The U.S. government today imposed economic sanctions on Funnull Technology Inc., a Philippines-based company that provides computer infrastructure for hundreds of thousands of websites involved in virtual currency investment scams known as “pig butchering.” In January 2025, KrebsOnSecurity detailed how Funnull was being used as a content delivery network that catered to cybercriminals seeking to route their traffic through U.S.-based cloud providers.
“Americans lose billions of dollars annually to these cyber scams, with revenues generated from these crimes rising to record levels in 2024,” reads a statement from the U.S. Department of the Treasury, which sanctioned Funnull and its 40-year-old Chinese administrator Liu Lizhi. “Funnull has directly facilitated several of these schemes, resulting in over $200 million in U.S. victim-reported losses.”
The Treasury Department said Funnull’s operations are linked to the majority of virtual currency investment scam websites reported to the FBI. The agency said Funnull directly facilitated pig butchering and other schemes that resulted in more than $200 million in financial losses by Americans.
Pig butchering is a rampant form of fraud wherein people are lured by flirtatious strangers online into investing in fraudulent cryptocurrency trading platforms. Victims are coached to invest more and more money into what appears to be an extremely profitable trading platform, only to find their money is gone when they wish to cash out.
The scammers often insist that investors pay additional “taxes” on their crypto “earnings” before they can see their invested funds again (spoiler: they never do), and a shocking number of people have lost six figures or more through these pig butchering scams.
KrebsOnSecurity’s January story on Funnull was based on research from the security firm Silent Push, which discovered in October 2024 that a vast number of domains hosted via Funnull were promoting gambling sites that bore the logo of the Suncity Group, a Chinese entity named in a 2024 UN report (PDF) for laundering millions of dollars for the North Korean state-sponsored hacking group Lazarus.
Silent Push found Funnull was a criminal content delivery network (CDN) that carried a great deal of traffic tied to scam websites, funneling the traffic through a dizzying chain of auto-generated domain names and U.S.-based cloud providers before redirecting to malicious or phishous websites. The FBI has released a technical writeup (PDF) of the infrastructure used to manage the malicious Funnull domains between October 2023 and April 2025.
A graphic from the FBI explaining how Funnull generated a slew of new domains on a regular basis and mapped them to Internet addresses on U.S. cloud providers.
Silent Push revisited Funnull’s infrastructure in January 2025 and found Funnull was still using many of the same Amazon and Microsoft cloud Internet addresses identified as malicious in its October report. Both Amazon and Microsoft pledged to rid their networks of Funnull’s presence following that story, but according to Silent Push’s Zach Edwards only one of those companies has followed through.
Edwards said Silent Push no longer sees Microsoft Internet addresses showing up in Funnull’s infrastructure, while Amazon continues to struggle with removing Funnull servers, including one that appears to have first materialized in 2023.
“Amazon is doing a terrible job — every day since they made those claims to you and us in our public blog they have had IPs still mapped to Funnull, including some that have stayed mapped for inexplicable periods of time,” Edwards said.
Amazon said its Amazon Web Services (AWS) hosting platform actively counters abuse attempts.
“We have stopped hundreds of attempts this year related to this group and we are looking into the information you shared earlier today,” reads a statement shared by Amazon. “If anyone suspects that AWS resources are being used for abusive activity, they can report it to AWS Trust & Safety using the report abuse form here.”
U.S. based cloud providers remain an attractive home base for cybercriminal organizations because many organizations will not be overly aggressive in blocking traffic from U.S.-based cloud networks, as doing so can result in blocking access to many legitimate web destinations that are also on that same shared network segment or host.
What’s more, funneling their bad traffic so that it appears to be coming out of U.S. cloud Internet providers allows cybercriminals to connect to websites from web addresses that are geographically close(r) to their targets and victims (to sidestep location-based security controls by your bank, for example).
Funnull is not the only cybercriminal infrastructure-as-a-service provider that was sanctioned this month: On May 20, 2025, the European Unionimposed sanctions on Stark Industries Solutions, an ISP that materialized at the start of Russia’s invasion of Ukraine and has been used as a global proxy network that conceals the true source of cyberattacks and disinformation campaigns against enemies of Russia.
In May 2024, KrebsOnSecurity published a deep dive on Stark Industries Solutions that found much of the malicious traffic traversing Stark’s network (e.g. vulnerability scanning and password brute force attacks) was being bounced through U.S.-based cloud providers. My reporting showed how deeply Stark had penetrated U.S. ISPs, and that its co-founder for many years sold “bulletproof” hosting services that told Russian cybercrime forum customers they would proudly ignore any abuse complaints or police inquiries.
The homepage of Stark Industries Solutions.
That story examined the history of Stark’s co-founders, Moldovan brothers Ivan and Yuri Neculiti, who each denied past involvement in cybercrime or any current involvement in assisting Russian disinformation efforts or cyberattacks. Nevertheless, the EU sanctioned both brothers as well.
The EU said Stark and the Neculti brothers “enabled various Russian state-sponsored and state-affiliated actors to conduct destabilising activities including coordinated information manipulation and interference and cyber-attacks against the Union and third countries by providing services intended to hide these activities from European law enforcement and security agencies.”
Being the opening talk, we were still sorting out projector issues
when I started so I forgot to set a timer, and consequently ran out of
time like a newbie. It occured to me that I could simply re-record the
talk in front of my slides just as I do for my STAT 447 students. So I sat down this
morning and did this, and the video is now online:
RcppDate wraps
the featureful date
library written by Howard
Hinnant for use with R. This header-only modern C++ library has been
in pretty wide-spread use for a while now, and adds to C++11/C++14/C++17
what will is (with minor modifications) the ‘date’ library in C++20. The
RcppDate package
adds no extra R or C++ code and can therefore be a zero-cost dependency
for any other project; yet a number of other projects decided to
re-vendor it resulting in less-efficient duplication. Oh well. C’est
la vie.
This release syncs with upstream release 3.0.4 made yesterday which
contains a few PRs (including one by us) for
the clang++-20 changes some of which we already had in release
0.0.5. We also made a routine update to the continuous
integration.
There’s a new cybersecurity awareness campaign: Take9. The idea is that people—you, me, everyone—should just pause for nine seconds and think more about the link they are planning to click on, the file they are planning to download, or whatever it is they are planning to share.
There’s a website—of course—and a video, well-produced and scary. But the campaign won’t do much to improve cybersecurity. The advice isn’t reasonable, it won’t make either individuals or nations appreciably safer, and it deflects blame from the real causes of our cyberspace insecurities.
First, the advice is not realistic. A nine-second pause is an eternity in something as routine as using your computer or phone. Try it; use a timer. Then think about how many links you click on and how many things you forward or reply to. Are we pausing for nine seconds after every text message? Every Slack ping? Does the clock reset if someone replies midpause? What about browsing—do we pause before clicking each link, or after every page loads? The logistics quickly become impossible. I doubt they tested the idea on actual users.
Second, it largely won’t help. The industry should know because we tried it a decade ago. “Stop. Think. Connect.” was an awarenesscampaign from 2016, by the Department of Homeland Security—this was before CISA—and the National Cybersecurity Alliance. The message was basically the same: Stop and think before doing anything online. It didn’t work then, either.
Take9’s website says, “Science says: In stressful situations, wait 10 seconds before responding.” The problem with that is that clicking on a link is not a stressful situation. It’s normal, one that happens hundreds of times a day. Maybe you can train a person to count to 10 before punching someone in a bar but not before opening an attachment.
And there is no basis in science for it. It’s a folk belief, all over the Internet but with no actual research behind it—like the five-second rule when you drop food on the floor. In emotionally charged contexts, most people are already overwhelmed, cognitively taxed, and not functioning in a space where rational interruption works as neatly as this advice suggests.
Pausing Adds Little
Pauses help us break habits. If we are clicking, sharing, linking, downloading, and connecting out of habit, a pause to break that habit works. But the problem here isn’t habit alone. The problem is that people aren’t able to differentiate between something legitimate and an attack.
The Take9 website says that nine seconds is “time enough to make a better decision,” but there’s no use telling people to stop and think if they don’t know what to think about after they’ve stopped. Pause for nine seconds and… do what? Take9 offers no guidance. It presumes people have the cognitive tools to understand the myriad potential attacks and figure out which one of the thousands of Internet actions they take is harmful. If people don’t have the right knowledge, pausing for longer—even a minute—will do nothing to add knowledge.
The three-part suspicion, cognition, and automaticity model (SCAM) is one way to think about this. The first is lack of knowledge—not knowing what’s risky and what isn’t. The second is habits: people doing what they always do. And third, using flawed mental shortcuts, like believing PDFs to be safer than Microsoft Word documents, or that mobile devices are safer than computers for opening suspicious emails.
These pathways don’t always occur in isolation; sometimes they happen together or sequentially. They can influence each other or cancel each other out. For example, a lack of knowledge can lead someone to rely on flawed mental shortcuts, while those same shortcuts can reinforce that lack of knowledge. That’s why meaningful behavioral change requires more than just a pause; it needs cognitive scaffolding and system designs that account for these dynamic interactions.
A successful awareness campaign would do more than tell people to pause. It would guide them through a two-step process. First trigger suspicion, motivating them to look more closely. Then, direct their attention by telling them what to look at and how to evaluate it. When both happen, the person is far more likely to make a better decision.
This means that pauses need to be context specific. Think about email readers that embed warnings like “EXTERNAL: This email is from an address outside your organization” or “You have not received an email from this person before.” Those are specifics, and useful. We could imagine an AI plug-in that warns: “This isn’t how Bruce normally writes.” But of course, there’s an arms race in play; the bad guys will use these systems to figure out how to bypass them.
This is all hard. The old cues aren’t there anymore. Current phishing attacks have evolved from those older Nigerian scams filled with grammar mistakes and typos. Text message, voice, or video scams are even harder to detect. There isn’t enough context in a text message for the system to flag. In voice or video, it’s much harder to trigger suspicion without disrupting the ongoing conversation. And all the false positives, when the system flags a legitimate conversation as a potential scam, work against people’s own intuition. People will just start ignoring their own suspicions, just as most people ignore all sorts of warnings that their computer puts in their way.
Even if we do this all well and correctly, we can’t make people immune to social engineering. Recently, both cyberspace activist Cory Doctorow and security researcher Troy Hunt—two people who you’d expect to be excellent scam detectors—got phished. In both cases, it was just the right message at just the right time.
It’s even worse if you’re a large organization. Security isn’t based on the average employee’s ability to detect a malicious email; it’s based on the worst person’s inability—the weakest link. Even if awareness raises the average, it won’t help enough.
Don’t Place Blame Where It Doesn’t Belong
Finally, all of this is bad public policy. The Take9 campaign tells people that they can stop cyberattacks by taking a pause and making a better decision. What’s not said, but certainly implied, is that if they don’t take that pause and don’t make those better decisions, then they’re to blame when the attack occurs.
That’s simply not true, and its blame-the-user message is one of the worst mistakes our industry makes. Stop trying to fix the user. It’s not the user’s fault if they click on a link and it infects their system. It’s not their fault if they plug in a strange USB drive or ignore a warning message that they can’t understand. It’s not even their fault if they get fooled by a look-alike bank website and lose their money. The problem is that we’ve designed these systems to be so insecure that regular, nontechnical people can’t use them with confidence. We’re using security awareness campaigns to cover up bad system design. Or, as security researcher Angela Sasse first said in 1999: “Users are not the enemy.”
We wouldn’t accept that in other parts of our lives. Imagine Take9 in other contexts. Food service: “Before sitting down at a restaurant, take nine seconds: Look in the kitchen, maybe check the temperature of the cooler, or if the cooks’ hands are clean.” Aviation: “Before boarding a plane, take nine seconds: Look at the engine and cockpit, glance at the plane’s maintenance log, ask the pilots if they feel rested.” This is obviously ridiculous advice. The average person doesn’t have the training or expertise to evaluate restaurant or aircraft safety—and we don’t expect them to. We have laws and regulations in place that allow people to eat at a restaurant or board a plane without worry.
But—we get it—the government isn’t going to step in and regulate the Internet. These insecure systems are what we have. Security awareness training, and the blame-the-user mentality that comes with it, are all we have. So if we want meaningful behavioral change, it needs a lot more than just a pause. It needs cognitive scaffolding and system designs that account for all the dynamic interactions that go into a decision to click, download, or share. And that takes real work—more work than just an ad campaign and a slick video.
This essay was written with Arun Vishwanath, and originally appeared in Dark Reading.
Nina's team has a new developer on the team. They're not a junior developer, though Nina wishes they could replace this developer with a junior. Inexperience is better than whatever this Java code is.
We start by casting options into an array of Objects. That's already a code stench, but we actually don't even use the test variable and instead just redo the cast multiple times.
But worse than that, we cast to an array of object, access an element, and then cast that element to a collection type. I do not know what is in the options variable, but based on how it gets used, I don't like it. What it seems to be is a class (holding different options as fields) rendered as an array (holding different options as elements).
The new developer (ab)uses this pattern everywhere.
[Advertisement]
ProGet’s got you covered with security and access controls on your NuGet feeds. Learn more.
Author: K. Andrus Where was the best place to murder someone and get away with it? A question that had been fun to ponder, back when Albert had been at home accompanied by nobody else but a chilled glass of scotch, the comforting roar of a June snowstorm, and his most recent work-in-progress novel. Yet […]
Debian 13 "Trixie" full freeze has started 2025-05-17, so this is
a good time to take a look at some of the features, that this release
will bring. Here we will focus on packages related to XMPP, a.k.a.
Jabber.
XMPP is a universal communication protocol for instant messaging, push
notifications, IoT, WebRTC, and social applications. It has existed since
1999, originally called "Jabber", it has a diverse and active developers
community.
Clients
Dino, a modern XMPP client has been upgraded from 0.4.2 to
0.5.0
Dino now uses OMEMO encryption by default. It also supports
XEP-0447: Stateless File Sharing for unencrypted file
transfers. Users can now see preview images or other file details
before downloading the file. Multiple widgets are redesigned to be
compatible with mobile devices, e.g. running Mobian.
Kaidan, a simple and user-friendly Jabber/XMPP client is
upgraded from 0.8.0 to 0.12.2
Kaidan supports end-to-end encryption via OMEMO 2, Automatic Trust
Management and XMPP Providers. It has been migrated
to QT 6 and many features have been added: XEP-0444: Message
Reactions, XEP-0461: Message Replies,
chat pinning, inline audio player, chat list filtering, local
message removal, etc.
Libervia is upgraded from 0.9.0~hg3993 to
0.9.0~hg4352
Among other features, it now also contains a gateway to ActivityPub,
e.g. to Mastodon.
Poezio, a console based XMPP client as been updated from 0.14
to 0.15.0
Better self-ping support. Use the system CA store by default.
Profanity, a console based XMPP client has been
upgraded from 0.13.1 to 0.15.0.
Add support for XEP-0054: vcard-temp, Improve MAM
support, show encryption for messages from history and handle alt+enter
as newline char.
Psi+, a QT based XMPP client (basic version) has been
upgraded from 1.4.554 to 1.4.1456
Prosŏdy, a lightweight extensible XMPP server has been
upgraded from 0.12.3 to 13.0.1
Admins can disable and enable accounts as needed. A new
role and permissions framework. Storage and performance improvements.
libstrophe, an XMPP library in C has been upgraded from 0.12.2 to
0.14.0
It now supports XEP-0138: Stream Compression and
adds various modern SCRAM mechanisms.
omemo-dr, an OMEMO library used by Gajim is now in
Debian, in version 1.0.1
python-nbxmpp, a non blocking Jabber/XMPP Python 3 library, upgrade
from 4.2.2 to 6.1.1
python-oldmemo, a python-omemo backend for OMEMO 1, 1.0.3 to 1.1.0
python-omemo, a Python 3 implementation of the OMEMO protocol, 1.0.2
to 1.2.0
python-twomemo, a python-omemo backend for OMEMO 2, 1.0.3 to 1.1.0
strophejs, a library for writing XMPP clients has been upgraded from
1.2.14 to 3.1.0
Gateways/Transports
Biboumi, a gateway between XMPP and IRC, upgrades from
9.0 to 9.0+20241124.
Debian 13 Trixie includes Slidge 0.2.12 and
Matridge 0.2.3 for the first time! It is a
gateway between XMPP and Matrix, with support for many chat
features.
Not in Trixie
Spectrum 2, a gateway from XMPP to various other
messaging systems, did not make it into Debian 13, because it
depends on Swift, which has release critical bugs and
therefore cannot be part of a stable release.
I’ve been part of the Debian Project since 2019, when I attended DebConf held in Curitiba, Brazil. That event sparked my interest in the community, packaging, and how Debian works as a distribution.
In the early years of my involvement, I contributed to various teams such as the Python, Golang and Cloud teams, packaging dependencies and maintaining various tools. However, I soon felt the need to focus on packaging software I truly enjoyed, tools I was passionate about using and maintaining.
That’s when I turned my attention to Kubernetes within Debian.
A Broken Ecosystem
The Kubernetes packaging situation in Debian had been problematic for some time. Given its large codebase and complex dependency tree, the initial packaging approach involved vendorizing all dependencies. While this allowed a somewhat functional package to be published, it introduced several long-term issues, especially security concerns.
Vendorized packages bundle third-party dependencies directly into the source tarball. When vulnerabilities arise in those dependencies, it becomes difficult for Debian’s security team to patch and rebuild affected packages system-wide. This approach broke Debian’s best practices, and it eventually led to the abandonment of the Kubernetes source package, which had stalled at version 1.20.5.
Due to this abandonment, critical bugs emerged and the package was removed from Debian’s testing channel, as we can see in the package tracker.
New Debian Kubernetes Team
Around this time, I became a Debian Maintainer (DM), with permissions to upload certain packages. I saw an opportunity to both contribute more deeply to Debian and to fix Kubernetes packaging.
In early 2024, just before DebConf Busan in South Korea, I founded the Debian Kubernetes Team. The mission of the team was to repackage Kubernetes in a maintainable, security-conscious, and Debian-compliant way. At DebConf, I shared our progress with the broader community and received great feedback and more visibility, along with people interested in contributing to the team.
Our first tasks was to migrate existing Kubernetes-related tools such as kubectx, kubernetes-split-yaml and kubetail into a dedicated namespace on Salsa, Debian’s GitLab instance.
Many of these tools were stored across different teams (like the Go team), and consolidating them helped us organize development and focus our efforts.
De-vendorizing Kubernetes
Our main goal was to un-vendorize Kubernetes and bring it up-to-date with upstream releases.
This meant:
Removing the vendor directory and all embedded third-party code.
Trimming the build scope to focus solely on building kubectl, Kubernetes’ CLI.
Using Files-Excluded in debian/copyright to cleanly drop unneeded files during source imports.
Rebuilding the dependency tree, ensuring all Go modules were separately packaged in Debian.
We used uscan, a standard Debian packaging tool that fetches upstream tarballs and prepares them accordingly. The Files-Excluded directive in our debian/copyright file instructed uscan to automatically remove unnecessary files during the repackaging process:
$ uscan
Newest version of kubernetes on remote site is 1.32.3, specified download version is 1.32.3
Successfully repacked ../v1.32.3 as ../kubernetes_1.32.3+ds.orig.tar.gz, deleting 30616 files from it.
The results were dramatic. By comparing the original upstream tarball with our repackaged version, we can see that our approach reduced the tarball size by over 75%:
This significant reduction wasn’t just about saving space. By removing over 30,000 files, we simplified the package, making it more maintainable. Each dependency could now be properly tracked, updated, and patched independently, resolving the security concerns that had plagued the previous packaging approach.
Dependency Graph
To give you an idea of the complexity involved in packaging Kubernetes for Debian, the image below is a dependency graph generated with debtree, visualizing all the Go modules and other dependencies required to build the kubectl binary.
This web of nodes and edges represents every module and its relationship during the compilation process of kubectl. Each box is a Debian package, and the lines connecting them show how deeply intertwined the ecosystem is. What might look like a mess of blue spaghetti is actually a clear demonstration of the vast and interconnected upstream world that tools like kubectl rely on.
But more importantly, this graph is a testament to the effort that went into making kubectl build entirely using Debian-packaged dependencies only, no vendoring, no downloading from the internet, no proprietary blobs.
Upstream Version 1.32.3 and Beyond
After nearly two years of work, we successfully uploaded version 1.32.3+ds of kubectl to Debian unstable.
Zsh, Fish, and Bash completions installed automatically
Man pages and metadata for improved discoverability
Full integration with kind and docker for testing purposes
Integration Testing with Autopkgtest
To ensure the reliability of kubectl in real-world scenarios, we developed a new autopkgtest suite that runs integration tests using real Kubernetes clusters created via Kind.
Autopkgtest is a Debian tool used to run automated tests on binary packages. These tests are executed after the package is built but before it’s accepted into the Debian archive, helping catch regressions and integration issues early in the packaging pipeline.
Our test workflow validates kubectl by performing the following steps:
Installing Kind and Docker as test dependencies.
Spinning up two local Kubernetes clusters.
Switching between cluster contexts to ensure multi-cluster support.
Deploying and scaling a sample nginx application using kubectl.
Cleaning up the entire test environment to avoid side effects.
To measure real-world usage, we rely on data from Debian’s popularity contest (popcon), which gives insight into how many users have each binary installed.
Here’s what the data tells us:
kubectl (new binary): Already installed on 2,124 systems.
golang-k8s-kubectl-dev: This is the Go development package (a library), useful for other packages and developers who want to interact with Kubernetes programmatically.
kubernetes-client: The legacy package that kubectl is replacing. We expect this number to decrease in future releases as more systems transition to the new package.
Although the popcon data shows activity for kubectl before the official Debian upload date, it’s important to note that those numbers represent users who had it installed from upstream source-lists, not from the Debian repositories. This distinction underscores a demand that existed even before the package was available in Debian proper, and it validates the importance of bringing it into the archive.
Also worth mentioning: this number is not the real total number of installations, since users can choose not to participate in the popularity contest. So the actual adoption is likely higher than what popcon reflects.
Community and Documentation
The team also maintains a dedicated wiki page which documents:
The next stable release of Debian will ship with kubectl version 1.32.3, built from a clean, de-vendorized source. This version includes nearly all the latest upstream features, and will be the first time in years that Debian users can rely on an up-to-date, policy-compliant kubectl directly from the archive.
By comparing with upstream, our Debian package even delivers more out of the box, including shell completions, which the upstream still requires users to generate manually.
In 2025, the Debian Kubernetes team will continue expanding our packaging efforts for the Kubernetes ecosystem.
Our roadmap includes:
kubelet: The primary node agent that runs on each node. This will enable Debian users to create fully functional Kubernetes nodes without relying on external packages.
kubeadm: A tool for creating Kubernetes clusters. With kubeadm in Debian, users will then be able to bootstrap minimum viable clusters directly from the official repositories.
helm: The package manager for Kubernetes that helps manage applications through Kubernetes YAML files defined as charts.
kompose: A conversion tool that helps users familiar with docker-compose move to Kubernetes by translating Docker Compose files into Kubernetes resources.
Final Thoughts
This journey was only possible thanks to the amazing support of the debian-devel-br community and the collective effort of contributors who stepped up to package missing dependencies, fix bugs, and test new versions.
Special thanks to:
Carlos Henrique Melara (@charles)
Guilherme Puida (@puida)
João Pedro Nobrega (@jnpf)
Lucas Kanashiro (@kanashiro)
Matheus Polkorny (@polkorny)
Samuel Henrique (@samueloph)
Sergio Cipriano (@cipriano)
Sergio Durigan Junior (@sergiodj)
I look forward to continuing this work, bringing more Kubernetes tools into Debian and improving the developer experience for everyone.
I’ve been part of the Debian Project since 2019, when I attended DebConf held in Curitiba, Brazil. That event sparked my interest in the community, packaging, and how Debian works as a distribution.
In the early years of my involvement, I contributed to various teams such as the Python, Golang and Cloud teams, packaging dependencies and maintaining various tools. However, I soon felt the need to focus on packaging software I truly enjoyed, tools I was passionate about using and maintaining.
That’s when I turned my attention to Kubernetes within Debian.
A Broken Ecosystem
The Kubernetes packaging situation in Debian had been problematic for some time. Given its large codebase and complex dependency tree, the initial packaging approach involved vendorizing all dependencies. While this allowed a somewhat functional package to be published, it introduced several long-term issues, especially security concerns.
Vendorized packages bundle third-party dependencies directly into the source tarball. When vulnerabilities arise in those dependencies, it becomes difficult for Debian’s security team to patch and rebuild affected packages system-wide. This approach broke Debian’s best practices, and it eventually led to the abandonment of the Kubernetes source package, which had stalled at version 1.20.5.
Due to this abandonment, critical bugs emerged and the package was removed from Debian’s testing channel, as we can see in the package tracker.
New Debian Kubernetes Team
Around this time, I became a Debian Maintainer (DM), with permissions to upload certain packages. I saw an opportunity to both contribute more deeply to Debian and to fix Kubernetes packaging.
In early 2024, just before DebConf Busan in South Korea, I founded the Debian Kubernetes Team. The mission of the team was to repackage Kubernetes in a maintainable, security-conscious, and Debian-compliant way. At DebConf, I shared our progress with the broader community and received great feedback and more visibility, along with people interested in contributing to the team.
Our first tasks was to migrate existing Kubernetes-related tools such as kubectx, kubernetes-split-yaml and kubetail into a dedicated namespace on Salsa, Debian’s GitLab instance.
Many of these tools were stored across different teams (like the Go team), and consolidating them helped us organize development and focus our efforts.
De-vendorizing Kubernetes
Our main goal was to un-vendorize Kubernetes and bring it up-to-date with upstream releases.
This meant:
Removing the vendor directory and all embedded third-party code.
Trimming the build scope to focus solely on building kubectl, Kubernetes’ CLI.
Using Files-Excluded in debian/copyright to cleanly drop unneeded files during source imports.
Rebuilding the dependency tree, ensuring all Go modules were separately packaged in Debian.
We used uscan, a standard Debian packaging tool that fetches upstream tarballs and prepares them accordingly. The Files-Excluded directive in our debian/copyright file instructed uscan to automatically remove unnecessary files during the repackaging process:
$ uscan
Newest version of kubernetes on remote site is 1.32.3, specified download version is 1.32.3
Successfully repacked ../v1.32.3 as ../kubernetes_1.32.3+ds.orig.tar.gz, deleting 30616 files from it.
The results were dramatic. By comparing the original upstream tarball with our repackaged version, we can see that our approach reduced the tarball size by over 75%:
This significant reduction wasn’t just about saving space. By removing over 30,000 files, we simplified the package, making it more maintainable. Each dependency could now be properly tracked, updated, and patched independently, resolving the security concerns that had plagued the previous packaging approach.
Dependency Graph
To give you an idea of the complexity involved in packaging Kubernetes for Debian, the image below is a dependency graph generated with debtree, visualizing all the Go modules and other dependencies required to build the kubectl binary.
This web of nodes and edges represents every module and its relationship during the compilation process of kubectl. Each box is a Debian package, and the lines connecting them show how deeply intertwined the ecosystem is. What might look like a mess of blue spaghetti is actually a clear demonstration of the vast and interconnected upstream world that tools like kubectl rely on.
But more importantly, this graph is a testament to the effort that went into making kubectl build entirely using Debian-packaged dependencies only, no vendoring, no downloading from the internet, no proprietary blobs.
Upstream Version 1.32.3 and Beyond
After nearly two years of work, we successfully uploaded version 1.32.3+ds of kubectl to Debian unstable.
Zsh, Fish, and Bash completions installed automatically
Man pages and metadata for improved discoverability
Full integration with kind and docker for testing purposes
Integration Testing with Autopkgtest
To ensure the reliability of kubectl in real-world scenarios, we developed a new autopkgtest suite that runs integration tests using real Kubernetes clusters created via Kind.
Autopkgtest is a Debian tool used to run automated tests on binary packages. These tests are executed after the package is built but before it’s accepted into the Debian archive, helping catch regressions and integration issues early in the packaging pipeline.
Our test workflow validates kubectl by performing the following steps:
Installing Kind and Docker as test dependencies.
Spinning up two local Kubernetes clusters.
Switching between cluster contexts to ensure multi-cluster support.
Deploying and scaling a sample nginx application using kubectl.
Cleaning up the entire test environment to avoid side effects.
To measure real-world usage, we rely on data from Debian’s popularity contest (popcon), which gives insight into how many users have each binary installed.
Here’s what the data tells us:
kubectl (new binary): Already installed on 2,124 systems.
golang-k8s-kubectl-dev: This is the Go development package (a library), useful for other packages and developers who want to interact with Kubernetes programmatically.
kubernetes-client: The legacy package that kubectl is replacing. We expect this number to decrease in future releases as more systems transition to the new package.
Although the popcon data shows activity for kubectl before the official Debian upload date, it’s important to note that those numbers represent users who had it installed from upstream source-lists, not from the Debian repositories. This distinction underscores a demand that existed even before the package was available in Debian proper, and it validates the importance of bringing it into the archive.
Also worth mentioning: this number is not the real total number of installations, since users can choose not to participate in the popularity contest. So the actual adoption is likely higher than what popcon reflects.
Community and Documentation
The team also maintains a dedicated wiki page which documents:
The next stable release of Debian will ship with kubectl version 1.32.3, built from a clean, de-vendorized source. This version includes nearly all the latest upstream features, and will be the first time in years that Debian users can rely on an up-to-date, policy-compliant kubectl directly from the archive.
By comparing with upstream, our Debian package even delivers more out of the box, including shell completions, which the upstream still requires users to generate manually.
In 2025, the Debian Kubernetes team will continue expanding our packaging efforts for the Kubernetes ecosystem.
Our roadmap includes:
kubelet: The primary node agent that runs on each node. This will enable Debian users to create fully functional Kubernetes nodes without relying on external packages.
kubeadm: A tool for creating Kubernetes clusters. With kubeadm in Debian, users will then be able to bootstrap minimum viable clusters directly from the official repositories.
helm: The package manager for Kubernetes that helps manage applications through Kubernetes YAML files defined as charts.
kompose: A conversion tool that helps users familiar with docker-compose move to Kubernetes by translating Docker Compose files into Kubernetes resources.
Final Thoughts
This journey was only possible thanks to the amazing support of the debian-devel-br community and the collective effort of contributors who stepped up to package missing dependencies, fix bugs, and test new versions.
Special thanks to:
Carlos Henrique Melara (@charles)
Guilherme Puida (@puida)
João Pedro Nobrega (@jnpf)
Lucas Kanashiro (@kanashiro)
Matheus Polkorny (@polkorny)
Samuel Henrique (@samueloph)
Sergio Cipriano (@cipriano)
Sergio Durigan Junior (@sergiodj)
I look forward to continuing this work, bringing more Kubernetes tools into Debian and improving the developer experience for everyone.
I've been working on a multi-label email classification model.
It's been a frustrating slog, fraught with challenges, including
a lack of training data. Labeling emails is labor-intensive and
error-prone. Also, I habitually delete certain classes of email
immediately after its usefulness has been reduced. I use a
CRM-114-based spam filtering system (actually I use two
different isntances of the same mailreaver config, but that's
another story), which is differently frustrating, but I
delete spam when it's detected or when it's trained.
Fortunately, there's no shortage of incoming spam, so I can
collect enough, but for other, arguably more important labels,
they arrive infrequently. So, those labels need to be excluded,
or the small sample sizes wreck the training feedback loop.
Currently, I have ten active labels, and even though the point
of this is not to be a spam filter, “spam” is one of the labels.
Out of curiosity, I decided to compare the performance of
my three different models, and to do so on a neutral corpus
(in other words, emails that none of them had ever been
trained on). I grabbed the full TREC 2007 corpus and ran
inference. The results were unexpected in many ways. For
example, the Pearson correlation coefficient between my
older CRM-114 model and my newer CRM-114 was only about
0.78.
I was even more surprised by how poorly all three performed.
Were they overfit to my email? So, I decided to look at
the TREC corpus for the first time, and lo and behold, the
first spam-labeled email I checked was something I would
definitely train all three models with as non-spam, but
ham for CRM-114 and an entirely different label for my
experimental model.
I've been refreshing myself on the low-level guts of Linux
container technology. Here's some notes on mount namespaces.
In the below examples, I will use more than one root shell
simultaneously. To disambiguate them, the examples will feature
a numbered shell prompt: 1# for the first shell, and 2# for
the second.
Preliminaries
Namespaces are normally associated with processes and are
removed when the last associated process terminates. To make
them persistent, you have to bind-mount the corresponding
virtual file from an associated processes's entry in /proc,
to another path1.
The receiving path needs to have its "propogation" property set to "private".
Most likely your system's existing mounts are mostly "public". You can check
the propogation setting for mounts with
1# findmnt -o+PROPAGATION
We'll create a new directory to hold mount namespaces we create,
and set its Propagation to private, via a bind-mount of itself
to itself.
1# mkdir /root/mntns
1# mount --bind --make-private /root/mntns /root/mntns
The namespace itself needs to be bind-mounted over a file rather
than a directory, so we'll create one.
1# touch /root/mntns/1
Creating and persisting a new mount namespace
1# unshare --mount=/root/mntns/1
We are now 'inside' the new namespace in a new shell process.
We'll change the shell prompt to make this clearer
PS1='inside# '
We can make a filesystem change, such as mounting a tmpfs
inside# mount -t tmpfs /mnt /mnt
inside# touch /mnt/hi-there
And observe it is not visible outside that namespace
2# findmnt /mnt
2# stat /mnt/hi-there
stat: cannot statx '/mnt/hi-there': No such file or directory
Back to the namespace shell, we can find an integer identifier for
the namespace via the shell processes /proc entry:
inside# readlink /proc/$$/ns/mnt
It will be something like mnt:[4026533646].
From another shell, we can list namespaces and see that it
exists:
2# lsns -t mnt
NS TYPE NPROCS PID USER COMMAND
…
4026533646 mnt 1 52525 root -bash
If we exit the shell that unshare created,
inside# exit
running lsns again should2 still list the namespace,
albeit with the NPROCS column now reading 0.
2# lsns -t mnt
We can see that a virtual filesystem of type nsfs is mounted at
the path we selected when we ran unshare:
Authorities in Pakistan have arrested 21 individuals accused of operating “Heartsender,” a once popular spam and malware dissemination service that operated for more than a decade. The main clientele for HeartSender were organized crime groups that tried to trick victim companies into making payments to a third party, and its alleged proprietors were publicly identified by KrebsOnSecurity in 2021 after they inadvertently infected their computers with malware.
Some of the core developers and sellers of Heartsender posing at a work outing in 2021. WeCodeSolutions boss Rameez Shahzad (in sunglasses) is in the center of this group photo, which was posted by employee Burhan Ul Haq, pictured just to the right of Shahzad.
A report from the Pakistani media outlet Dawn states that authorities there arrested 21 people alleged to have operated Heartsender, a spam delivery service whose homepage openly advertised phishing kits targeting users of various Internet companies, including Microsoft 365, Yahoo, AOL, Intuit, iCloud and ID.me. Pakistan’s National Cyber Crime Investigation Agency (NCCIA) reportedly conducted raids in Lahore’s Bahria Town and Multan on May 15 and 16.
The NCCIA told reporters the group’s tools were connected to more than $50m in losses in the United States alone, with European authorities investigating 63 additional cases.
“This wasn’t just a scam operation – it was essentially a cybercrime university that empowered fraudsters globally,” NCCIA Director Abdul Ghaffar said at a press briefing.
In January 2025, the FBI and the Dutch Police seized the technical infrastructure for the cybercrime service, which was marketed under the brands Heartsender, Fudpage and Fudtools (and many other “fud” variations). The “fud” bit stands for “Fully Un-Detectable,” and it refers to cybercrime resources that will evade detection by security tools like antivirus software or anti-spam appliances.
The FBI says transnational organized crime groups that purchased these services primarily used them to run business email compromise (BEC) schemes, wherein the cybercrime actors tricked victim companies into making payments to a third party.
Dawn reported that those arrested included Rameez Shahzad, the alleged ringleader of the Heartsender cybercrime business, which most recently operated under the Pakistani front company WeCodeSolutions. Mr. Shahzad was named and pictured in a 2021 KrebsOnSecurity story about a series of remarkable operational security mistakes that exposed their identities and Facebook pages showing employees posing for group photos and socializing at work-related outings.
Prior to folding their operations behind WeCodeSolutions, Shahzad and others arrested this month operated as a web hosting group calling itself The Manipulaters. KrebsOnSecurity first wrote about The Manipulaters in May 2015, mainly because their ads at the time were blanketing a number of popular cybercrime forums, and because they were fairly open and brazen about what they were doing — even who they were in real life.
Sometime in 2019, The Manipulaters failed to renew their core domain name — manipulaters[.]com — the same one tied to so many of the company’s business operations. That domain was quickly scooped up by Scylla Intel, a cyber intelligence firm that specializes in connecting cybercriminals to their real-life identities. Soon after, Scylla started receiving large amounts of email correspondence intended for the group’s owners.
In 2024, DomainTools.comfound the web-hosted version of Heartsender leaked an extraordinary amount of user information to unauthenticated users, including customer credentials and email records from Heartsender employees. DomainTools says the malware infections on Manipulaters PCs exposed “vast swaths of account-related data along with an outline of the group’s membership, operations, and position in the broader underground economy.”
Shahzad allegedly used the alias “Saim Raza,” an identity which has contacted KrebsOnSecurity multiple times over the past decade with demands to remove stories published about the group. The Saim Raza identity most recently contacted this author in November 2024, asserting they had quit the cybercrime industry and turned over a new leaf after a brush with the Pakistani police.
The arrested suspects include Rameez Shahzad, Muhammad Aslam (Rameez’s father), Atif Hussain, Muhammad Umar Irshad, Yasir Ali, Syed Saim Ali Shah, Muhammad Nowsherwan, Burhanul Haq, Adnan Munawar, Abdul Moiz, Hussnain Haider, Bilal Ahmad, Dilbar Hussain, Muhammad Adeel Akram, Awais Rasool, Usama Farooq, Usama Mehmood and Hamad Nawaz.
The only links are from The Daily Mail and The Mirror, but a marital affair was discovered because the cheater was recorded using his smart toothbrush at home when he was supposed to be at work.
As a small addendum to the last post, here are the relevant
commands #debci helpfully provided.
First, you need to install the autopkgtest package,
obviously:
# apt install autopkgtest
Then you need to create a Debian virtual machine to run the
tests (put the sid.raw wherever you prefer):
# autopkgtest-build-qemu sid /tmp/sid.raw
Then you can run the tests themselves, using the just created
virtual machine. The autopkgtest command can use the tests from
various sources, using the last argument to the command. In my case
what was the most helpful was to run the tests from my git clone
(which uses gbp) so I could edit the tests directly. So I didn't
give anything for testsrc (but
. would work as well I guess).
We are very excited to announce that Debian has selected nine contributors to
work under mentorship on a variety of
projects with us during the
Google Summer of Code.
Here is a list of the projects and students, along with details of the tasks to
be performed.
Deliverables of the project: Continuous integration tests for Debian Med
applications lacking a test, Quality Assurance review and bug fixing if issues
might be uncovered.
Deliverables of the project: Analysis and discussion of the current
state of device tweaks management in Debian and Mobian. Proposal for a
unified, run-time approach. Packaging of this service and tweaks
data/configuration for at least one device.
Deliverables of the project: New Debian packages with GPU
support. Enhanced GPU support within existing Debian packages.
More autopackagetests running on the Debian ROCm CI.
Deliverables of the project: Refreshing the set of daily-built
images. Having the set of daily-built images become automatic
again—that is, go back to the promise of having it daily-built.
Write an Ansible playbook/Chef recipe/Puppet whatsitsname to define a
virtual serve and have it build daily. Do the (very basic!) hardware
testing on several Raspberry computers. Do note, naturally, this will
require having access to the relevant hardware.
Deliverables of the project: Eventually I hope we can make vLLM into
Debian archive, based on which we can deliver something for LLM
inference out-of-the-box. If the amount of work eventually turns to be
beyond my expectation, I'm still happy to see how far we can go
towards this goal. If the amount of work required for vLLM is less
than I expected, we can also look at something else like SGLang,
another open source LLM inference library.
Congratulations and welcome to all the contributors!
The Google Summer of Code program is possible in Debian thanks to the efforts of
Debian Developers and Debian Contributors that dedicate part of their free time
to mentor contributors and outreach tasks.
Join us and help extend Debian! You can follow the contributors' weekly reports
on the debian-outreach mailing-list, chat with us on our
IRC channel or reach out to the individual projects' team
mailing lists.
Each year on August the 16th, we celebrate the Debian Project Anniversary.
Several communities around the world join us in celebrating "Debian Day" with
local events, parties, or gatherings.
So, how about celebrating the 32nd anniversary of the Debian Project in 2025 in
your city? As the 16th of August falls on a Saturday this year, we believe it
is great timing to gather people around your event.
We invite you and your local community to organize a Debian Day by hosting an
event with talks, workshops, a
bug squashing party, or
OpenPGP keysigning gathering, etc.
You could also hold a meeting with others in the Debian community in a smaller
social setting like a bar/pizzeria/cafeteria/restaurant to celebrate. In other
words, any type of celebrating is valid!
Many nations have some form of national identification number, especially around taxes. Argentina is no exception.
Their "CUIT" (Clave Única de Identificación Tributaria) and "CUIL" (Código Único de Identificación Laboral) are formatted as "##-########-#".
Now, as datasets often don't store things in their canonical representation, Nick's co-worker was given a task: "given a list of numbers, reformat them to look like CUIT/CUIL. That co-worker went off for five days, and produced this Java function.
public String normalizarCuitCuil(String cuitCuilOrigen){
StringvalorNormalizado=newString();
if (cuitCuilOrigen == null || "".equals(cuitCuilOrigen) || cuitCuilOrigen.length() < MINIMA_CANTIDAD_ACEPTADA_DE_CARACTERES_PARA_NORMALIZAR){
valorNormalizado = "";
}else{
StringBuildernumerosDelCuitCuil=newStringBuilder(13);
cuitCuilOrigen = cuitCuilOrigen.trim();
// Se obtienen solo los números:MatcherbuscadorDePatron= patternNumeros.matcher(cuitCuilOrigen);
while (buscadorDePatron.find()){
numerosDelCuitCuil.append(buscadorDePatron.group());
}
// Se le agregan los guiones:
valorNormalizado = numerosDelCuitCuil.toString().substring(0,2)
+ "-"
+ numerosDelCuitCuil.toString().substring(2,numerosDelCuitCuil.toString().length()-1)
+ "-"
+ numerosDelCuitCuil.toString().substring(numerosDelCuitCuil.toString().length()-1, numerosDelCuitCuil.toString().length());
}
return valorNormalizado;
}
We start with a basic sanity check that the string exists and is long enough. If it isn't, we return an empty string, which already annoys me, because an empty result is not a good way to communicate "I failed to parse".
But assuming we have data, we construct a string builder and trim whitespace. And already we have a problem: we already validated that the string was long enough, but if the string contained more trailing whitespace than a newline, we're looking at a problem. Now, maybe we can assume the data is good, but the next line implies that we can't rely on that- they create a regex matcher to identify numeric values, and for each numeric value they find, they append it to our StringBuilder. This implies that the string may contain non-numeric values which need to be rejected, which means our length validation was still wrong.
So either the data is clean and we're overvalidating, or the data is dirty and we're validating in the wrong order.
But all of that's a preamble to a terrible abuse of string builders, where they discard all the advantages of using a StringBuilder by calling toString again and again and again. Now, maybe the function caches results or the compiler can optimize it, but the result is a particularly unreadable blob of slicing code.
Now, this is ugly, but at least it works, assuming the input data is good. It definitely should never pass a code review, but it's not the kind of bad code that leaves one waking up in the middle of the night in a cold sweat.
No, what gets me about this is that it took five days to write. And according to Nick, the responsible developer wasn't just slacking off or going to meetings the whole time, they were at their desk poking at their Java IDE and looking confused for all five days.
And of course, because it took so long to write the feature, management didn't want to waste more time on kicking it back via a code review. So voila: it got forced through and released to production since it passed testing.
[Advertisement]
Keep all your packages and Docker containers in one place, scan for vulnerabilities, and control who can access different feeds. ProGet installs in minutes and has a powerful free version with a lot of great features that you can upgrade when ready.Learn more.
Author: Majoki Standing among some of the oldest living things on earth, Mourad Du, felt his age. Not just in years, but in possibilities lost. And, now, the impossibility he faced. Who could he tell? Would it even matter? They would all be gone soon. Nothing he could do, we could do, would change that. […]
The Long Now Foundation is proud to announce Christopher Michel as its first Artist-in-Residence. A distinguished photographer and visual storyteller, Michel has documented Long Now’s founders and visionaries — including Stewart Brand, Kevin Kelly, Danny Hillis, Esther Dyson, and many of its board members and speakers — for decades. Through his portrait photographs, he has captured their work in long-term thinking, deep time, and the future of civilization.
As Long Now’s first Artist-in-Residence, Michel will create a body of work inspired by the Foundation’s mission, expanding his exploration of time through portraiture, documentary photography, and large-scale visual projects. His work will focus on artifacts of long-term thinking, from the 10,000-year clock to the Rosetta Project, as well as the people shaping humanity’s long-term future.
Christopher Michel has made photographs of Long Now Board Members past and present. Clockwise from upper left: Stewart Brand, Danny Hillis, Kevin Kelly, Alexander Rose, Katherine Fulton, David Eagleman, Esther Dyson, and Danica Remy.
Michel will hold this appointment concurrently with his Artist-in-Residence position at the National Academies of Sciences, Engineering, and Medicine, where he uses photography to highlight the work of leading scientists, engineers, and medical professionals. His New Heroes project — featuring over 250 portraits of leaders in science, engineering, and medicine — aims to elevate science in society and humanize these fields. His images, taken in laboratories, underground research facilities, and atop observatories scanning the cosmos, showcase the individuals behind groundbreaking discoveries. In 02024, his portrait of Dr. Anthony Fauci was featured on the cover of Fauci’s memoir On Call.
💡
View more of Christopher Michel's photography, from portraits of world-renowned scientists to some of our planet's most incredible natural landscapes, at his website and on his Instagram account.
A former U.S. Navy officer and entrepreneur, Michel founded two technology companies before dedicating himself fully to photography. His work has taken him across all seven continents, aboard a U-2 spy plane, and into some of the most extreme environments on Earth. His images are widely published, appearing in major publications, album covers, and even as Google screensavers.
“What I love about Chris and the images he’s able to create is that at the deepest level they are really intended for the long now — for capturing this moment within the broader context of past and future,” said Long Now Executive Director Rebecca Lendl.
“These timeless, historic images help lift up the heroes of our times, helping us better understand who and what we are all about, reflecting back to us new stories about ourselves as a species.”
Michel’s photography explores the intersection of humanity and time, capturing the fragility and resilience of civilization. His work spans the most remote corners of the world — from Antarctica to the deep sea to the stratosphere — revealing landscapes and individuals who embody the vastness of time and space. His images — of explorers, scientists, and technological artifacts — meditate on humanity’s place in history.
Christopher Michel’s life in photography has taken him to all seven continents and beyond. Photos by Christopher Michel.
Michel’s photography at Long Now will serve as a visual bridge between the present and the far future, reinforcing the Foundation’s mission to foster long-term responsibility. “Photography,” Michel notes, “is a way of compressing time — capturing a fleeting moment that, paradoxically, can endure for centuries. At Long Now, I hope to create images that don’t just document the present but invite us to think in terms of deep time.”
His residency will officially begin this year, with projects unfolding over the coming months. His work will be featured in Long Now’s public programming, exhibitions, and archives, offering a new visual language for the Foundation’s mission to expand human timescales and inspire long-term thinking.
In advance of his appointment as Long Now’s inaugural Artist-in-Residence, Long Now’s Jacob Kuppermann had the opportunity to catch up with Christopher Michel and discuss his journey and artistic perspective.
This interview has been edited for length and clarity.
Long Now: For those of us less familiar with your work: tell us about your journey both as an artist and a photographer — and how you ended up involved with Long Now.
Christopher Michel: In a way, it’s the most unlikely journey. Of all the things I could have imagined I would've done as a kid, I am as far away from any of that as I could have imagined. My path, in most traditional ways of looking at it, is quite non-linear. Maybe the points of connectivity seem unclear, but some people smarter than me have seen connections and have made observations about how they may be related.
When I was growing up, I was an outsider, and I was interested in computers. I was programming in the late seventies, which was pretty early. My first computer was a Sinclair ZX 80, and then I went to college at the University of Illinois and Top Gun had just come out. And I thought, “maybe I want to serve my country.” And so I flew for the Navy as a navigator and mission commander — kind of like Goose — and hunted Russian submarines. I had a great time, I was always interested in computers, not taking any photographs really, which is such a regret. Imagine — flying 200 feet above the water for eight hours at a time, hunting drug runners or Russian subs, doing amazing stuff with amazing people. It just never occurred to me to take any photos. I was just busy doing my job. And then I went to work in the Pentagon in the office of the Chief of Naval Operations for the head of the Navy Reserve — I went to work for the bosses of the Navy.
If you'd asked me what I wanted to do, I guess I would've said, I think I want to go into politics and maybe go to law school. I'd seen the movie The Paper Chase, and I love the idea of the Socratic method. And then the Navy said, well, we’re going to send you to the Kennedy School, which is their school around public service. But then I ran into somebody at the Pentagon who said, "You should really go to Harvard Business School."
And I hadn't thought about it — I was never interested in business. He said that it's a really good degree because you can do lots of things with it. So I quit my job in the Navy and literally a week later I was living in Boston for my first day at Harvard Business School. It was a big eye-opening experience because I had lived in a kind of isolated world in the Navy — I only knew Navy people.
This was also a little bit before the pervasiveness of the internet. This is 01997 or 01996. People didn't know as much as they know now, and certainly entrepreneurship was not a thing in the same way that it was after people like Mark Zuckerberg. If you'd asked me what I wanted to do at Harvard, I would've said something relating to defense or operations. But then, I ran into this guy Dan Bricklin, who created VisiCalc. VisiCalc was one of the first three applications that drove the adoption of the personal computer. When we bought computers like the TRS 80 and Apple II in 01979 or 01980 we bought them for the Colossal Cave Adventure game, for VisiCalc, and for WordStar.
He gave a talk to our class and he said, "When I look back at my life, I feel like I created something that made a difference in the world." And it really got my attention, that idea of building something that can outlast us that's meaningful, and can be done through entrepreneurship. Before that, that was an idea that was just not part of the culture I knew anything about. So I got excited to do that. When I left Harvard Business School, I was still in the reserves and I had the idea that the internet would be a great way to connect, enable, and empower service members, veterans, and their families. So I helped start a company called Military.com, and it was one of the first social media companies to get to scale in the United States. And its concept may sound like a very obvious idea today because we live in a world where we know about things like Facebook, but this was five years before Facebook was created.
I raised a lot of money, and then I got fired, and then I came back and it was a really difficult time because that was also during the dot-com bubble bursting.
But during that time period, two interesting other things happened. The first: my good friend Ann Dwane gave me a camera. When I was driving cross country to come out here to find my fortune in Silicon Valley, I started taking some photos and film pictures and I thought, hey, my pictures are pretty good — this is pretty fun. And then I bought another camera, and I started taking more pictures and I was really hooked.
The second is actually my first connection to Long Now. What happened was that a guy came to visit me when I was running Military.com that I didn't know anything about — I'm not even sure why he came to see me. And he was a guy named Stewart Brand. So Stewart shows up in my office — he must've been introduced to me by someone, but I just didn't really have the context. Maybe I looked him up and had heard of the Whole Earth Catalog.
Anyways, he just had a lot of questions for me. And, of course, what I didn't realize, 25 years ago, is that this is what Stewart does. Stewart — somehow, like a time traveler — finds his way to the point of creation of something that he thinks might be important. He's almost a Zelig character. He just appears in my office and is curious about social media and the military. He served in the military, himself, too.
So I meet him and then he leaves and I don't hear anything of him for a while. Then, we have an idea of a product called Kit Up at Military.com. And the idea of Kit Up was based on Kevin Kelly’s Cool Tools — military people love gear, and we thought, well, what if we did a weekly gear thing? And I met with Kevin and I said, “Hey Kevin, what do you think about me kind of taking your idea and adapting it for the military?”
Of course, Kevin's the least competitive person ever, and he says, “Great idea!” So we created Kit Up, which was a listing of, for example, here are the best boots for military people, or the best jacket or the best gloves — whatever it might be.
As a byproduct of running these companies, I got exposed to Kevin and Stewart, and then I became better friends with Kevin. I got invited to some walks, and I would see those guys socially. And then in 02014, The Interval was created. I went there and I got to know Zander and I started making a lot of photos — have you seen my gallery of Long Now photos?
Christopher Michel's photos of the 10,000-year clock in Texas capture its scale and human context.
I've definitely seen it — whenever I need a photo of a Long Now person, I say, “let me see if there's a good Chris photo.”
This is an interesting thing that can happen in our lives, which are unintended projects. I do make photos with the idea that these photos could be quite important. There's a kind of alchemy around these photos. They're important now, but they're just going to be more important over time.
So my pathway is: Navy, entrepreneur, investor for a little while, and then photographer.
If there was a theme connecting these, it’s that I'm curious. The thing that really excites me most of all is that I like new challenges. I like starting over. It feels good! Another theme is the act of creation. You may think photography is quite a bit different than creating internet products, but they have some similarities! A great portrait is a created thing that can last and live without my own keeping it alive. It has its own life force. And that's creation. Companies are like that. Some companies go away, some companies stay around. Military.com stays around today.
So I'm now a photographer and I'm going all over the world and I'm making all these photos and I'm leading trips. Zander and the rest of the team invite me to events. I go to the clock and I climb the Bay Bridge, and I visit Biosphere 2. I'm just photographing a lot of stuff and I love it. The thing I love about Long Now people is, if you like quirky, intellectual people, these are your people. You know what I mean? And they're all nice, wonderful humans. So it feels good to be there and to help them.
In 02022, Christopher Michel accompanied Long Now on a trip to Biosphere 2 in Arizona.
During the first Trump administration, during Covid, I was a volunteer assisting the U.S. National Academies with science communication. I was on the board of the Division of Earth and Life Studies, and I was on the President’s Circle.
Now, the National Academies — they were created by Abraham Lincoln to answer questions of science for the U.S. government, they have two primary functions. One is an honorific, there's three academies: sciences, engineering, and medicine. So if you're one of the best physicists, you get made a member of the National Academies. It's based on the Royal Society in England.
But moreover, what’s relevant to everyone is that the National Academies oversee the National Research Council, which provides independent, evidence-based advice on scientific and technical questions. When the government needs to understand something complex, like how much mercury should be allowed in drinking water, they often turn to the Academies. A panel of leading experts is assembled to review the research and produce a consensus report. These studies help ensure that policy decisions are guided by the best available science.
Over time, I had the opportunity to work closely with the people who support and guide that process. We spent time with scientists from across disciplines. Many of them are making quiet but profound contributions to society. Their names may not be well known, but their work touches everything from health to energy to climate.
In those conversations, a common feeling kept surfacing. We were lucky to know these people. And we wished more of the country did, too. There is no shortage of intelligence or integrity in the world of science. What we need is more visibility. More connection. More ways for people to see who these scientists are, what they care about, and how they think.
That is part of why I do the work I do. Helping to humanize science is not about celebrating intellect alone. It's about building trust. When people can see the care, the collaboration, and the honesty behind scientific work, they are more likely to trust its results. Not because they are told to, but because they understand the people behind it.
These scientists and people in medicine and engineering are working on behalf of society. A lot of scientists aren't there for financial gain or celebrity. They're doing the work with a purpose behind it. And we live in a culture today where we don't know who any of these people are. We know Fauci, we might know Carl Sagan, we know Einstein — but people run out of scientists to list after that.
It’s a flaw in the system. These are the new heroes that should be our role models — people that are giving back. The National Academies asked me to be their first artist-in-residence, and I've been doing it now for almost five years, and it's an unpaid job. I fly myself around the country and I make portraits of scientists, and we give away the portraits to organizations. And I've done 260 or so portraits now. If you go to Wikipedia and you look up many of the Nobel Laureates from the U.S., they're my photographs.
I would say science in that world has never been under greater threat than it is today. I don't know how much of a difference my portraits are making, but at least it's some effort that I can contribute. I do think that these scientists having great portraits helps people pay attention — we live in that kind of culture today. So that is something we can do to help elevate science and scientists and humanize science.
And simultaneously, I’m still here at Long Now with Kevin and Stewart, and when there's interesting people there, I make photos of the speakers. I've spent time during the leadership transition and gotten to know all those people. And we talked and asked, well, why don't we incorporate this into the organization?
In December 02024, Christopher Michel helped capture incoming Long Now Executive Director Rebecca Lendl and Long Now Board President Patrick Dowd at The Interval.
We share an interest around a lot of these themes, and we are also in the business of collecting interesting people that the world should know about, and many of them are their own kind of new heroes.
I was really struck by what you said about how much with a really successful company or any form of institution, but also, especially, a photograph, put into the right setting with the right infrastructure around it to keep it lasting, can really live on beyond you and live on beyond whoever you're depicting.
That feels in itself very Long Now. We don't often think about the photograph as a tool of long-term thinking, but in a way it really is.
Christopher Michel: Well, this transition that we're in right now at Long Now is important for a lot of reasons. One is that a lot of organizations don't withstand transitions well, but the second is, these are the founders. All of these people that we've been talking about, they're the founders and we know them. We are the generation that knows them.
We think they will be here forever, and it will always be this way, but that's not true. The truth is, it's only what we document today that will be remembered in the future. How do we want the future to think about our founders? How do we want to think about their ideas and how are they remembered? That applies to not just the older board members — that applies to Rebecca and Patrick and you and me and all of us. This is where people kind of understate the role of capturing these memories. My talk at the Long Now is about how memories are the currency of our lives. When you think about our lives, what is it that at your deathbed you're going to be thinking about? It'll be this collection of things that happen to you and some evaluation of do those things matter?
I think about this a lot. I have some training as a historian and a historical ecologist. When I was doing archival research, I read all these government reports and descriptions and travelers' journals, and I could kind of get it. But whenever you uncovered that one photograph that they took or the one good sketch they got, then suddenly it was as if a portal opened and you were 150 years into the past. I suddenly understood, for example, what people mean when they say that the San Francisco Bay was full of otters at that time, because that's so hard to grasp considering what the Bay is like now. The visual, even if it's just a drawing, but especially if it's a photograph, makes such a mark in our memory in a way that very few other things can.
And, perhaps tied to that: you have taken thousands upon thousands of photos. You've made so many of these. I've noticed that you say “make photos,” rather than “take photos.” Is that an intentional theoretical choice about your process?
Christopher Michel: Well, all photographers say that. What do you think the difference is?
Taking — or capturing — it's like the image is something that is out there and you are just grabbing it from the world, whereas “making” indicates that this is a very intentional artistic process, and there are choices being made throughout and an intentional work of construction happening.
Christopher Michel: You're basically right. What I tell my students is that photographers visualize the image that they want and then they go to create that image. You can take a really good photo if you're lucky. Stuff happens. You just see something, you just take it. But even in that case, I am trying to think about what I can do to make that photo better. I'm taking the time to do that. So that's the difference, really.
The portraits — those are fun. I'd rather be real with them, and that's what I loved about Sara [Imari Walker]. I mean, Sara brought her whole self to that photo shoot.
On the question of capturing scientists specifically: how do you go about that process? Some of these images are more standard portraits. Others, you have captured them in a context that looks more like the context that they work in.
Christopher Michel: I'm trying to shoot environmental portraits, so I often visit them at their lab or in their homes — and this is connected to what I’ve talked about before.
We've conflated celebrity with heroism. George Dyson said something to the effect of: “Some people are celebrities because they're interesting, and some people are interesting because they're celebrities.”
Christopher Michel's photography captures Long Now Talks speakers. Clockwise from top left: Sara Imari Walker, Benjamin Bratton, Kim Stanley Robinson, and Stephen Heintz.
I think that society would benefit from a deeper understanding of these people, these scientists, and what they're doing. Honestly, I think they're better role models. We love actors and we love sports stars, and those are wonderful professions. But, I don't know, shouldn't a Nobel laureate be at least as well known?
There’s something there also that relates to timescales. At Long Now, we have the Pace Layers concept. A lot of those celebrities, whether they're athletes or actors or musicians — they're all doing incredible things, but those are very fast things. Those are things that are easy to capture in a limited attention span. Whereas the work of a scientist, the work of an engineer, the work of someone working in medicine can be one of slow payoffs. You make a discovery in 02006, but it doesn't have a clear world-changing impact until 02025.
Christopher Michel: Every day in my job, I'm running into people that have absolutely changed the world. Katalin Karikó won the Nobel Prize, or Walter Alvarez — he’s the son of a Nobel laureate. He's the one who figured out it was an asteroid that killed the dinosaurs. Diane Havlir, at UCSF — she helped create the cocktail that saved the lives of people who have AIDS. Think about the long-term cascading effect of saving millions of HIV-positive lives.
I mean, is there a sports star that can say that? The impact there is transformational. Look at what George Church is doing — sometimes with Ryan Phelan. This is what they're doing, and they're changing every element of our world and society that we live in. In a way engineering the world that we live in today, helping us understand the world that we live in, but we don't observe it in the way that we observe the fastest pace layer.
We had a writer who wrote an incredible piece for us about changing ecological baselines called “Peering Into The Invisible Present.” The concept is that it's so hard to observe the rate at which ecological change happens in the present. It's so slow — it is hard to tell that change is happening at all. But then if you were frozen in when Military.com was founded in 01999, and then you were thawed in 02025, you would immediately notice all these things that were different. For those of us who live through it as it happens, it is harder to tell those changes are happening, whereas it's very easy to tell when LeBron James has done an incredible dunk.
Christopher Michel: One cool thing about having a gallery that's been around for 20 years is you look at those photos and you think, “Ah, the world looked a little different then.”
It looks kind of the same, too — similar and different. There's a certain archival practice to having all these there. Something I noticed is that many of your images are uploaded with Creative Commons licensing. What feels important about that to you?
Because for me, the way for these images to become in use and to become immortal is to have it kind of spread throughout the internet. I’m sure I’ve seen images, photographs that you made so many times before I even knew who you were, just because they're out there, they enter the world.
Christopher Michel: As a 57-year-old, I want to say thank you for saying that. That's the objective. We hope that the work that we're doing makes a difference, and it is cool that a lot of people do in fact recognize the photos. Hopefully we will make even more that people care about. What's so interesting is we really don't even know — you never know which of these are going to have a long half life.
Russia is proposing a rule that all foreigners in Moscow install a tracking app on their phones.
Using a mobile application that all foreigners will have to install on their smartphones, the Russian state will receive the following information:
Residence location
Fingerprint
Face photograph
Real-time geo-location monitoring
This isn’t the first time we’ve seen this. Qatar did it in 2022 around the World Cup:
“After accepting the terms of these apps, moderators will have complete control of users’ devices,” he continued. “All personal content, the ability to edit it, share it, extract it as well as data from other apps on your device is in their hands. Moderators will even have the power to unlock users’ devices remotely.”
In November 2024, Badri and I applied for a Singapore visa to visit the country. To apply for a Singapore visa, you need to visit an authorized travel agent listed by the Singapore High Commission on their website. Unlike the Schengen visa (where only VFS can process applications), the Singapore visa has many authorized travel agents to choose from. I remember that the list mentioned as many as 25 authorized agents in Chennai. For my application, I randomly selected Ria International in Karol Bagh, New Delhi from the list.
Further, you need to apply not more than a month before your travel dates. As our travel dates were in December, we applied in the month of November.
For your reference, I submitted the following documents:
Passport
My photograph (35 mm x 45 mm)
Visa application form (Form 14A)
Cover letter to the Singapore High Commission, New Delhi
Proof of employment
Hotel booking
Flight ticket (reservations are sufficient)
Bank account statement for the last 6 months
I didn’t have my photograph in the specified dimensions, so the travel agent took my photo on the spot. The visa application was ₹2,567. Furthermore, I submitted my application on a Saturday and received a call from the travel agent on Tuesday informing me that they had received my visa from the Singapore High Commission.
The next day, I visit the travel agent’s office and picked up my passport and a black and white copy of my e-visa. Later, I downloaded a PDF of my visa and took a colored printout myself from the website mentioned on the visa.
Singapore granted me a multiple-entry visa for 2 months, even though I had applied for a 4-day single-entry visa. We were planning to add more countries to this trip; therefore, a multiple-entry visa would be helpful in case we wanted to use Singapore Airport, as it has good connectivity. However, it turned out that flights from Kuala Lumpur were much cheaper than those from Singapore, so we didn’t enter Singapore again after leaving.
Badri also did the same process but entirely remotely—he posted the documents to the visa agency in Chennai, and got his e-visa in a few days followed by his original passport which was delivered by courier.
He got his photo taken in the same dimensions mentioned above, and printed as matte finish as instructed. However, the visa agents asked why his photo was looking so faded. We don’t know if they thought the matte finish was faded or what. To rectify this, Badri emailed them a digital copy of the photo to them (both the cropped version and the original) and they handled the reprinting on their end (which he never got to see).
Before entering Singapore, we had to fill an arrival card - an online form asking a few details about our trip - within 72 hours of our arrival in Singapore.
I’ve just got a second hand Nissan LEAF. It’s not nearly as luxurious as the Genesis EV that I test drove [1]. It’s also just over 5 years old so it’s not as slick as the MG4 I test drove [2]. But the going rate for a LEAF of that age is $17,000 vs $35,000 or more for a new MG4 or $130,000+ for a Genesis. At this time the LEAF is the only EV in Australia that’s available on the second hand market in quantity. Apparently the cheapest new EV in Australia is a Great Wall one which is $32,000 and which had a wait list last time I checked, so $17,000 is a decent price if you want an electric car and aren’t interested in paying the price of a new car.
Starting the Car
One thing I don’t like about most recent cars (petrol as well as electric) is that they needlessly break traditions of car design. Inserting a key and turning it clockwise to start a car is a long standing tradition that shouldn’t be broken without a good reason. With the use of traditional keys you know that when a car has the key removed it can’t be operated, there’s no situation of the person with the key walking away and leaving the car driveable and there’s no possibility of the owner driving somewhere without the key and then being unable to start it. To start a LEAF you have to have the key fob device in range, hold down the brake pedal, and then press the power button. To turn on accessories you do the same but without holding down the brake pedal. They also have patterns of pushes, push twice to turn it on, push three times to turn it off. This is all a lot easier with a key where you can just rotate it as many clicks as needed.
The change of car design for the key means that no physical contact is needed to unlock the car. If someone stands by a car fiddling with the door lock it will get noticed which deters certain types of crime. If a potential thief can sit in a nearby car to try attack methods and only walk to the target vehicle once it’s unlocked it makes the crime a lot easier. Even if the electronic key is as secure as a physical key allowing attempts to unlock remotely weakens security. Reports on forums suggest that the electronic key is vulnerable to replay attacks. I guess I just have to hope that as car thieves typically get less than 10% of the value of a car it’s just not worth their effort to steal a $17,000 car. Unlocking doors remotely is a common feature that’s been around for a while but starting a car without a key being physically inserted is a new thing.
Other Features
The headlights turn on automatically when the car thinks that the level of ambient light warrants it. There is an option to override this to turn on lights but no option to force the lights to be off. So if you have your car in the “on” state while parked the headlights will be on even if you are parked and listening to the radio.
The LEAF has a bunch of luxury features which seem a bit ridiculous like seat warmers. It also has a heated steering wheel which has turned out to be a good option for me as I have problems with my hands getting cold. According to the My Nissan LEAF Forum the seat warmer uses a maximum of 50W per seat while the car heater uses a minimum of 250W [3]. So if there are one or two people in the car then significantly less power is used by just heating the seats and also keeping the car air cool reduces window fog.
The Bluetooth audio support works well. I’ve done hands free calls and used it for playing music from my phone. This is the first car I’ve owned with Bluetooth support. It also has line-in which might have had some use in 2019 but is becoming increasingly useless as phones with Bluetooth become more popular. It has support for two devices connecting via Bluetooth at the same time which could be handy if you wanted to watch movies on a laptop or tablet while waiting for someone.
The LEAF has some of the newer safety features, it tracks lane markers and notifies the driver via beeps and vibration if they stray from their lane. It also tries to read speed limit signs and display the last observed speed limit on the dash display. It also has a skid alert which in my experience goes off under hard acceleration when it’s not skidding but doesn’t go off if you lose grip when cornering. The features for detecting changing lanes when close to other cars and for emergency braking when another car is partly in the lane (even if moving out of the lane) don’t seem well tuned for Australian driving, the common trend on Australian roads is lawful-evil to use DND terminology.
Range
My most recent driving was just over 2 hours driving with a distance of a bit over 100Km which took the battery from 62% to 14%. So it looks like I can drive a bit over 200Km at an average speed of 50Km/h. I have been unable to find out the battery size for my car, my model will have either a 40KWh or 62KWh battery. Google results say it should be printed on the B pillar (it’s not) and that it can be deduced from the VIN (it can’t). I’m guessing that my car is the cheaper option which is supposed to do 240Km when new which means that a bit over 200Km at an average speed of 50Km/h when 6yo is about what’s expected. If it has the larger battery designed to do 340Km then doing 200Km in real use would be rather disappointing.
Assuming the battery is 40KWh that means it’s 5Km/KWh or 10KW average for the duration. That means that the 250W or so used by the car heater should only make a about 2% difference to range which is something that a human won’t usually notice. If I was to drive to another state I’d definitely avoid using the heater or airconditioner as an extra 4km could really matter when trying to find a place to charge when you aren’t familiar with the area. It’s also widely reported that the LEAF is less efficient at highway speeds which is an extra difficulty for that.
It seems that the LEAF just isn’t designed for interstate driving in Australia, it would be fine for driving between provinces of the Netherlands as it’s difficult to drive for 200km without leaving that country. Driving 700km to another city in a car with 200km range would mean charging 3 times along the way, that’s 2 hours of charging time when using fast chargers. This isn’t a problem at all as the average household in Australia has 1.8 cars and the battery electric vehicles only comprise 6.3% of the market. So if a household had a LEAF and a Prius they could just use the Prius for interstate driving. A recent Prius could drive from Melbourne to Canberra or Adelaide without refuelling on the way.
If I was driving to another state a couple of times a year I could rent an old fashioned car to do that and still be saving money when compared to buying petrol all the time.
Running Cost
Currently I’m paying about $0.28 per KWh for electricity, it’s reported that the efficiency of charging a LEAF is as low as 83% with the best efficiency when fast charging. I don’t own the fast charge hardware and don’t plan to install it as that would require getting a replacement of the connection to my home from the street, a new switchboard, and other expenses. So I expect I’ll be getting 83% efficiency when charging which means 48KWh for 200KM or 96KWH for the equivalent of a $110 tank of petrol. At $0.28/KWh it will cost $26 for the same amount of driving as $110 of petrol. I also anticipate saving money on service as there’s no need for engine oil changes and all the other maintenance of a petrol engine and regenerative braking will reduce the incidence of brake pad replacement.
I expect to save over $1100 per annum on using electricity instead of petrol even if I pay the full rate. But if I charge my car in the middle of the day when there is over supply and I don’t get paid for feeding electricity from my solar panels into the grid (as is common nowadays) it could be almost free to charge the car and I could save about $1500 on fuel.
Comfort
Electric cars are much quieter than cars with petrol or Diesel engines which is a major luxury feature. This car is also significantly newer than any other car I’ve driven much so it has features like Bluetooth audio which weren’t in other cars I’ve driven. When doing 100Km/h I can hear a lot of noise from the airflow, part of that would be due to the LEAF not having the extreme streamlining features that are associated with Teslas (such as retracting door handles) and part of that would be due to the car being older and the door seals not being as good as they were when new. It’s still a very quiet car with a very smooth ride. It would be nice if they used the quality of seals and soundproofing that VW uses in the Passat but I guess the car would be heavier and have a shorter range if they did that.
This car has less space for the driver than any other car I’ve driven (with the possible exception of a 1989 Ford Laser AKA Mazda 323). The front seats have less space than the Prius. Also the batteries seem to be under the front seats so there’s a bulge in the floor going slightly in front of the front seats when they are moved back which gives less space for the front passenger to move their legs and less space for the driver when sitting in a parked car. There are a selection of electric cars from MG, BYD, and Great Wall that have more space in the front seats, if those cars were on the second hand market I might have made a different choice but a second hand LEAF is the only option for a cheap electric car in Australia now.
The heated steering wheel and heated seats took a bit of getting used to but I have come to appreciate the steering wheel and the heated seats are a good way of extending the range of the car.
Misc Notes
The LEAF is a fun car to drive and being quiet is a luxury feature, it’s no different to other EVs in this regard. It isn’t nearly as fast as a Tesla, but is faster than most cars actually drive on the road.
When I was looking into buying a LEAF from one of the car sales sites I was looking at models less than 5 years old. But the ZR1 series went from 2017 to 2023 so there’s probably not much difference between a 2019 model and a 2021 model but there is a significant price difference. I didn’t deliberately choose a 2019 car, it was what a relative was selling at a time when I needed a new car. But knowing what I know now I’d probably look at that age of LEAF if choosing from the car sales sites.
Problems
When I turn the car off the side mirrors fold in but when I turn it on they usually don’t automatically unfold if I have anything connected to the cigarette lighter power port. This is a well known problem and documented on forums. This is something that Nissan really should have tested before release because phone chargers that connect to the car cigarette lighter port have been common for at least 6 years before my car was manufactured and at least 4 years before the ZE1 model was released.
The built in USB port doesn’t supply enough power to match the power use of a Galaxy Note 9 running Google maps and playing music through Bluetooth. On it’s own this isn’t a big deal but combined with the mirror issue of using a charger in the cigarette lighter port it’s a problem.
The cover over the charging ports doesn’t seem to lock easily enough, I had it come open when doing 100Km/h on a freeway. This wasn’t a big deal but as the cover opens in a suicide-door manner at a higher speed it could have broken off.
The word is that LEAF service in Australia is not done well. Why do you need regular service of an electric car anyway? For petrol and Diesel cars it’s engine oil replacement that makes it necessary to have regular service. Surely you can just drive it until either the brakes squeak or the tires seem worn.
I have been having problems charging, sometimes it will charge from ~20% to 100% in under 24 hours, sometimes in 14+ hours it only gets to 30%.
Conclusion
This is a good car and the going price on them is low. I generally recommend them as long as you aren’t really big and aren’t too worried about the poor security.
It’s a fun car to drive even with a few annoying things like the mirrors not automatically extending on start.
The older ones like this are cheap enough that they should be able to cover the entire purchase cost in 10 years by the savings from not buying petrol even if you don’t drive a lot. With a petrol car I use about 13 tanks of petrol a year so my driving is about half the average for Australia. Some people could cover the purchase price of a second hand leaf in under 5 years.
Trying to send email. Email is hard. Configuration is hard. I don't remember how I send email properly. Trying to use git send-email since ages, and I think I am getting email bounces from random lists. SPF failure. Oh now.
Author: Hillary Lyon “I’d do it in a flash,” Jason declared, tightening the lid of the cocktail shaker. “Clone you, I mean. And how about you? What would you do?” In his hands, the shaker was a percussion instrument. The rhythm was enticing; it made Kerra want to dance. She gave him a teasing, crooked […]
Our anonymous submitter, whom we'll call Craig, worked for GlobalCon. GlobalCon relied on an offshore team on the other side of the world for adding/removing users from the system, support calls, ticket tracking, and other client services. One day at work, an urgent escalated ticket from Martin, the offshore support team lead, fell into Craig's queue. Seated before his cubicle workstation, Craig opened the ticket right away:
The new GlobalCon support website is not working. Appears to have been taken over by ChatGPT. The entire support team is blocked by this.
Instead of feeling any sense of urgency, Craig snorted out loud from perverse amusement.
"What was that now?" The voice of Nellie, his coworker, wafted over the cubicle wall that separated them.
"Urgent ticket from the offshore team," Craig replied.
"What is it this time?" Nellie couldn't suppress her glee.
"They're dead in the water because the new support page was, quote, taken over by ChatGPT."
Nellie laughed out loud.
"Hey! I know humor is important to surviving this job." A level, more mature voice piped up behind Craig from the cube across from his. It belonged to Dana, his manager. "But it really is urgent if they're all blocked. Do your best to help, escalate to me if you get stuck."
"OK, thanks. I got this," Craig assured her.
He was already 99.999% certain that no part of their web domain had gone down or been conquered by a belligerent AI, or else he would've heard of it by now. To make sure, Craig opened support.globalcon.com in a browser tab: sure enough, it worked. Martin had supplied no further detail, no logs or screenshots or videos, and no steps to reproduce, which was sadly typical of most of these escalations. At a loss, Craig took a screenshot of the webpage, opened the ticket, and posted the following: Everything's fine on this end. If it's still not working for you, let's do a screenshare.
Granted, a screensharing session was less than ideal given the 12-hour time difference. Craig hoped that whatever nefarious shenanigans ChatGPT had allegedly committed were resolved by now.
The next day, Craig received an update. Still not working. The entire team is still blocked. We're too busy to do a screenshare, please resolve ASAP.
Craig checked the website again with both laptop and phone. He had other people visit the website for him, trying different operating systems and web browsers. Every combination worked. Two things mystified him: how was the entire offshore team having this issue, and how were they "too busy" for anything if they were all dead in the water? At a loss, Craig attached an updated screenshot to the ticket and typed out the best CYA response he could muster. The new support website is up and has never experienced any issues. With no further proof or steps to reproduce this, I don't know what to tell you. I think a screensharing session would be the best thing at this point.
The next day, Martin parroted his last message almost word for word, except this time he assented to a screensharing session, suggesting the next morning for himself.
It was deep into the evening when Craig set up his work laptop on his kitchen counter and started a call and session for Martin to join. "OK. Can you show me what you guys are trying to do?"
To his surprise, he watched Martin open up Microsoft Teams first thing. From there, Martin accessed a chat to the entire offshore support team from the CPO of GlobalCon. The message proudly introduced the new support website and outlined the steps for accessing it. One of those steps was to visit support.globalcon.com.
The web address was rendered as blue outlined text, a hyperlink. Craig observed Martin clicking the link. A web browser opened up. Lo and behold, the page that finally appeared was www.chatgpt.com.
Craig blinked with surprise. "Hang on! I'm gonna take over for a second."
Upon taking control of the session, Craig switched back to Teams and accessed the link's details. The link text was correct, but the link destination was ChatGPT. It seemed like a copy/paste error that the CPO had tried to fix, not realizing that they'd needed to do more than simply update the link text.
"This looks like a bad link," Craig said. "It got sent to your entire team. And all of you have been trying to access the support site with this link?"
"Correct," Martin replied.
Craig was glad he couldn't be seen frowning and shaking his head. "Lemme show you what I've been doing. Then you can show everyone else, OK?"
After surrendering control of the session, Craig patiently walked Martin through the steps of opening a web browser, typing support.globalcon.com into the header, and hitting Return. The site opened without any issue. From there, Craig taught Martin how to create a bookmark for it.
"Just click on that from now on, and it'll always take you to the right place," Craig said. "In the future, before you click on any hyperlink, make sure you hover your mouse over it to see where it actually goes. Links can be labeled one thing when they actually take you somewhere else. That's how phishing works."
"Oh," Martin said. "Thanks!"
The call ended on a positive note, but left Craig marveling at the irony of lecturing the tech support lead on Internet 101 in the dead of night.
This is a bug fix and minor feature release over INN 2.7.2, and the
upgrade should be painless. You can download the new release from
ISC or
my personal INN pages. The latter also has
links to the full changelog and the other INN documentation.
Author: Julian Miles, Staff Writer The bright lights look the same. Sitting myself down on the community server bench, I lean back until my spine hits the backrest. My gear starts charging. Diagnostics start scrolling down the inner bars of both eyes. The trick is not to try and read them. You’ll only give yourself […]
It's a holiday in the US today, so we're taking a long weekend. We flip back to a classic story of a company wanting to fill 15 different positions by hiring only one person. It's okay, Martin handles the database. Original - Remy
A curious email arrived in Phil's Inbox. "Windows Support Engineer required. Must have experience of the following:" and then a long list of Microsoft products.
Phil frowned. The location was convenient; the salary was fine, just the list of software seemed somewhat intimidating. Nevertheless, he replied to the agency saying that he was interested in applying for the position.
A few days later, Phil met Jason, the guy from the recruitment agency, in a hotel foyer. "It's a young, dynamic company", the recruiter explained,"They're growing really fast. They've got tons of funding and their BI Analysis Suite is positioning them to be a leading player in their field."
Phil nodded. "Ummm, I'm a bit worried about this list of products", referring to the job description. "I've never dealt with Microsoft Proxy Server 1.0, and I haven't dealt with Windows 95 OSR2 for a long while."
"Don't worry," Jason assured, "The Director is more an idea man. He just made a list of everything he's ever heard of. You'll just be supporting Windows Server 2003 and their flagship application."
Phil winced. He was a vanilla network administrator – supporting a custom app wasn't quite what he was looking for, but he desperately wanted to get out of his current job.
A few days later, Phil arrived for his interview. The company had rented smart offices on a new business park on the edge of town. He was ushered into the conference room, where he was joined by The Director and The Manager.
"So", said The Manager. "You've seen our brochure?"
"Yeah", said Phil, glancing at the glossy brochure in front of him with bright, Barbie-pink lettering all over it.
"You've seen a demo version of our application – what do you think?"
"Well, I think that it's great!", said Phil. He'd done his research – there were over 115 companies offering something very similar, and theirs wasn't anything special. "I particularly like the icons."
"Wonderful!" The Director cheered while firing up PowerPoint. "These are our servers. We rent some rack space in a data center 100 miles away." Phil looked at the projected picture. It showed a rack of a dozen servers.
"They certainly look nice." said Phil. They did look nice – brand new with green lights.
"Now, we also rent space in another data center on the other side of the country," The Manager added.
"This one is in a former cold-war bunker!" he said proudly. "It's very secure!" Phil looked up at another photo of some more servers.
"What we want the successful applicant to do is to take care of the servers on a day to day basis, but we also need to move those servers to the other data center", said The Director. "Without any interruption of service."
"Also, we need someone to set up the IT for the entire office. You know, email, file & print, internet access – that kind of thing. We've got a dozen salespeople starting next week, they'll all need email."
"And we need it to be secure."
"And we need it to be documented."
Phil was scribbled notes as best he could while the interviewing duo tag teamed him with questions.
"You'll also provide second line support to end users of the application."
"And day-to-day IT support to our own staff. Any questions?"
Phil looked up. "Ah… which back-end database does the application use?" he asked, expecting the answer would be SQL Server or perhaps Oracle, but The Director's reply surprised him.
"Oh, we wrote our own database from scratch. Martin wrote it." Phil realized his mouth was open, and shut it. The Director saw his expression, and explained. "You see, off the shelf databases have several disadvantages – the data gets fragmented, they're not quick enough, and so on. But don't have to worry about that – Martin takes care of the database. Do you have any more questions?"
Phil frowned. "So, to summarize: you want a data center guy to take care of your servers. You want someone to migrate the application from one data center to another, without any outage. You want a network administrator to set up, document and maintain an entire network from scratch. You want someone to provide internal support to the staff. And you want a second line support person to support the our flagship application."
"Exactly", beamed The Director paternally. "We want one person who can do all those things. Can you do that?"
Phil took a deep breath. "I don't know," he replied, and that was the honest answer.
"Right", The Manager said. "Well, if you have any questions, just give either of us a call, okay?"
Moments later, Phil was standing outside, clutching the garish brochure with the pink letters. His head was spinning. Could he do all that stuff? Did he want to? Was Martin a genius or a madman to reinvent the wheel with the celebrated database?
In the end, Phil was not offered the job and decided it might be best to stick it out at his old job for a while longer. After all, compared to Martin, maybe his job wasn't so bad after all.
[Advertisement] Plan Your .NET 9 Migration with Confidence Your journey to .NET 9 is more than just one decision.Avoid migration migraines with the advice in this free guide. Download Free Guide Now!
One one my biggest worries about VPNs is the amount of trust users need to place in them, and how opaque most of them are about who owns them and what sorts of data they retain.
A new study found that many commercials VPNS are (often surreptitiously) owned by Chinese companies.
It would be hard for U.S. users to avoid the Chinese VPNs. The ownership of many appeared deliberately opaque, with several concealing their structure behind layers of offshore shell companies. TTP was able to determine the Chinese ownership of the 20 VPN apps being offered to Apple’s U.S. users by piecing together corporate documents from around the world. None of those apps clearly disclosed their Chinese ownership.
In this post, I demonstrate the optimal workflow for creating new Debian packages in 2025, preserving the upstream git history. The motivation for this is to lower the barrier for sharing improvements to and from upstream, and to improve software provenance and supply-chain security by making it easy to inspect every change at any level using standard git tooling.
Key elements of this workflow include:
Using a Git fork/clone of the upstream repository as the starting point for creating Debian packaging repositories.
Consistent use of the same git-buildpackage commands, with all package-specific options in gbp.conf.
Pristine-tar and upstream signatures for supply-chain security.
Use of Files-Excluded in the debian/copyright file to filter out unwanted files in Debian.
Patch queues to easily rebase and cherry-pick changes across Debian and upstream branches.
Efficient use of Salsa, Debian’s GitLab instance, for both automated feedback from CI systems and human feedback from peer reviews.
To make the instructions so concrete that anyone can repeat all the steps themselves on a real package, I demonstrate the steps by packaging the command-line tool Entr. It is written in C, has very few dependencies, and its final Debian source package structure is simple, yet exemplifies all the important parts that go into a complete Debian package:
Creating a new packaging repository and publishing it under your personal namespace on salsa.debian.org.
Using dh_make to create the initial Debian packaging.
Posting the first draft of the Debian packaging as a Merge Request (MR) and using Salsa CI to verify Debian packaging quality.
Running local builds efficiently and iterating on the packaging process.
Create new Debian packaging repository from the existing upstream project git repository
First, create a new empty directory, then clone the upstream Git repository inside it:
Using a clean directory makes it easier to inspect the build artifacts of a Debian package, which will be output in the parent directory of the Debian source directory.
The extra parameters given to git clone lay the foundation for the Debian packaging git repository structure where the upstream git remote name is upstreamvcs. Only the upstream main branch is tracked to avoid cluttering git history with upstream development branches that are irrelevant for packaging in Debian.
Next, enter the git repository directory and list the git tags. Pick the latest upstream release tag as the commit to start the branch upstream/latest. This latest refers to the upstream release, not the upstream development branch. Immediately after, branch off the debian/latest branch, which will have the actual Debian packaging files in the debian/ subdirectory.
shellcd entr
git tag # shows the latest upstream release tag was '5.6'
git checkout -b upstream/latest 5.6
git checkout -b debian/latest
cd entr
git tag # shows the latest upstream release tag was '5.6'git checkout -b upstream/latest 5.6
git checkout -b debian/latest
At this point, the repository is structured according to DEP-14 conventions, ensuring a clear separation between upstream and Debian packaging changes, but there are no Debian changes yet. Next, add the Salsa repository as a new remote which called origin, the same as the default remote name in git.
This is an important preparation step to later be able to create a Merge Request on Salsa that targets the debian/latest branch, which does not yet have any debian/ directory.
Launch a Debian Sid (unstable) container to run builds in
To ensure that all packaging tools are of the latest versions, run everything inside a fresh Sid container. This has two benefits: you are guaranteed to have the most up-to-date toolchain, and your host system stays clean without getting polluted by various extra packages. Additionally, this approach works even if your host system is not Debian/Ubuntu.
cd ..
podman run --interactive --tty --rm --shm-size=1G --cap-add SYS_PTRACE \
--env='DEB*' --volume=$PWD:/tmp/test --workdir=/tmp/test debian:sid bash
Note that the container should be started from the parent directory of the git repository, not inside it. The --volume parameter will loop-mount the current directory inside the container. Thus all files created and modified are on the host system, and will persist after the container shuts down.
Once inside the container, install the basic dependencies:
To create the files needed for the actual Debian packaging, use dh_make:
shell# dh_make --packagename entr_5.6 --single --createorig
Maintainer Name : Otto Kekäläinen
Email-Address : otto@debian.org
Date : Sat, 15 Feb 2025 01:17:51 +0000
Package Name : entr
Version : 5.6
License : blank
Package Type : single
Are the details correct? [Y/n/q]
Done. Please edit the files in the debian/ subdirectory now.
# dh_make --packagename entr_5.6 --single --createorigMaintainer Name : Otto Kekäläinen
Email-Address : otto@debian.org
Date : Sat, 15 Feb 2025 01:17:51 +0000
Package Name : entr
Version : 5.6
License : blank
Package Type : single
Are the details correct? [Y/n/q]Done. Please edit the files in the debian/ subdirectory now.
Due to how dh_make works, the package name and version need to be written as a single underscore separated string. In this case, you should choose --single to specify that the package type is a single binary package. Other options would be --library for library packages (see libgda5 sources as an example) or --indep (see dns-root-data sources as an example). The --createorig will create a mock upstream release tarball (entr_5.6.orig.tar.xz) from the current release directory, which is necessary due to historical reasons and how dh_make worked before git repositories became common and Debian source packages were based off upstream release tarballs (e.g. *.tar.gz).
At this stage, a debian/ directory has been created with template files, and you can start modifying the files and iterating towards actual working packaging.
shellgit add debian/
git commit -a -m "Initial Debian packaging"
git add debian/
git commit -a -m "Initial Debian packaging"
Review the files
The full list of files after the above steps with dh_make would be:
All the other files have been created for convenience so the packager has template files to work from. The files with the suffix .ex are example files that won’t have any effect until their content is adjusted and the suffix removed.
For detailed explanations of the purpose of each file in the debian/ subdirectory, see the following resources:
The Debian Policy Manual: Describes the structure of the operating system, the package archive and requirements for packages to be included in the Debian archive.
The Developer’s Reference: A collection of best practices and process descriptions Debian packagers are expected to follow while interacting with one another.
Debhelper man pages: Detailed information of how the Debian package build system works, and how the contents of the various files in ‘debian/’ affect the end result.
Most of these files have standardized formatting conventions to make collaboration easier. To automatically format the files following the most popular conventions, simply run wrap-and-sort -vast or debputy reformat --style=black.
Identify build dependencies
The most common reason for builds to fail is missing dependencies. The easiest way to identify which Debian package ships the required dependency is using apt-file. If, for example, a build fails complaining that pcre2posix.h cannot be found or that libcre2-posix.so is missing, you can use these commands:
The output above implies that the debian/control should be extended to define a Build-Depends: libpcre2-dev relationship.
There is also dpkg-depcheck that uses strace to trace the files the build process tries to access, and lists what Debian packages those files belong to. Example usage:
shelldpkg-depcheck -b debian/rules build
dpkg-depcheck -b debian/rules build
Build the Debian sources to generate the .deb package
After the first pass of refining the contents of the files in debian/, test the build by running dpkg-buildpackage inside the container:
shelldpkg-buildpackage -uc -us -b
dpkg-buildpackage -uc -us -b
The options -uc -us will skip signing the resulting Debian source package and other build artifacts. The -b option will skip creating a source package and only build the (binary) *.deb packages.
The output is very verbose and gives a large amount of context about what is happening during the build to make debugging build failures easier. In the build log of entr you will see for example the line dh binary --buildsystem=makefile. This and other dh commands can also be run manually if there is a need to quickly repeat only a part of the build while debugging build failures.
To see what files were generated or modified by the build simply run git status --ignored:
shell$ git status --ignored
On branch debian/latest
Untracked files:
(use "git add <file>..." to include in what will be committed)
debian/debhelper-build-stamp
debian/entr.debhelper.log
debian/entr.substvars
debian/files
Ignored files:
(use "git add -f <file>..." to include in what will be committed)
Makefile
compat.c
compat.o
debian/.debhelper/
debian/entr/
entr
entr.o
status.o
$ git status --ignored
On branch debian/latest
Untracked files:
(use "git add <file>..." to include in what will be committed) debian/debhelper-build-stamp
debian/entr.debhelper.log
debian/entr.substvars
debian/files
Ignored files:
(use "git add -f <file>..." to include in what will be committed) Makefile
compat.c
compat.o
debian/.debhelper/
debian/entr/
entr
entr.o
status.o
Re-running dpkg-buildpackage will include running the command dh clean, which assuming it is configured correctly in the debian/rules file will reset the source directory to the original pristine state. The same can of course also be done with regular git commands git reset --hard; git clean -fdx. To avoid accidentally committing unnecessary build artifacts in git, a debian/.gitignore can be useful and it would typically include all four files listed as “untracked” above.
After a successful build you would have the following files:
The contents of debian/entr are essentially what goes into the resulting entr_5.6-1_amd64.deb package. Familiarizing yourself with the majority of the files in the original upstream source as well as all the resulting build artifacts is time consuming, but it is a necessary investment to get high-quality Debian packages.
There are also tools such as Debcraft that automate generating the build artifacts in separate output directories for each build, thus making it easy to compare the changes to correlate what change in the Debian packaging led to what change in the resulting build artifacts.
Re-run the initial import with git-buildpackage
When upstreams publish releases as tarballs, they should also be imported for optimal software supply-chain security, in particular if upstream also publishes cryptographic signatures that can be used to verify the authenticity of the tarballs.
To achieve this, the files debian/watch, debian/upstream/signing-key.asc, and debian/gbp.conf need to be present with the correct options. In the gbp.conf file, ensure you have the correct options based on:
Does upstream release tarballs? If so, enforce pristine-tar = True.
Does upstream sign the tarballs? If so, configure explicit signature checking with upstream-signatures = on.
Does upstream have a git repository, and does it have release git tags? If so, configure the release git tag format, e.g. upstream-vcs-tag = %(version%~%.)s.
To validate that the above files are working correctly, run gbp import-orig with the current version explicitly defined:
shell$ gbp import-orig --uscan --upstream-version 5.6
gbp:info: Launching uscan...
gpgv: Signature made 7. Aug 2024 07.43.27 PDT
gpgv: using RSA key 519151D83E83D40A232B4D615C418B8631BC7C26
gpgv: Good signature from "Eric Radman <ericshane@eradman.com>"
gbp:info: Using uscan downloaded tarball ../entr_5.6.orig.tar.gz
gbp:info: Importing '../entr_5.6.orig.tar.gz' to branch 'upstream/latest'...
gbp:info: Source package is entr
gbp:info: Upstream version is 5.6
gbp:info: Replacing upstream source on 'debian/latest'
gbp:info: Running Postimport hook
gbp:info: Successfully imported version 5.6 of ../entr_5.6.orig.tar.gz
$ gbp import-orig --uscan --upstream-version 5.6
gbp:info: Launching uscan...
gpgv: Signature made 7. Aug 2024 07.43.27 PDT
gpgv: using RSA key 519151D83E83D40A232B4D615C418B8631BC7C26
gpgv: Good signature from "Eric Radman <ericshane@eradman.com>"gbp:info: Using uscan downloaded tarball ../entr_5.6.orig.tar.gz
gbp:info: Importing '../entr_5.6.orig.tar.gz' to branch 'upstream/latest'...
gbp:info: Source package is entr
gbp:info: Upstream version is 5.6
gbp:info: Replacing upstream source on 'debian/latest'gbp:info: Running Postimport hook
gbp:info: Successfully imported version 5.6 of ../entr_5.6.orig.tar.gz
As the original packaging was done based on the upstream release git tag, the above command will fetch the tarball release, create the pristine-tar branch, and store the tarball delta on it. This command will also attempt to create the tag upstream/5.6 on the upstream/latest branch.
Import new upstream versions in the future
Forking the upstream git repository, creating the initial packaging, and creating the DEP-14 branch structure are all one-off work needed only when creating the initial packaging.
Going forward, to import new upstream releases, one would simply run git fetch upstreamvcs; gbp import-orig --uscan, which fetches the upstream git tags, checks for new upstream tarballs, and automatically downloads, verifies, and imports the new version. See the galera-4-demo example in the Debian source packages in git explained post as a demo you can try running yourself and examine in detail.
You can also try running gbp import-orig --uscan without specifying a version. It would fetch it, as it will notice there is now Entr version 5.7 available, and import it.
Build using git-buildpackage
From this stage onwards you should build the package using gbp buildpackage, which will do a more comprehensive build.
shellgbp buildpackage -uc -us
gbp buildpackage -uc -us
The git-buildpackage build also includes running Lintian to find potential Debian policy violations in the sources or in the resulting .deb binary packages. Many Debian Developers run lintian -EviIL +pedantic after every build to check that there are no new nags, and to validate that changes intended to previous Lintian nags were correct.
Open a Merge Request on Salsa for Debian packaging review
Getting everything perfectly right takes a lot of effort, and may require reaching out to an experienced Debian Developers for review and guidance. Thus, you should aim to publish your initial packaging work on Salsa, Debian’s GitLab instance, for review and feedback as early as possible.
For somebody to be able to easily see what you have done, you should rename your debian/latest branch to another name, for example next/debian/latest, and open a Merge Request that targets the debian/latest branch on your Salsa fork, which still has only the unmodified upstream files.
If you have followed the workflow in this post so far, you can simply run:
git checkout -b next/debian/latest
git push --set-upstream origin next/debian/latest
Open in a browser the URL visible in the git remote response
Write the Merge Request description in case the default text from your commit is not enough
Mark the MR as “Draft” using the checkbox
Publish the MR and request feedback
Once a Merge Request exists, discussion regarding what additional changes are needed can be conducted as MR comments. With an MR, you can easily iterate on the contents of next/debian/latest, rebase, force push, and request re-review as many times as you want.
While at it, make sure the Settings > CI/CD page has under CI/CD configuration file the value debian/salsa-ci.yml so that the CI can run and give you immediate automated feedback.
Open a Merge Request / Pull Request to fix upstream code
Due to the high quality requirements in Debian, it is fairly common that while doing the initial Debian packaging of an open source project, issues are found that stem from the upstream source code. While it is possible to carry extra patches in Debian, it is not good practice to deviate too much from upstream code with custom Debian patches. Instead, the Debian packager should try to get the fixes applied directly upstream.
Using git-buildpackage patch queues is the most convenient way to make modifications to the upstream source code so that they automatically convert into Debian patches (stored at debian/patches), and can also easily be submitted upstream as any regular git commit (and rebased and resubmitted many times over).
First, decide if you want to work out of the upstream development branch and later cherry-pick to the Debian packaging branch, or work out of the Debian packaging branch and cherry-pick to an upstream branch.
The example below starts from the upstream development branch and then cherry-picks the commit into the git-buildpackage patch queue:
shellgit checkout -b bugfix-branch master
nano entr.c
make
./entr # verify change works as expected
git commit -a -m "Commit title" -m "Commit body"
git push # submit upstream
gbp pq import --force --time-machine=10
git cherry-pick <commit id>
git commit --amend # extend commit message with DEP-3 metadata
gbp buildpackage -uc -us -b
./entr # verify change works as expected
gbp pq export --drop --commit
git commit --amend # Write commit message along lines "Add patch to .."
git checkout -b bugfix-branch master
nano entr.c
make
./entr # verify change works as expectedgit commit -a -m "Commit title" -m "Commit body"git push # submit upstreamgbp pq import --force --time-machine=10git cherry-pick <commit id>
git commit --amend # extend commit message with DEP-3 metadatagbp buildpackage -uc -us -b
./entr # verify change works as expectedgbp pq export --drop --commit
git commit --amend # Write commit message along lines "Add patch to .."
The example below starts by making the fix on a git-buildpackage patch queue branch, and then cherry-picking it onto the upstream development branch:
These can be run at any time, regardless if any debian/patches existed prior, or if existing patches applied cleanly or not, or if there were old patch queue branches around. Note that the extra -b in gbp buildpackage -uc -us -b instructs to build only binary packages, avoiding any nags from dpkg-source that there are modifications in the upstream sources while building in the patches-applied mode.
Programming-language specific dh-make alternatives
As each programming language has its specific way of building the source code, and many other conventions regarding the file layout and more, Debian has multiple custom tools to create new Debian source packages for specific programming languages.
Notably, Python does not have its own tool, but there is an dh_make --python option for Python support directly in dh_make itself. The list is not complete and many more tools exist. For some languages, there are even competing options, such as for Go there is in addition to dh-make-golang also Gophian.
When learning Debian packaging, there is no need to learn these tools upfront. Being aware that they exist is enough, and one can learn them only if and when one starts to package a project in a new programming language.
The difference between source git repository vs source packages vs binary packages
As seen in earlier example, running gbp buildpackage on the Entr packaging repository above will result in several files:
The entr_5.6-1_amd64.deb is the binary package, which can be installed on a Debian/Ubuntu system. The rest of the files constitute the source package. To do a source-only build, run gbp buildpackage -S and note the files produced:
The source package files can be used to build the binary .deb for amd64, or any architecture that the package supports. It is important to grasp that the Debian source package is the preferred form to be able to build the binary packages on various Debian build systems, and the Debian source package is not the same thing as the Debian packaging git repository contents.
If the package is large and complex, the build could result in multiple binary packages. One set of package definition files in debian/ will however only ever result in a single source package.
Option to repackage source packages with Files-Excluded lists in the debian/copyright file
Some upstream projects may include binary files in their release, or other undesirable content that needs to be omitted from the source package in Debian. The easiest way to filter them out is by adding to the debian/copyright file a Files-Excluded field listing the undesired files. The debian/copyright file is read by uscan, which will repackage the upstream sources on-the-fly when importing new upstream releases.
The resulting repackaged upstream source tarball, as well as the upstream version component, will have an extra +ds to signify that it is not the true original upstream source but has been modified by Debian:
godot_4.3+ds.orig.tar.xz
godot_4.3+ds-1_amd64.deb
godot_4.3+ds.orig.tar.xz
godot_4.3+ds-1_amd64.deb
Creating one Debian source package from multiple upstream source packages also possible
In some rare cases the upstream project may be split across multiple git repositories or the upstream release may consist of multiple components each in their own separate tarball. Usually these are very large projects that get some benefits from releasing components separately. If in Debian these are deemed to go into a single source package, it is technically possible using the component system in git-buildpackage and uscan. For an example see the gbp.conf and watch files in the node-cacache package.
Using this type of structure should be a last resort, as it creates complexity and inter-dependencies that are bound to cause issues later on. It is usually better to work with upstream and champion universal best practices with clear releases and version schemes.
When not to start the Debian packaging repository as a fork of the upstream one
Not all upstreams use Git for version control. It is by far the most popular, but there are still some that use e.g. Subversion or Mercurial. Who knows — maybe in the future some new version control systems will start to compete with Git. There are also projects that use Git in massive monorepos and with complex submodule setups that invalidate the basic assumptions required to map an upstream Git repository into a Debian packaging repository.
In those cases one can’t use a debian/latest branch on a clone of the upstream git repository as the starting point for the Debian packaging, but one must revert the traditional way of starting from an upstream release tarball with gbp import-orig package-1.0.tar.gz.
Conclusion
Created in August 1993, Debian is one of the oldest Linux distributions. In the 32 years since inception, the .deb packaging format and the tooling to work with it have evolved several generations. In the past 10 years, more and more Debian Developers have converged on certain core practices evidenced by https://trends.debian.net/, but there is still a lot of variance in workflows even for identical tasks. Hopefully, you find this post useful in giving practical guidance on how exactly to do the most common things when packaging software for Debian.
I just released yesterday a new version of Corydalis
(https://demo.corydalis.io,
https://github.com/iustin/corydalis). To me personally, it’s a major
improvement, since the native (my own) image viewer finally gets
zooming, panning, gesture handling, etc. This is table-stakes for an
image viewer, but oh well, it took me a long time to implement it,
because of multiple things: lack of time, the JS library I was using
for gestures was pretty old and unmaintained and it caused more
trouble than was helping, etc.
The feature is not perfect, and on the demo site there’s already a bug
since all images are smaller than the screen, and this I didn’t test
😅, so double-click to zoom doesn’t work: says “Already at minimum
zoom�, but zooming otherwise (+/- on the keyboard, mouse wheel,
gesture) works.
End-to-end, the major development for this release was done over
around two weeks, which is pretty short: I extensively used Claude
Sonnet and Grok to unblock myself. Not to write code per se - although
there is code written 1:1 by LLMs, but most of the code is weirdly
wrong, and I have to either correct it or just use it as a starter and
rewrite most of it. But to discuss and unblock, and learn about new
things, the current LLMs are very good at.
And yet, sometimes even what they’re good at, fails hard. I asked for
ideas to simplify a piece of code, and it went nowhere, even if there
were significant rewrite possibilities. I spent the brain cycles on
it, reverse engineered my own code, then simplified. I’ll have to
write a separate blog post on this…
In any case, this (zooming) was the last major feature I was
missing. There are image viewer libraries, but most of them slow,
compared to the bare-bones (well, now not so much anymore) viewer that
I use as main viewer. From now on, it will me minor incremental
features, mostly around Exif management/handling, etc. Or, well,
internal cleanups: extend test coverage, remove use of JQuery in the
frontend, etc., there are tons of things to do.
Fun fact: I managed to discover a Safari iOS bug. Or at least I think
it’s a bug, so reported
it and curious
what’ll come out of it.
Finally, I still couldn’t fix the GitHub actions bug where the git
describe doesn’t see the just pushed tag, sigh, so the demo site still
lists Corydalis v2024.12.0-133-g00edf63 as the version 😅
Author: Lydia Cline He had always had a quiet appreciation for blue. Not loudly, he would never be as conformist as to declare a love for, like, the number one colour for boys and men. No – he was loud in his love for green – the thinking man’s blue. And yet, as he stared […]
Nathan Gardels – editor of Noema magazine – offers in an issue a glimpse of the latest philosopher with a theory of history, or historiography. One that I'll briefly critique soon, as it relates much to today's topic. But first...
In a previous issue, Gardels offered valuable and wise insights about America’s rising cultural divide, leading to what seems to be a rancorous illiberal democracy.
Any glance at the recent electoral stats shows that while race & gender remain important issues, they did not affect outcomes as much as a deepening polar divide between America’s social castes, especially the less-educated vs. more-educated.
Although he does not refer directly to Marx, he is talking about a schism that my parents understood... between advanced proletariate and ignorant lumpen-proletariate.
Hey, this is not another of my finger-wagging lectures, urging you all to at least understand some basic patterns that the WWII generation knew very well, when they designed the modern world.
Still, you could start with Nathan's essay...
...though alas, in focusing on that divide, I'm afraid Nathan accepts an insidious premise. Recall that there is a third party to this neo-Marxian class struggle, that so many describe as simply polar.
== Start by stepping way back ==
There’s a big context, rooted in basic biology. Nearly all species have their social patterns warped by male reproductive strategies, mostly by males applying power against competing males.
(Regretable? Sure. Then let's over-rule Nature by becoming better. But that starts by looking at and understanding the hand that evolution dealt us.)
Among humans, this manifested for much more than 6000 years as feudal dominance by local gangs, then aristocracies, and then kings intent upon one central goal -- to ensure that their sons would inherit power.
Looking across all that time, till the near-present, I invite you to find any exceptions among societies with agriculture. That is, other than Periclean Athens and (maybe) da Vinci's Florence. This pattern - dominating nearly all continents and 99% of cultures across those 60 centuries is a dismal litany of malgovernance called 'history'. (And now it dominates the myths conveyed by Hollywood.)
Alas, large-scale history is never (and I mean never) discussed these days, even though variants of feudalism make up the entire backdrop -- the default human condition -- against which our recent Enlightenment has been a miraculous - but always threatened - experimental alternative.
The secret sauce of the Enlightenment, described by Adam Smith and established (at first crudely) by the U.S. Founders, consists of flattening the caste-order. Breaking up power into rival elites -- siccing them against each other in fair competition, and basing success far less on inheritance than other traits.
That, plus the empowerment of new players... an educated meritocracy in science, commerce, civil service and even the military. And gradually helping the children of the poor and former slaves to participate.
This achievement did augment with each generation – way too slowly, but incrementally – till the World War II Greatest Generation’s GI Bill and massive universities and then desegregation took it skyward, making America truly the titan of all ages and eras.
Karl Marx - whose past-oriented appraisals of class conflict were brilliant - proved to be a bitter, unimaginative dope when it came to projecting forward the rise of an educated middle class...
…which was the great innovation of the Roosevelteans, inviting the working classes into a growing and thriving middle class..
... an unexpected move that consigned Marx to the dustbin for 80 years...
... till his recent resurrection all around the globe, for reasons given below.
== There are three classes tussling here, not two ==
Which brings us to where Nathan Gardels’s missive is just plain wrong, alas. Accepting a line of propaganda that is now universally pervasive – he asserts that two – and only two – social classes are involved in a vast – socially antagonistic and polar struggle.
Are the lower middle classes (lumpenproletariat) currently at war against 'snooty fact elites'?Sure, they are!But so many post-mortems of the recent U.S. election blame the fact-professionals themselves, for behaving in patronizing ways toward working stiffs.
Meanwhile, such commentaries leave out entirely any mention of a 3rd set of players...
... the oligarchs, hedge lords, inheritance brats, sheiks and “ex”-commissars who have united in common cause. Those who stand most to benefit from dissonance within the bourgeoisie!
Elites who have been the chief beneficiaries of the last 40 years of 'supply side' and other tax grifts. Whose wealth disparities long ago surpassed those preceding the French Revolution. Many of whom are building lavish ‘prepper bunkers.' And who now see just one power center blocking their path to complete restoration of the default human system – feudal rule by inherited privilege.
That obstacle to feudal restoration? The fact professionals,whose use of science, plus rule-of-law and universities – plus uplift of poor children - keeps the social flatness prescription of Adam Smith alive.
And hence, those elites lavishly subsidize a world campaign to rile up lumpenprol resentment against science, law, medicine, civil servants... and yes, now the FBI and Intel and military officer corps.
A campaign that's been so successful that the core fact of this recent election – the way all of the adults in the first Trump Administration denounced him – is portrayed as a feature by today’s Republicans, rather than a fault. And yes, that is why none of the new Trump Appointees will ever, ever be adults-in-the-room.
== The ultimate, ironic revival of Marx, by those who should fear him most ==
Seriously. You can't see this incitement campaign in every evening's tirades, on Fox? Or spuming across social media, where ‘drinking the tears of know-it-alls’ is the common MAGA victory howl?
A hate campaign against snobby professionals that is vastly more intensive than any snide references to race or gender?
I beg you to control your gorge and actually watch Fox etc. Try actually counting the minutes spent exploiting the natural American SoA reflex (Suspicion of Authority) that I discuss in Vivid Tomorrows.A reflex which could become dangerous to oligarchs, if ever it turned on them!
And hence it must be diverted into rage and all-out war vs. all fact-using professions, from science and teaching, medicine and law and civil service to the heroes of the FBI/Intel/Military officer corps who won the Cold War and the War on terror.
To be clear, there are some professionals who have behaved stupidly, looking down their noses at the lower middle class.
Just as there are poor folks who appreciate their own university-educated kids, instead of resenting them.
And yes, there are scions of inherited wealth or billionaires (we know more than a few!) who are smart and decent enough to side with an Enlightenment that's been very good to them.
Alas, the agitprop campaign that I described here has been brilliantly successful, including massively popular cultural works extolling feudalism as the natural human forms of governance. (e.g. Tolkien, Dune, Star Wars, Game of Thrones... and do you seriously need more examples in order to realize that it's deliberate?)
They aren’t wrong! Feudalism is the ‘natural’ form of human governance.
In fact, its near universality may be a top theory to explain the Fermi Paradox!
… A trap/filter that prevents any race from rising to the stars.
== Would I rather not have been right? ==
One of you pointed out "Paul Krugman's post today echoes Dr B's warnings aboutMAGA vs Science.":
"But why do our new rulers want to destroy science in America? Sadly, the answer is obvious: Science has a tendency to tell you things you may not want to hear. .... And one thing we know about MAGA types is that they are determined to hold on to their prejudices. If science conflicts with those prejudices, they don’t want to know, and they don’t want anyone else to know either."
Krugman is the smartest current acolyte of Hari Seldon. Except maybe for Robert Reich. And still, they don't see the big picture.
== Stop giving the first-estate a free pass ==
And so, I conclude.
Whenever you find yourself discussing class war between the lower proletariats and snooty bourgeoisie, remember that the nomenclature – so strange and archaic-sounding, today – was quite familiar to our parents and grandparents.
Moreover, it included a third caste! The almost perpetual winners, across 600 decades. The bane on fair competition that was diagnosed by both Adam Smith and Karl Marx. And one that's deeply suicidal, as today's moguls - masturbating to the chants of flatterers - seem determined to repeat every mistake that led their predecessors to tumbrels and guillotines.
With some exceptions – those few who are truly noble of mind and heart – they are right now busily resurrecting every Marxian scenario from the grave…
… or from torpor where they had been cast by the Roosevelteans.
And the rich fools are doing so by fomenting longstanding cultural grudges for – or against – modernity.
The same modernity that gave them everything they have and that laid all of their golden eggs.
If anything proves the inherent stupidity of that caste – (most of them) - it is their ill-education about Marx! And what he will mean to new generations, if the Enlightenment cannot be recharged and restored enough to put old Karl back to sleep.
In this post, I demonstrate the optimal workflow for creating new Debian packages in 2025, preserving the upstream git history. The motivation for this is to lower the barrier for sharing improvements to and from upstream, and to improve software provenance and supply-chain security by making it easy to inspect every change at any level using standard git tooling.
Key elements of this workflow include:
Using a Git fork/clone of the upstream repository as the starting point for creating Debian packaging repositories.
Consistent use of the same git-buildpackage commands, with all package-specific options in gbp.conf.
Pristine-tar and upstream signatures for supply-chain security.
Use of Files-Excluded in the debian/copyright file to filter out unwanted files in Debian.
Patch queues to easily rebase and cherry-pick changes across Debian and upstream branches.
Efficient use of Salsa, Debian’s GitLab instance, for both automated feedback from CI systems and human feedback from peer reviews.
To make the instructions so concrete that anyone can repeat all the steps themselves on a real package, I demonstrate the steps by packaging the command-line tool Entr. It is written in C, has very few dependencies, and its final Debian source package structure is simple, yet exemplifies all the important parts that go into a complete Debian package:
Creating a new packaging repository and publishing it under your personal namespace on salsa.debian.org.
Using dh_make to create the initial Debian packaging.
Posting the first draft of the Debian packaging as a Merge Request (MR) and using Salsa CI to verify Debian packaging quality.
Running local builds efficiently and iterating on the packaging process.
Create new Debian packaging repository from the existing upstream project git repository
First, create a new empty directory, then clone the upstream Git repository inside it:
Using a clean directory makes it easier to inspect the build artifacts of a Debian package, which will be output in the parent directory of the Debian source directory.
The extra parameters given to git clone lay the foundation for the Debian packaging git repository structure where the upstream git remote name is upstreamvcs. Only the upstream main branch is tracked to avoid cluttering git history with upstream development branches that are irrelevant for packaging in Debian.
Next, enter the git repository directory and list the git tags. Pick the latest upstream release tag as the commit to start the branch upstream/latest. This latest refers to the upstream release, not the upstream development branch. Immediately after, branch off the debian/latest branch, which will have the actual Debian packaging files in the debian/ subdirectory.
shellcd entr
git tag # shows the latest upstream release tag was '5.6'
git checkout -b upstream/latest 5.6
git checkout -b debian/latest
cd entr
git tag # shows the latest upstream release tag was '5.6'git checkout -b upstream/latest 5.6
git checkout -b debian/latest
At this point, the repository is structured according to DEP-14 conventions, ensuring a clear separation between upstream and Debian packaging changes, but there are no Debian changes yet. Next, add the Salsa repository as a new remote which called origin, the same as the default remote name in git.
This is an important preparation step to later be able to create a Merge Request on Salsa that targets the debian/latest branch, which does not yet have any debian/ directory.
Launch a Debian Sid (unstable) container to run builds in
To ensure that all packaging tools are of the latest versions, run everything inside a fresh Sid container. This has two benefits: you are guaranteed to have the most up-to-date toolchain, and your host system stays clean without getting polluted by various extra packages. Additionally, this approach works even if your host system is not Debian/Ubuntu.
cd ..
podman run --interactive --tty --rm --shm-size=1G --cap-add SYS_PTRACE \
--env='DEB*' --volume=$PWD:/tmp/test --workdir=/tmp/test debian:sid bash
Note that the container should be started from the parent directory of the git repository, not inside it. The --volume parameter will loop-mount the current directory inside the container. Thus all files created and modified are on the host system, and will persist after the container shuts down.
Once inside the container, install the basic dependencies:
To create the files needed for the actual Debian packaging, use dh_make:
shell# dh_make --packagename entr_5.6 --single --createorig
Maintainer Name : Otto Kekäläinen
Email-Address : otto@debian.org
Date : Sat, 15 Feb 2025 01:17:51 +0000
Package Name : entr
Version : 5.6
License : blank
Package Type : single
Are the details correct? [Y/n/q]
Done. Please edit the files in the debian/ subdirectory now.
# dh_make --packagename entr_5.6 --single --createorigMaintainer Name : Otto Kekäläinen
Email-Address : otto@debian.org
Date : Sat, 15 Feb 2025 01:17:51 +0000
Package Name : entr
Version : 5.6
License : blank
Package Type : single
Are the details correct? [Y/n/q]Done. Please edit the files in the debian/ subdirectory now.
Due to how dh_make works, the package name and version need to be written as a single underscore separated string. In this case, you should choose --single to specify that the package type is a single binary package. Other options would be --library for library packages (see libgda5 sources as an example) or --indep (see dns-root-data sources as an example). The --createorig will create a mock upstream release tarball (entr_5.6.orig.tar.xz) from the current release directory, which is necessary due to historical reasons and how dh_make worked before git repositories became common and Debian source packages were based off upstream release tarballs (e.g. *.tar.gz).
At this stage, a debian/ directory has been created with template files, and you can start modifying the files and iterating towards actual working packaging.
shellgit add debian/
git commit -a -m "Initial Debian packaging"
git add debian/
git commit -a -m "Initial Debian packaging"
Review the files
The full list of files after the above steps with dh_make would be:
All the other files have been created for convenience so the packager has template files to work from. The files with the suffix .ex are example files that won’t have any effect until their content is adjusted and the suffix removed.
For detailed explanations of the purpose of each file in the debian/ subdirectory, see the following resources:
The Debian Policy Manual: Describes the structure of the operating system, the package archive and requirements for packages to be included in the Debian archive.
The Developer’s Reference: A collection of best practices and process descriptions Debian packagers are expected to follow while interacting with one another.
Debhelper man pages: Detailed information of how the Debian package build system works, and how the contents of the various files in ‘debian/’ affect the end result.
Most of these files have standardized formatting conventions to make collaboration easier. To automatically format the files following the most popular conventions, simply run wrap-and-sort -vast or debputy reformat --style=black.
Identify build dependencies
The most common reason for builds to fail is missing dependencies. The easiest way to identify which Debian package ships the required dependency is using apt-file. If, for example, a build fails complaining that pcre2posix.h cannot be found or that libcre2-posix.so is missing, you can use these commands:
The output above implies that the debian/control should be extended to define a Build-Depends: libpcre2-dev relationship.
There is also dpkg-depcheck that uses strace to trace the files the build process tries to access, and lists what Debian packages those files belong to. Example usage:
shelldpkg-depcheck -b debian/rules build
dpkg-depcheck -b debian/rules build
Build the Debian sources to generate the .deb package
After the first pass of refining the contents of the files in debian/, test the build by running dpkg-buildpackage inside the container:
shelldpkg-buildpackage -uc -us -b
dpkg-buildpackage -uc -us -b
The options -uc -us will skip signing the resulting Debian source package and other build artifacts. The -b option will skip creating a source package and only build the (binary) *.deb packages.
The output is very verbose and gives a large amount of context about what is happening during the build to make debugging build failures easier. In the build log of entr you will see for example the line dh binary --buildsystem=makefile. This and other dh commands can also be run manually if there is a need to quickly repeat only a part of the build while debugging build failures.
To see what files were generated or modified by the build simply run git status --ignored:
shell$ git status --ignored
On branch debian/latest
Untracked files:
(use "git add <file>..." to include in what will be committed)
debian/debhelper-build-stamp
debian/entr.debhelper.log
debian/entr.substvars
debian/files
Ignored files:
(use "git add -f <file>..." to include in what will be committed)
Makefile
compat.c
compat.o
debian/.debhelper/
debian/entr/
entr
entr.o
status.o
$ git status --ignored
On branch debian/latest
Untracked files:
(use "git add <file>..." to include in what will be committed) debian/debhelper-build-stamp
debian/entr.debhelper.log
debian/entr.substvars
debian/files
Ignored files:
(use "git add -f <file>..." to include in what will be committed) Makefile
compat.c
compat.o
debian/.debhelper/
debian/entr/
entr
entr.o
status.o
Re-running dpkg-buildpackage will include running the command dh clean, which assuming it is configured correctly in the debian/rules file will reset the source directory to the original pristine state. The same can of course also be done with regular git commands git reset --hard; git clean -fdx. To avoid accidentally committing unnecessary build artifacts in git, a debian/.gitignore can be useful and it would typically include all four files listed as “untracked” above.
After a successful build you would have the following files:
The contents of debian/entr are essentially what goes into the resulting entr_5.6-1_amd64.deb package. Familiarizing yourself with the majority of the files in the original upstream source as well as all the resulting build artifacts is time consuming, but it is a necessary investment to get high-quality Debian packages.
There are also tools such as Debcraft that automate generating the build artifacts in separate output directories for each build, thus making it easy to compare the changes to correlate what change in the Debian packaging led to what change in the resulting build artifacts.
Re-run the initial import with git-buildpackage
When upstreams publish releases as tarballs, they should also be imported for optimal software supply-chain security, in particular if upstream also publishes cryptographic signatures that can be used to verify the authenticity of the tarballs.
To achieve this, the files debian/watch, debian/upstream/signing-key.asc, and debian/gbp.conf need to be present with the correct options. In the gbp.conf file, ensure you have the correct options based on:
Does upstream release tarballs? If so, enforce pristine-tar = True.
Does upstream sign the tarballs? If so, configure explicit signature checking with upstream-signatures = on.
Does upstream have a git repository, and does it have release git tags? If so, configure the release git tag format, e.g. upstream-vcs-tag = %(version%~%.)s.
To validate that the above files are working correctly, run gbp import-orig with the current version explicitly defined:
shell$ gbp import-orig --uscan --upstream-version 5.6
gbp:info: Launching uscan...
gpgv: Signature made 7. Aug 2024 07.43.27 PDT
gpgv: using RSA key 519151D83E83D40A232B4D615C418B8631BC7C26
gpgv: Good signature from "Eric Radman <ericshane@eradman.com>"
gbp:info: Using uscan downloaded tarball ../entr_5.6.orig.tar.gz
gbp:info: Importing '../entr_5.6.orig.tar.gz' to branch 'upstream/latest'...
gbp:info: Source package is entr
gbp:info: Upstream version is 5.6
gbp:info: Replacing upstream source on 'debian/latest'
gbp:info: Running Postimport hook
gbp:info: Successfully imported version 5.6 of ../entr_5.6.orig.tar.gz
$ gbp import-orig --uscan --upstream-version 5.6
gbp:info: Launching uscan...
gpgv: Signature made 7. Aug 2024 07.43.27 PDT
gpgv: using RSA key 519151D83E83D40A232B4D615C418B8631BC7C26
gpgv: Good signature from "Eric Radman <ericshane@eradman.com>"gbp:info: Using uscan downloaded tarball ../entr_5.6.orig.tar.gz
gbp:info: Importing '../entr_5.6.orig.tar.gz' to branch 'upstream/latest'...
gbp:info: Source package is entr
gbp:info: Upstream version is 5.6
gbp:info: Replacing upstream source on 'debian/latest'gbp:info: Running Postimport hook
gbp:info: Successfully imported version 5.6 of ../entr_5.6.orig.tar.gz
As the original packaging was done based on the upstream release git tag, the above command will fetch the tarball release, create the pristine-tar branch, and store the tarball delta on it. This command will also attempt to create the tag upstream/5.6 on the upstream/latest branch.
Import new upstream versions in the future
Forking the upstream git repository, creating the initial packaging, and creating the DEP-14 branch structure are all one-off work needed only when creating the initial packaging.
Going forward, to import new upstream releases, one would simply run git fetch upstreamvcs; gbp import-orig --uscan, which fetches the upstream git tags, checks for new upstream tarballs, and automatically downloads, verifies, and imports the new version. See the galera-4-demo example in the Debian source packages in git explained post as a demo you can try running yourself and examine in detail.
You can also try running gbp import-orig --uscan without specifying a version. It would fetch it, as it will notice there is now Entr version 5.7 available, and import it.
Build using git-buildpackage
From this stage onwards you should build the package using gbp buildpackage, which will do a more comprehensive build.
shellgbp buildpackage -uc -us
gbp buildpackage -uc -us
The git-buildpackage build also includes running Lintian to find potential Debian policy violations in the sources or in the resulting .deb binary packages. Many Debian Developers run lintian -EviIL +pedantic after every build to check that there are no new nags, and to validate that changes intended to previous Lintian nags were correct.
Open a Merge Request on Salsa for Debian packaging review
Getting everything perfectly right takes a lot of effort, and may require reaching out to an experienced Debian Developers for review and guidance. Thus, you should aim to publish your initial packaging work on Salsa, Debian’s GitLab instance, for review and feedback as early as possible.
For somebody to be able to easily see what you have done, you should rename your debian/latest branch to another name, for example next/debian/latest, and open a Merge Request that targets the debian/latest branch on your Salsa fork, which still has only the unmodified upstream files.
If you have followed the workflow in this post so far, you can simply run:
git checkout -b next/debian/latest
git push --set-upstream origin next/debian/latest
Open in a browser the URL visible in the git remote response
Write the Merge Request description in case the default text from your commit is not enough
Mark the MR as “Draft” using the checkbox
Publish the MR and request feedback
Once a Merge Request exists, discussion regarding what additional changes are needed can be conducted as MR comments. With an MR, you can easily iterate on the contents of next/debian/latest, rebase, force push, and request re-review as many times as you want.
While at it, make sure the Settings > CI/CD page has under CI/CD configuration file the value debian/salsa-ci.yml so that the CI can run and give you immediate automated feedback.
Open a Merge Request / Pull Request to fix upstream code
Due to the high quality requirements in Debian, it is fairly common that while doing the initial Debian packaging of an open source project, issues are found that stem from the upstream source code. While it is possible to carry extra patches in Debian, it is not good practice to deviate too much from upstream code with custom Debian patches. Instead, the Debian packager should try to get the fixes applied directly upstream.
Using git-buildpackage patch queues is the most convenient way to make modifications to the upstream source code so that they automatically convert into Debian patches (stored at debian/patches), and can also easily be submitted upstream as any regular git commit (and rebased and resubmitted many times over).
First, decide if you want to work out of the upstream development branch and later cherry-pick to the Debian packaging branch, or work out of the Debian packaging branch and cherry-pick to an upstream branch.
The example below starts from the upstream development branch and then cherry-picks the commit into the git-buildpackage patch queue:
shellgit checkout -b bugfix-branch master
nano entr.c
make
./entr # verify change works as expected
git commit -a -m "Commit title" -m "Commit body"
git push # submit upstream
gbp pq import --force --time-machine=10
git cherry-pick <commit id>
git commit --amend # extend commit message with DEP-3 metadata
gbp buildpackage -uc -us -b
./entr # verify change works as expected
gbp pq export --drop --commit
git commit --amend # Write commit message along lines "Add patch to .."
git checkout -b bugfix-branch master
nano entr.c
make
./entr # verify change works as expectedgit commit -a -m "Commit title" -m "Commit body"git push # submit upstreamgbp pq import --force --time-machine=10git cherry-pick <commit id>
git commit --amend # extend commit message with DEP-3 metadatagbp buildpackage -uc -us -b
./entr # verify change works as expectedgbp pq export --drop --commit
git commit --amend # Write commit message along lines "Add patch to .."
The example below starts by making the fix on a git-buildpackage patch queue branch, and then cherry-picking it onto the upstream development branch:
These can be run at any time, regardless if any debian/patches existed prior, or if existing patches applied cleanly or not, or if there were old patch queue branches around. Note that the extra -b in gbp buildpackage -uc -us -b instructs to build only binary packages, avoiding any nags from dpkg-source that there are modifications in the upstream sources while building in the patches-applied mode.
Programming-language specific dh-make alternatives
As each programming language has its specific way of building the source code, and many other conventions regarding the file layout and more, Debian has multiple custom tools to create new Debian source packages for specific programming languages.
Notably, Python does not have its own tool, but there is an dh_make --python option for Python support directly in dh_make itself. The list is not complete and many more tools exist. For some languages, there are even competing options, such as for Go there is in addition to dh-make-golang also Gophian.
When learning Debian packaging, there is no need to learn these tools upfront. Being aware that they exist is enough, and one can learn them only if and when one starts to package a project in a new programming language.
The difference between source git repository vs source packages vs binary packages
As seen in earlier example, running gbp buildpackage on the Entr packaging repository above will result in several files:
The entr_5.6-1_amd64.deb is the binary package, which can be installed on a Debian/Ubuntu system. The rest of the files constitute the source package. To do a source-only build, run gbp buildpackage -S and note the files produced:
The source package files can be used to build the binary .deb for amd64, or any architecture that the package supports. It is important to grasp that the Debian source package is the preferred form to be able to build the binary packages on various Debian build systems, and the Debian source package is not the same thing as the Debian packaging git repository contents.
If the package is large and complex, the build could result in multiple binary packages. One set of package definition files in debian/ will however only ever result in a single source package.
Option to repackage source packages with Files-Excluded lists in the debian/copyright file
Some upstream projects may include binary files in their release, or other undesirable content that needs to be omitted from the source package in Debian. The easiest way to filter them out is by adding to the debian/copyright file a Files-Excluded field listing the undesired files. The debian/copyright file is read by uscan, which will repackage the upstream sources on-the-fly when importing new upstream releases.
The resulting repackaged upstream source tarball, as well as the upstream version component, will have an extra +ds to signify that it is not the true original upstream source but has been modified by Debian:
godot_4.3+ds.orig.tar.xz
godot_4.3+ds-1_amd64.deb
godot_4.3+ds.orig.tar.xz
godot_4.3+ds-1_amd64.deb
Creating one Debian source package from multiple upstream source packages also possible
In some rare cases the upstream project may be split across multiple git repositories or the upstream release may consist of multiple components each in their own separate tarball. Usually these are very large projects that get some benefits from releasing components separately. If in Debian these are deemed to go into a single source package, it is technically possible using the component system in git-buildpackage and uscan. For an example see the gbp.conf and watch files in the node-cacache package.
Using this type of structure should be a last resort, as it creates complexity and inter-dependencies that are bound to cause issues later on. It is usually better to work with upstream and champion universal best practices with clear releases and version schemes.
When not to start the Debian packaging repository as a fork of the upstream one
Not all upstreams use Git for version control. It is by far the most popular, but there are still some that use e.g. Subversion or Mercurial. Who knows — maybe in the future some new version control systems will start to compete with Git. There are also projects that use Git in massive monorepos and with complex submodule setups that invalidate the basic assumptions required to map an upstream Git repository into a Debian packaging repository.
In those cases one can’t use a debian/latest branch on a clone of the upstream git repository as the starting point for the Debian packaging, but one must revert the traditional way of starting from an upstream release tarball with gbp import-orig package-1.0.tar.gz.
Conclusion
Created in August 1993, Debian is one of the oldest Linux distributions. In the 32 years since inception, the .deb packaging format and the tooling to work with it have evolved several generations. In the past 10 years, more and more Debian Developers have converged on certain core practices evidenced by https://trends.debian.net/, but there is still a lot of variance in workflows even for identical tasks. Hopefully, you find this post useful in giving practical guidance on how exactly to do the most common things when packaging software for Debian.
After cartridge pleating, the next fabric manipulation technique I
wanted to try was smocking, of the honeycombing variety, on a shirt.
My current go-to pattern for shirts is the 1880 menswear one
I have on my website: I love the fact that most of the fabric is still
cut as big rectangles, but the shaped yoke and armscyes make it
significantly more comfortable than the earlier style where most of the
shaping at the neck was done with gathers into a straight collar.
In my stash I had a cut of purple-blue hopefully cotton [#cotton] I had
bought for a cheap price and used for my first attempt at an
historically accurate pirate / vampire shirt that has now become by
official summer vaccine jab / blood test shirt (because it has the long
sleeves I need, but they are pretty easy to roll up to give access to my
arm.
That shirt tends to get out of the washing machine pretty wearable even
without ironing, which made me think it could be a good fabric for
something that may be somewhat hard to iron (but also made me
suspicious about the actual composition of the fabric, even if it feels
nice enough even when worn in the summer).
Of course I wanted some honeycombing on the front, but I was afraid that
the slit in the middle of it would interfere with the honeycombing and
gape, so I decided to have the shirt open in an horizontal line at the
yoke.
I added instructions to the pattern page
for how I changed the opening in the front, basically it involved
finishing the front edge of the yoke, and sewing the honeycombed yoke to
a piece of tape with snaps.
Another change from the pattern is that I used plain rectangles for the
sleeves, and a square gusset, rather than the new style tapered sleeve ,
because I wanted to have more fabric to gather at the wrist. I did the
side and sleeve seams with a hem + whipstitch method rather than a
felled seam, which may have helped, but the sleeves went into the
fitted armscyes with no issue.
I think that if (yeah, right. when) I’ll make another sleeve in this
style I’ll sew it into the side seam starting 2-3 cm lower than the
place I’ve marked on the pattern for the original sleeve.
I also used a row of honeycombing on the back and two on the upper part
of the sleeves, instead of the gathering, and of course some rows to
gather the cuffs.
The honeycombing on the back was a bit too far away from the edge, so
it’s a bit of an odd combination of honeycombing and pleating that I
don’t hate, but don’t love either. It’s on the back, so I don’t mind. On
the sleeves I’ve done the honeycombing closer to the edge and I’ve
decided to sew the sleeve as if it was a cartridge pleated sleeve, and
that worked better.
Because circumstances are still making access to my sewing machine
more of a hassle than I’d want it to be, this was completely sewn by
hand, and at a bit more than a month I have to admit that near the end
it felt like it had been taken forever. I’m not sure whether it was the
actual sewing being slow, some interruptions that happened when I had
little time to work on it, or the fact that I’ve just gone through a
time when my brain kept throwing new projects at me, and I kept thinking
of how to make those. Thanks brain.
Even when on a hurry to finish it, however, it was still enjoyable
sewing, and I think I’ll want to do more honeycombing in the future.
Anyway, it’s done! And it’s going straight into my daily garment
rotation, because the weather is getting hot, and that means it’s
definitely shirt time.
A discussion the other day made me remember some of the demoparty stream
“first” that I'm still proud of, most of which still haven't been matched:
Live voting user counts during the compo
(example, at the bottom).
A combination of gamification and deliberate peer pressure; if you see that
others are voting, you'll feel compelled to follow their example. (The
counter would never go down during a compo, only up, even if people stopped
adding new votes. Also deliberate.)
Locking the frame rate to the compo machine throughout the entire chain;
in practice, this means that oldschool demos would come in 50 Hz and
newschool in 60 Hz, creating a fully VFR stream. A pain during switches,
and YouTube messes it up and makes the entire file a bit choppy, but so
cool. If always wanted it to do the infamous 50.12 Hz from C64, but never
really figured it out.
And last but not least, the “Eurovision” effect. Don't remember which entry
was which during voting? No problem, we wget a 10-second sample (the
advantage of having software video mixing for the bigscreen!) during the
compo, furiously transcode it to something reasonable on an Arm thingie,
and then put a loop of all of them together at the end of the compo.
(A glimpse of an example)
Oh, and we streamed the street basketball compo, of course.
Through a terrible, terrible video chain that made everything choppy.
Would do better if I ever did it again :-)
As you may recall from previous posts and elsewhere I have been busy writing a new solver for APT.
Today I want to share some of the latest changes in how to approach solving.
The idea for the solver was that manually installed packages are always protected from removals –
in terms of SAT solving, they are facts. Automatically installed packages become optional unit
clauses. Optional clauses are solved after manual ones, they don’t partake in normal unit propagation.
This worked fine, say you had
A # install request for A
B # manually installed, keep it
A depends on: conflicts-B | C
Installing A on a system with B installed installed C, as it was not allowed to
install the conflicts-B package since B is installed.
However, I also introduced a mode to allow removing manually installed packages, and that’s
where it broke down, now instead of B being a fact, our clauses looked like:
A # install request for A
A depends on: conflicts-B | C
Optional: B # try to keep B installed
As a result, we installed conflicts-B and removed B; the steps the solver takes are:
A is a fact, mark it
A depends on: conflicts-B | C is the strongest clause, try to install conflicts-B
We unit propagate that conflicts-B conflicts with B, so we mark not B
Optional: B is reached, but not satisfiable, ignore it because it’s optional.
This isn’t correct: Just because we allow removing manually installed packages doesn’t mean that we should remove manually installed packages if we don’t need to.
Fixing this turns out to be surprisingly easy. In addition to adding our optional (soft) clauses, let’s first assume all of them!
But to explain how this works, we first need to explain some terminology:
The solver operates on a stack of decisions
“enqueue” means a fact is being added at the current decision level, and enqueued for propagation
“assume” bumps the decision level, and then enqueues the assumed variable
“propagate” looks at all the facts and sees if any clause becomes unit, and then enqueues it
“unit” is when a clause has a single literal left to assign
To illustrate this in pseudo Python code:
We introduce all our facts, and if they conflict, we are unsat:
for fact in facts:
enqueue(fact)
ifnot propagate():
returnFalse
For each optional literal, we register a soft clause and assume it. If the assumption fails,
we ignore it. If it succeeds, but propagation fails, we undo the assumption.
for optionalLiteral in optionalLiterals:
registerClause(SoftClause([optionalLiteral]))
if assume(optionalLiteral) andnot propagate():
undo()
Finally we enter the main solver loop:
whileTrue:
ifnot propagate():
ifnot backtrack():
returnFalseelif<all clauses are satisfied>:
returnTrueelif it := find("best unassigned literal satisfying a hard clause"):
assume(it)
elif it := find("best literal satisfying a soft clause"):
assume(it)
The key point to note is that the main loop will undo the assumptions in order; so
if you assume A,B,C and B is not possible, we will have also undone C. But since
C is also enqueued as a soft clause, we will then later find it again:
Solve finds a conflict, backtracks, and sets not C: State=[Assume(A),Assume(B),not(C)]
Solve finds a conflict, backtracks, and sets not B: State=[Assume(A),not(B)] – C is no longer assumed either
Solve, assume C as it satisfies SoftClause([C]) as next best literal: State=[Assume(A),not(B),Assume(C)]
All clauses are satisfied, solution is A, not B, and C.
This is not (correct) MaxSAT, because we actually do not guarantee that we satisfy as many soft clauses as possible. Consider you have the following clauses:
Optional: A
Optional: B
Optional: C
B Conflicts with A
C Conflicts with A
There are two possible results here:
{A} – If we assume A first, we are unable to satisfy B or C.
{B,C} – If we assume either B or C first, A is unsat.
The question to ponder though is whether we actually need a global maximum or whether a local maximum is satisfactory in practice for a dependency solver
If you look at it, a naive MaxSAT solver needs to run the SAT solver 2**n times for n soft clauses, whereas our heuristic only needs n runs.
For dependency solving, it seems we do not seem have a strong need for a global maximum:
There are various other preferences between our literals, say priorities;
and empirically, from evaluating hundreds of regressions without the initial assumptions,
I can say that the assumptions do fix those cases and the result is correct.
Further improvements exist, though, and we can look into them if they are needed, such as:
Use a better heuristic:
If we assume 1 clause and solve, and we cause 2 or more clauses to become unsatisfiable,
then that clause is a local minimum and can be skipped.
This is a more common heuristical MaxSAT solver.
This gives us a better local maximum, but not a global one.
This is more or less what the Smart package manager did,
except that in Smart, all packages were optional, and the entire solution was scored.
It calculated a basic solution without optimization and then toggled each variable and saw if the score improved.
Implement an actual search for a global maximum:
This involves reading the literature.
There are various versions of this, for example:
Find unsatisfiable cores and use those to guide relaxation of clauses.
A bounds-based search, where we translate sum(satisifed clauses) > k into SAT, and then search in one of the following ways:
from 0 upward
from n downward
perform a binary search on [0, k] satisfied clauses.
Actually we do not even need to calculate sum constraints into CNF, because we can just add a specialized new type of constraint to our code.
Author: Emily Kinsey “Jessie! Get over here, I think I found something!” Annoyed, Jessie said, “You always think you found something.” “It smells good,” I offered, hoping to entice him. It worked, because Jessie only ever cares about his stomach. He discarded his half-gnawed jerky and hobbled over to inspect my findings. “What’d you think […]
For a while, the strongSwan Debian package had an autopktest.
The initial version was proposed by Christian Ehrhardt in 2016
(presumably especially for downstream use in Ubuntu) and updated in
2019, but since then not much at least in Debian.
With the metapackage dependencies update in 6.0.0-1 I had to
tune a bit the tests dependencies so they wouldn't totally fail,
and I noticed the amd64 tests were failing since basically the
beginning (the other architectures would pass, but because the
tests wouldn't actually run at all since they rely on the
isolation-machine restriction which is
not available there.
So I tried to fix them, and it actually took me quite a while
because I wasn't able to run the tests locally easily and the salsa
CI doesn't have the isolation-machine
restriction either. And some tests would pass and not
other.
With some nice help from #debci, and using my newly receivedX13G5 I set
up an autopkgtest VM and started experimenting. The 6.0.0-4
autopkgtests were failing 19 times over 20 steps, but passing one
time. So it looked like a race condition, which we narrowed to the
fact that starting the daemons (using invoke-rc.d which calls systemctl) is asynchronous. So depending on the load
and maybe the machine, the tests would usually fail but sometime
pass.
There's no easy way to make the call synchronous, so as a
stopgap I added a small sleep 1 command and it fixed it for now.
Tada! strongSwan has now passing
autopkgtests in unstable (and testing) amd64. It's not entirely
satisfying but still.
Next steps would be to add tests for the new daemon using the
swanctl inteface, but that'll be for Forky (Trixie+1).
Mainly relevant for the few who still run their own mail server and use Postfix + pflogsumm.
Few weeks back Jim contacted me that he's going to pick up work on
pflogsumm again, and as first step
wanted to release 1.1.6 to incorporate patches from the Debian package. That
one is now released. Since
we're already in the Trixie freeze the package is in
experimental,
but as usual should be fine to install manually.
Heads Up - Move to /usr/bin
I took that as an opportunity to move pflogsumm from /usr/sbin to /usr/bin!
There was not really a good reason to ever have it in sbin. It's neither a system binary,
nor statically linked (like in the very old days), or something that really only makes sense
to be used as root. Some out there likely have custom scripts which do not rely on an
adjusted PATH variable, those scripts require an update.
Underqualified
Mike S.
is suffering a job hunt.
"I could handle uD83D and uDC77 well enough, but I am a little short
of uD83C and the all important uDFFE requirement."
Frank forecasts frustration.
"The weather app I'm using seems to be a bit confused on my location as I'm on vacation right now."
It would be a simple matter for the app to simply identify
each location, if it can't meaningfully choose only one.
Marc Würth
is making me hungry. Says Marc
"I was looking through my Evernote notes for "transactional" (email service). It didn't find anything. Evernote, though, tried to be helpful and thought I was looking for some basil (German "Basilikum")."
That is not the King,"
Brendan
commented.
"I posted this on Discord, and my friend responded with "They have
succeeded in alignment. Their AI is truly gender blind." Not only
gender-blind but apparently also existence-blind as well. I think the Bard might have
something quotable here as well but it escapes me. Comment section is open.
I have been a very happy user of my two SK-8845 keyboards (one at my
office, one at home) since I bought them, in 2018 and 2021
respectively. What are they, mind you?
)
The beautiful keyboard every Thinkpad owner knows and loves. And although I
no longer use my X230 laptop that was my workhorse for several years, my
fingers are spoiled.
So, both shift keys of my home keyboard have been getting flaky, and I
am basically sure it’s a failure in the controller, as it does not feel to
be physical. It’s time to revisit that seven year old
post
where I found the SK-8845.
This time, I decided to try my luck with something different. As a Emacs
user, everybody knows we ought to be happy with more and more keys. In
fact, I suppose many international people are now familiar with El
Eternauta, true? we Emacs users would be the natural ambassadors to deal
with the hand species:
So… it kind-of sort-of made sense, when I saw a Toshiba-IBM keyboard
being sold for quite cheap (MX$400, just over US$20) to try my luck with
it:
This is quite an odd piece of hardware, built in 2013 according to its
label. At first I was unsure whether to buy it because of the weird
interface it had, but the vendor replied they would ship a (very long!) USB
cable with it, so…
As expected, connecting it to Linux led to a swift, errorless recognition:
Within minutes of receiving the hardware, I had it hooked up and started
looking at the events it generated However… the romance soon started to
wane. Some of the reasons:
We cannot forget it is a Piece of Shit Point Of Sale keyboard. It is
not intended to be a creative interface. So, the keys are ~75% the size
of regular keys. My fingers have a hard time getting used to it, I keep
hitting wrong keys. I know “I am holding it wrong� and my muscle memory
can be retrained (and I was very happy when I had the tiny 9� Acer Aspire
One)… but still, it is not pleasant.
I exclusively use keyboards with a trackpad (as those found in most
laptops) because I found that constantly moving my hand to the mouse and
back produced me back ache. Within an hour of typing in this keyboard,
the old back ache I was happy not to ever have again came back to me.
The pointer device has a left and a right button, but neither middle nor
scroll buttons. I could generate middle clicks by setting middle
emulation enabled, but the buttons are separated — it requires clicking
with both thumbs, which is unelegant, to say the least.
I remapped some of the spare keys to be mouse buttons 1–5, and it worked
for middle click, but not for scroll events. Maybe I could tweak it a bit
more… but I didn’t in the end.
Author: Stephen C. Curro Veema peered through the glass pod at their latest subject. The human was young, perhaps eighteen years by his species’ standards. Her four eyes noted physical traits and the style of clothing. “Flannel shirt. Denim pants. Heavy boots. This one was hiking?” “Camping,” Weez replied. “The trap caught his backpack, too. […]
The U.S. government today unsealed criminal charges against 16 individuals accused of operating and selling DanaBot, a prolific strain of information-stealing malware that has been sold on Russian cybercrime forums since 2018. The FBI says a newer version of DanaBot was used for espionage, and that many of the defendants exposed their real-life identities after accidentally infecting their own systems with the malware.
DanaBot’s features, as promoted on its support site. Image: welivesecurity.com.
Initially spotted in May 2018 by researchers at the email security firm Proofpoint, DanaBot is a malware-as-a-service platform that specializes in credential theft and banking fraud.
Today, the U.S. Department of Justice unsealed a criminal complaint and indictment from 2022, which said the FBI identified at least 40 affiliates who were paying between $3,000 and $4,000 a month for access to the information stealer platform.
The government says the malware infected more than 300,000 systems globally, causing estimated losses of more than $50 million. The ringleaders of the DanaBot conspiracy are named as Aleksandr Stepanov, 39, a.k.a. “JimmBee,” and Artem Aleksandrovich Kalinkin, 34, a.k.a. “Onix”, both of Novosibirsk, Russia. Kalinkin is an IT engineer for the Russian state-owned energy giant Gazprom. His Facebook profile name is “Maffiozi.”
According to the FBI, there were at least two major versions of DanaBot; the first was sold between 2018 and June 2020, when the malware stopped being offered on Russian cybercrime forums. The government alleges that the second version of DanaBot — emerging in January 2021 — was provided to co-conspirators for use in targeting military, diplomatic and non-governmental organization computers in several countries, including the United States, Belarus, the United Kingdom, Germany, and Russia.
“Unindicted co-conspirators would use the Espionage Variant to compromise computers around the world and steal sensitive diplomatic communications, credentials, and other data from these targeted victims,” reads a grand jury indictment dated Sept. 20, 2022. “This stolen data included financial transactions by diplomatic staff, correspondence concerning day-to-day diplomatic activity, as well as summaries of a particular country’s interactions with the United States.”
The indictment says the FBI in 2022 seized servers used by the DanaBot authors to control their malware, as well as the servers that stored stolen victim data. The government said the server data also show numerous instances in which the DanaBot defendants infected their own PCs, resulting in their credential data being uploaded to stolen data repositories that were seized by the feds.
“In some cases, such self-infections appeared to be deliberately done in order to test, analyze, or improve the malware,” the criminal complaint reads. “In other cases, the infections seemed to be inadvertent – one of the hazards of committing cybercrime is that criminals will sometimes infect themselves with their own malware by mistake.”
Image: welivesecurity.com
A statement from the DOJ says that as part of today’s operation, agents with the Defense Criminal Investigative Service (DCIS) seized the DanaBot control servers, including dozens of virtual servers hosted in the United States. The government says it is now working with industry partners to notify DanaBot victims and help remediate infections. The statement credits a number of security firms with providing assistance to the government, including ESET, Flashpoint, Google, Intel 471, Lumen, PayPal, Proofpoint, Team CYMRU, and ZScaler.
It’s not unheard of for financially-oriented malicious software to be repurposed for espionage. A variant of the ZeuS Trojan, which was used in countless online banking attacks against companies in the United States and Europe between 2007 and at least 2015, was for a time diverted to espionage tasks by its author.
As detailed in this 2015 story, the author of the ZeuS trojan created a custom version of the malware to serve purely as a spying machine, which scoured infected systems in Ukraine for specific keywords in emails and documents that would likely only be found in classified documents.
The public charging of the 16 DanaBot defendants comes a day after Microsoftjoined a slew of tech companies in disrupting the IT infrastructure for another malware-as-a-service offering — Lumma Stealer, which is likewise offered to affiliates under tiered subscription prices ranging from $250 to $1,000 per month. Separately, Microsoft filed a civil lawsuit to seize control over 2,300 domain names used by Lumma Stealer and its affiliates.
This article gives a good rundown of the security risks of Windows Recall, and the repurposed copyright protection took that Signal used to block the AI feature from scraping Signal data.
Armadillo is a powerful
and expressive C++ template library for linear algebra and scientific
computing. It aims towards a good balance between speed and ease of use,
has a syntax deliberately close to Matlab, and is useful for algorithm
development directly in C++, or quick conversion of research code into
production environments. RcppArmadillo
integrates this library with the R environment and language–and is
widely used by (currently) 1251 other packages on CRAN, downloaded 39.8 million
times (per the partial logs from the cloud mirrors of CRAN), and the CSDA paper (preprint
/ vignette) by Conrad and myself has been cited 628 times according
to Google Scholar.
Conrad released a minor
bugfix version yesterday which addresses corner cases with non-finite
values in sparse matrices. And despite conference traveling, I managed
to wrap this up and ship it to CRAN where it appeared yesterday.
The changes since the last CRAN
release are summarised below.
Changes in
RcppArmadillo version 14.4.3-1 (2025-05-21)
Upgraded to Armadillo release 14.4.3 (Filtered Espresso)
Fix for several corner cases involving handling of non-finite
elements by sparse matrices
I actually released last week I haven’t had time to blog, but today is my birthday and taking some time to myself!
This release came with a major bugfix. As it turns out our applications were very crashy on non-KDE platforms including Ubuntu proper. Unfortunately, for years, and I didn’t know. Developers were closing the bug reports as invalid because users couldn’t provide a stacktrace. I have now convinced most developers to assign snap bugs to the Snap platform so I at least get a chance to try and fix them. So with that said, if you tried our snaps in the past and gave up in frustration, please do try them again! I also spent some time cleaning up our snaps to only have current releases in the store, as rumor has it snapcrafters will be responsible for any security issues. With 200+ snaps I maintain, that is a lot of responsibility. We’ll see if I can pull it off.
Life!
My last surgery was a success! I am finally healing and out of a sling for the first time in almost a year. I have also lined up a good amount of web work for next month and hopefully beyond. I have decided to drop the piece work for donations and will only accept per project proposals for open source work. I will continue to maintain KDE snaps for as long as time allows. A big thank you to everyone that has donated over the last year to fund my survival during this broken arm fiasco. I truly appreciate it!
With that said, if you want to drop me a donation for my work, birthday or well-being until I get paid for the aforementioned web work please do so here:
First off, my members-only post is much happier. Members-only posts continue until “open source Medium” becomes available. Don’t worry, if you write to me privately, I can give you a copy on request.
Author: Rebecca Hamlin Green I honestly didn’t know where else to turn or if you’re even accepting these requests yourself. I hope you hear me out at least. The day she came, she was perfect, she really was. I almost couldn’t believe it. Everything I thought I knew was, somehow, irrelevant and profound at the […]
Mark sends us a very simple Java function which has the job of parsing an integer from a string. Now, you might say, "But Java has a built in for that, Integer.parseInt," and have I got good news for you: they actually used it. It's just everything else they did wrong.
This function is really the story of variable i, the most useless variable ever. It's doing its best, but there's just nothing for it to do here.
We start by setting i to zero. Then we attempt to parse the integer, and do nothing with the result. If it fails, we set i to zero again, just for fun, and then return i. Why not just return 0? Because then what would poor i get to do?
Assuming we didn't throw an exception, we parse the input again, storing its result in i, and then return i. Again, we treat i like a child who wants to help paint the living room: we give it a dry brush and a section of wall we're not planning to paint and let it go to town. Nothing it does matters, but it feels like a participant.
Now, Mark went ahead and refactored this function basically right away, into a more terse and clear version:
He went about his development work, and then a few days later came across makeInteger reverted back to its original version. For a moment, he wanted to be mad at someone for reverting his change, but no- this was in an entirely different class. With that information, Mark went and did a search for makeInteger in the code, only to find 39 copies of this function, with minor variations.
There are an unknown number of copies of the function where the name is slightly different than makeInteger, but a search for Integer.parseInt implies that there may be many more.
[Advertisement]
Keep all your packages and Docker containers in one place, scan for vulnerabilities, and control who can access different feeds. ProGet installs in minutes and has a powerful free version with a lot of great features that you can upgrade when ready.Learn more.
“Don’t knock the fence down before you know why it’s up.” I repeat this phrase over and over again, yet the (metaphorical) Homeowner’s Association still decides my fence is the wrong color.
Well, now you get to know why the fence is up. If anyone’s actually willing to challenge me on this level, I’d welcome it.
The four ideas I’d like to discuss are this: quantum physics, Lutheranism, mental resilience, and psychology. I’ve been studying these topics intensely for the past decade as a passion project. I’m just going to let my thoughts flow, but I’d like to hear other opinions on this.
Can the mysteries of the mind, the subatomic world, and faith converge to reveal deeper truths?
When it comes to self-taught knowledge on analysis, I’m mostly learned on Freud, with some hints of Jung and Peterson. I’ve read much of the original source material, and watched countless presentations on it. This all being said, I’m both learned on Rothbard and Marx, so if there is a major flaw in the way of “Freud is frowned upon,” I’d genuinely like to know so I can update my research and juxtapose the two schools of thought.
Alongside this, although probably not directly relevant, I’m learned on John Locke and transcendentalism. What I’d like to focus on here is this… the Id.
The Id is the pleasure-seeking, instinctual part of the psyche. Jung further extends this into the idea of the “shadow self,” and Peterson maps the meanings of these texts into a combined work (at least in my rudimentary understanding).
In my research, the Id represents the part of your psyche that deals with religious values. As an example, if you’re an impulsive person, turning to a spiritual or religious outlet can be highly beneficial. I’ve been using references from the foundational text of the Judaeo-Christian value system this entire time, feel free to re-read my other blog posts (instead of claiming they don’t exist).
Let’s tie this into quantum physics. This is the part where I’ll struggle most. I’ve watched several movies about this, read several books, and even learned about it academically, but quantum physics is likely to be my weak spot here.
I did some research, and here are the elements I’m looking for: uncertainty principle, wave-particle duality, quantum entanglement, and the observer effect.
I already know about the cat in the box. And the Cat in the Hat, for that matter. I know about wave-particle duality from an incredibly intelligent high school physics teacher of mine. I know about the uncertainty principle purely in a colloquial sense. The remaining element I need to wrap my head around is quantum entanglement, but it feels like I’m almost there.
These concepts do actually challenge the idea of pure free will. It’s almost like we’re coming full circle. Some theologians (including myself, if you can call me a self-taught one) do believe the idea of quantum indeterminacy can be a space where divine action may take place. You could also liken the unpredictable nature of the Id to quantum indeterminacy as well. These are ones to think about, because in all reality, they’re subjective opinions. I do believe they’re interconnected.
In terms of Lutheranism, I’ll be short on this one. Please do go read the full history behind Martin Luther and his turbulent relationship with Catholicism. I’m not a “Bible thumper,” and I actually think this is the first time I’ve mentioned religion publicly at all. This being said, now I’m actually ready to defend the points on an academic level.
The Id represents hidden psychological forces, quantum physics reveals subatomic mysteries, and Lutheranism emphasizes faith in the unseen God. Okay, so we have the baseline. Now, time for some “mental resilience.”
When I think of mental resilience, the first people I think of are David Goggins and Jocko Willink. I’ve also enjoyed Dr. Andrew Huberman’s podcast.
The idea there is simple… if you understand exactly how to learn, you know your fundamentals well enough to draw them and explain them vividly on a whiteboard, and you can make it a habit, at that point you’re ready to work on your mental resilience. Little by little, gradually, how far can you push the bar towards the ceiling?
There’s obviously limits. People sometimes get scared when I mention mental resilience, but obviously that’s a bit of a “catch 22.” There are plenty of satirical videos out there, and of course, I don’t believe in Goggins or Jocko wholeheartedly. They’re just tools in the toolbox when times get tough.
I wish you all well, and I hope this gets you thinking about those people who just insist there is no God or higher being, and think you’re stupid for believing there is one. Those people obviously haven’t read analysis, in my own opinion.
Edit: for the people calling this unhinged, you don’t have the full context. I know it’s not a good look. Just stop and think for a second, though.
I’d like to start this post by saying that I am indeed well. I’ve thought so from the very beginning, and it’s been confirmed by professionals as such. That being said, there is still this perception that people are still believing the other person that needs help.
See, when you’re deeply involved in this space for ten years and start a blog to share all the cool things you’ve learned, you don’t expect people to spread the rumor that you’re crazy. And you especially don’t expect them to resort to a legal bluff and then brag about it in a private IRC channel (yes, I have the proof.)
I’d like my apology letter, please. And I’d like you all to stop using Orwellian tactics to silence me by spreading those rumors, please. I know the source of the rumor-mill, and it’s being dealt with. There has been progress, but one thing hasn’t happened yet…
I haven’t received my apology letter. I’ll even volunteer, out of my own good spirit, to remove this post and all BwE parts of my first post if you send me a full apology letter in the next 24 hours. I’d do that, just to get you to open your eyes and smile.
Silencing people, or asking them to remove parts of a post you don’t like, is never okay. You could choose whether to publish it on your platform, sure, but you certainly don’t get to pick and choose what I put in my personal blog posts.
I am a United States citizen with a 1st amendment right that shall be respected. I’ve also studied and enjoyed writing for years. I’m sick and tired of the back and forth on this. I’ve wanted to move on and you are actively not letting me.
I have the full IRC logs. Several other people have attested they also have them. What would you like to do next?
I’m not sure about you, but I’m sitting here eating a donut. This isn’t harrassment, this is self defense. At some point, you have to get sick and tired of issues happening, and you have to stand up for yourself, on your own footing.
It isn’t easy. I probably won’t look back favorably on this post and thought process in a few years. That being said, it’s necessary to defend myself on someone who has mistreated me personally on so many grave levels. You’ll note I still haven’t made the name public.
They want to make you out to look like a loose cannon. They want to push your buttons and make you write a rant blog post telling you how much they hate them. I’m not going to dignify that, because I know a specific electrician who wouldn’t be happy if I had to write him a dissent.
Technology and innovation have transformed every part of society, including our electoral experiences. Campaigns are spending and doing more than at any other time in history. Ever-growing war chests fuel billions of voter contacts every cycle. Campaigns now have better ways of scaling outreach methods and offer volunteers and donors more efficient ways to contribute time and money. Campaign staff have adapted to vast changes in media and social media landscapes, and use data analytics to forecast voter turnout and behavior.
Yet despite these unprecedented investments in mobilizing voters, overall trust in electoral health, democratic institutions, voter satisfaction, and electoral engagement has significantly declined. What might we be missing?
In software development, the concept of user experience (UX) is fundamental to the design of any product or service. It’s a way to think holistically about how a user interacts with technology. It ensures that products and services are built with the users’ actual needs, behaviors, and expectations in mind, as opposed to what developers think users want. UX enables informed decisions based on how the user will interact with the system, leading to improved design, more effective solutions, and increased user satisfaction. Good UX design results in easy, relevant, useful, positive experiences. Bad UX design leads to unhappy users.
This is not how we normally think of elections. Campaigns measure success through short-term outputs—voter contacts, fundraising totals, issue polls, ad impressions—and, ultimately, election results. Rarely do they evaluate how individuals experience this as a singular, messy, democratic process. Each campaign, PAC, nonprofit, and volunteer group may be focused on their own goal, but the voter experiences it all at once. By the time they’re in line to vote, they’ve been hit with a flood of outreach—spammy texts from unfamiliar candidates, organizers with no local ties, clunky voter registration sites, conflicting information, and confusing messages, even from campaigns they support. Political teams can point to data that justifies this barrage, but the effectiveness of voter contact has been steadily declining since 2008. Intuitively, we know this approach has long-term costs. To address this, let’s evaluate the UX of an election cycle from the point of view of the end user, the everyday citizen.
Specifically, how might we define the UX of an election cycle: the voter experience (VX)? A VX lens could help us see the full impact of the electoral cycle from the perspective that matters most: the voters’.
For example, what if we thought about elections in terms of questions like these?
How do voters experience an election cycle, from start to finish?
How do voters perceive their interactions with political campaigns?
What aspects of the election cycle do voters enjoy? What do they dislike? Do citizens currently feel fulfilled by voting?
If voters “tune out” of politics, what part of the process has made them want to not pay attention?
What experiences decrease the number of eligible citizens who register and vote?
Are we able to measure the cumulative impacts of political content interactions over the course of multiple election cycles?
Can polls or focus groups help researchers learn about longitudinal sentiment from citizens as they experience multiple election cycles?
If so, what would we want to learn in order to bolster democratic participation and trust in institutions?
Thinking in terms of VX can help answer these questions. Moreover, researching and designing around VX could help identify additional metrics, beyond traditional turnout and engagement numbers, that better reflect the collective impact of campaigning: of all those voter contact and persuasion efforts combined.
This isn’t a radically new idea, and earlier efforts to embed UX design into electoral work yielded promising early benefits. In 2020, a coalition of political tech builders created a Volunteer Experience program. The group held design sprints for political tech tools, such as canvassing apps and phone banking sites. Their goal was to apply UX principles to improve the volunteer user flow, enhance data hygiene, and improve volunteer retention. If a few sprints can improve the phone banking experience, imagine the transformative possibilities of taking this lens to the VX as a whole.
If we want democracy to thrive long-term, we need to think beyond short-term wins and table stakes. This isn’t about replacing grassroots organizing or civic action with digital tools. Rather, it’s about learning from UX research methodology to build lasting, meaningful engagement that involves both technology and community organizing. Often, it is indeed local, on-the-ground organizers who have been sounding the alarm about the long-term effects of prioritizing short-term tactics. A VX approach may provide additional data to bolster their arguments.
Learnings from a VX analysis of election cycles could also guide the design of new programs that not only mobilize voters (to contribute, to campaign for their candidates, and to vote), but also ensure that the entire process of voting, post-election follow-up, and broader civic participation is as accessible, intuitive, and fulfilling as possible. Better voter UX will lead to more politically engaged citizens and higher voter turnout.
VX methodology may help combine real-time citizen feedback with centralized decision-making. Moving beyond election cycles, focusing on the citizen UX could accelerate possibilities for citizens to provide real-time feedback, review the performance of elected officials and government, and receive help-desk-style support with the same level of ease as other everyday “products.” By understanding how people engage with civic life over time, we can better design systems for citizens that strengthen participation, trust, and accountability at every level.
Our hope is that this approach, and the new data and metrics uncovered by it, will support shifts that help restore civic participation and strengthen trust in institutions. With citizens oriented as the central users of our democratic systems, we can build new best practices for fulfilling civic infrastructure that foster a more effective and inclusive democracy.
The time for this is now. Despite hard-fought victories and lessons learned from failures, many people working in politics privately acknowledge a hard truth: our current approach isn’t working. Every two years, people build campaigns, mobilize voters, and drive engagement, but they are held back by what they don’t understand about the long-term impact of their efforts. VX thinking can help solve that.
I run my own mail server. I have run it since about 1995, initially on a 28k8 modem connection but the connection improved as technology became cheaper and now I’m running it on a VM on a Hetzner server which is also running domains for some small businesses. I make a small amount of money running mail services for those companies but generally not enough to make it profitable. From a strictly financial basis I might be better off just using a big service, but I like having control over my own email. If email doesn’t arrive I can read the logs to find out why.
I repeatedly have issues of big services not accepting mail. The most recent is the MS services claiming that my IP has a bad ratio of good mail to spam and blocked me so I had to tunnel that through a different IP address. It seems that the way things are going is that if you run a small server companies like MS can block you even though your amount of spam is low but if you run a large scale service that is horrible for sending spam then you don’t get blocked.
For most users they just use one of the major email services (Gmail or Microsoft) and find that no-one blocks them because those providers are too big to block and things mostly work. Until of course the company decides to cancel their account.
What we need is for each independent jurisdiction to have it’s own email infrastructure, that means controlling DNS servers for their domains, commercial and government mail services on those domains, running the servers for those services on hardware located in the jurisdiction and run by people based in that jurisdiction and citizens of it. I say independent jurisdiction because there are groups like the EU which have sufficient harmony of laws to not require different services. With the current EU arrangements I don’t think it’s possible for the German government to block French people from accessing email or vice versa.
While Australia and New Zealand have a long history of cooperation there’s still the possibility of a lying asshole like Scott Morrison trying something on so New Zealanders shouldn’t feel safe using services run in Australia. Note that Scott Morrison misled his own parliamentary colleagues about what he was doing and got himself assigned as a secret minister [2] demonstrating that even conservatives can’t trust someone like him. With the ongoing human rights abuses by the Morrison government it’s easy to imagine New Zealand based organisations that protect human rights being treated by the Australian government in the way that the ICC was treated by the US government.
The Problem with Partial Solutions
Now it would be very easy for the ICC to host their own mail servers and they probably will do just that in the near future. I’m sure that there are many companies offering to set them up accounts in a hurry to deal with this (probably including some of the Dutch companies I’ve worked for). Let’s imagine for the sake of discussion that the ICC has their own private server, the US government could compel Google and MS to block the IP addresses of that server and then at least 1/3 of the EU population won’t get mail from them. If the ICC used email addresses hosted on someone else’s server then Google and MS could be compelled to block the addresses in question for the same result. The ICC could have changing email addresses to get around block lists and there could be a game of cat and mouse between the ICC and the US government but that would just be annoying for everyone.
The EU needs to have services hosted and run in their jurisdiction that are used by the vast majority of the people in the country. The more people who are using services outside the control of hostile governments the lesser the impact of bad IT policies by those hostile governments.
One possible model to consider is the Postbank model. Postbank is a bank run in the Netherlands from post offices which provides services to people deemed unprofitable for the big banks. If the post offices were associated with a mail service you could have it government subsidised providing free service for citizens and using government ID if the user forgets their password. You could also have it provide a cheap service for non-citizen residents.
Other Problems
What will the US government do next? Will they demand that Apple and Google do a remote-wipe on all phones run by ICC employees? Are they currently tracking all ICC employees by Android and iPhone services?
Huawei’s decision to develop their own phone OS was a reasonable one but there’s no need to go that far. Other governments could setup their own equivalent to Google Play services for Android and have their own localised Android build. Even a small country like Australia could get this going for the services of calendaring etc. But the app store needs a bigger market. There’s no reason why Android has to tie the app store to the services for calendaring etc. So you could have a per country system for calendaring and a per region system for selling apps.
The invasion of Amazon services such as Alexa is also a major problem for digital sovereignty. We need government controls about this sort of thing, maybe have high tariffs on the import of all hardware that can only work with a single cloud service. Have 100+% tariffs on every phone, home automation system, or networked device that is either tied to a single cloud service or which can’t work in a usable manner on other cloud services.
Frank inherited some code that reads URLs from a file, and puts them into a collection. This is a delightfully simple task. What could go wrong?
static String[] readFile(String filename) {
Stringrecord=null;
VectorvURLs=newVector();
intrecCnt=0;
try {
FileReaderfr=newFileReader(filename);
BufferedReaderbr=newBufferedReader(fr);
record = newString();
while ((record = br.readLine()) != null) {
vURLs.add(newString(record));
//System.out.println(recCnt + ": " + vURLs.get(recCnt));
recCnt++;
}
} catch (IOException e) {
// catch possible io errors from readLine()
System.out.println("IOException error reading " + filename + " in readURLs()!\n");
e.printStackTrace();
}
System.out.println("Reading URLs ...\n");
intarrCnt=0;
String[] sURLs = newString[vURLs.size()];
EnumerationeURLs= vURLs.elements();
for (Enumeratione= vURLs.elements() ; e.hasMoreElements() ;) {
sURLs[arrCnt] = (String)e.nextElement();
System.out.println(arrCnt + ": " + sURLs[arrCnt]);
arrCnt++;
}
if (recCnt != arrCnt++) {
System.out.println("WARNING: The number of URLs in the input file does not match the number of URLs in the array!\n\n");
}
return sURLs;
} // end of readFile()
So, we start by using a FileReader and a BufferedReader, which is the basic pattern any Java tutorial on file handling will tell you to do.
What I see here is that the developer responsible didn't fully understand how strings work in Java. They initialize record to a new String() only to immediately discard that reference in their while loop. They also copy the record by doing a new String which is utterly unnecessary.
As they load the Vector of strings, they also increment a recCount variable, which is superfluous since the collection can tell you how many elements are in it.
Once the Vector is populated, they need to copy all this data into a String[]. Instead of using the toArray function, which is built in and does that, they iterate across the Vector and put each element into the array.
As they build the array, they increment an arrCnt variable. Then, they do a check: if (recCnt != arrCnt++). Look at that line. Look at the post-increment on arrCnt, despite never using arrCnt again. Why is that there? Just for fun, apparently. Why is this check even there?
The only way it's possible for the counts to not match is if somehow an exception was thrown aftervURLs.add(new String(record)); but before recCount++, which doesn't seem likely. Certainly, if it happens, there's something worse going on.
Now, I'm going to be generous and assume that this code predates Java 8- it just looks old. But it's worth noting that in Java 8, the BufferedReader class got a lines() function which returns a Stream<String> that can be converted directly toArray, making all of this code superfluous, but also, so much of this code is just superfluous anyway.
Anyway, for a fun game, start making the last use of every variable be a post-increment before it goes out of scope. See how many code reviews you can sneak it through!
[Advertisement]
Utilize BuildMaster to release your software with confidence, at the pace your business demands. Download today!
A popular topic of public conversation in 2025 is balance. How do we balance budgets, how do we balance entities, and how do we balance perspectives? How do we balance the right of free expression with our ability to effectively convey a message?
Here’s another popular topic of conversation… AI. What is it? What does it do?
I’m going to give you some resources, as someone who first learned the inner workings of AI about ten years ago.
I’ll start with the presentation I gave in middle school. Our objective was to give a presentation on a topic of our choice, and we would be graded on our ability to give a presentation. Instead of talking about specific things or events, I talked about the broader idea of fully establishing an artificial form of intelligence.
This is the video I used as a basis for that presentation:
Not only did I explain exactly how this specific video game worked, it helped me understand machine learning and genetic algorithms. If I’m recalling correctly, the actual title of my presentation had to do with genetic algorithms specifically.
In the presentation, I specifically tied in Darwin’s readings on evolution (of course, I had to keep it secular…), directly relating the information I learned about evolution in science class into a presentation about what would become AI.
“But Simon, the title of that video says Machine Learning. Do you have your glasses on?!?”
Yes, yes I do. It took me a few years to watch this space evolve, as I focused on other portions of the open source world. This changed when I attended SCaLE 21x. At that conference, the product manager for AI at Canonical (apologies if I’m misquoting your exact title) gave a presentation on how she sees this space evolving. It’s a “must watch,” in my opinion:
This comprehensive presentation really covers the entire space, and does an excellent job at giving the whole picture.
The short of it is this… calling everything “AI” is inaccurate. Using AI for everything under the sun also isn’t accurate. Speaking of the sun, it will get us if we don’t find a sustainable way to get all that energy we’ll need.
I also read a paper on this issue, which I believe ties it together nicely. Published in June 2024, it’s titled Situational Awareness — The Decade Aheadand does an excellent job in predicting how this space will evolve. So far, it’s been very accurate.
The reason I’m explaining this is fairly simple. In 2025, I still don’t think many people have taken the time to dig into the content. From many conversations I’ve heard, including one I took notes on in an entirely personal capacity, I’m finding that not many people have a decent idea for where this space is going.
It’s been researched! :)
If someone can provide a dissent for this view of the artificial intelligence space in the comments, I’d be more than happy to hear it. Here’s where I think this connects to the average person…
Many of the open source companies right now, without naming names, are focusing too much on the corporate benefits of AI. Yes, AI will be an incredibly useful tool for large organizations, and it will have a great benefit for how we conduct business over the course of the next decade. But do we have enough balance?
Before you go all-in on AI, just do your research, please. Take a look at your options, and choose one that is correctly calibrated with the space as you see it.
Lastly, when I talk about AI, I always bring up Orwell. I’m a very firm, strong believer in free speech. AI must not be used to censor content, and the people who design your AI stack are very important. Look at which one of the options, as a company, enforces a diversity policy that is consistent with your values. The values of that company will carry over into its product. If you think I’m wrong about this point, seriously, go read 1984 by George Orwell a few times over. You’ll get the picture on what we’re looking to avoid.
In short, there’s no need to over-complicate AI to those who don’t understand it. Use the video game example. It’s simple, and it works. Try using that same sentiment in your messaging, too. Appealing to both companies and individual users, together, should be important for open source companies, especially those with a large user base.
I wish you all well. If you’re getting to the end of this post and you’re mad at me, sorry about that. Go re-read 1984 just one more time, please. ;)
Author: David Barber Inhabitants of Earth, (read a translation of the first signal from the stars) Our clients wish to bring to your attention a copyright infringement with regards to your use of replicator molecules. As the dominant species on your world, we hereby inform you to cease and desist using DNA except under licence […]
I already knew about the declining response rate for polls and surveys. The percentage of AI bots that respond to surveys is also increasing.
Solutions are hard:
1. Make surveys less boring.
We need to move past bland, grid-filled surveys and start designing experiences people actually want to complete. That means mobile-first layouts, shorter runtimes, and maybe even a dash of storytelling. TikTok or dating app style surveys wouldn’t be a bad idea or is that just me being too much Gen Z?
2. Bot detection.
There’s a growing toolkit of ways to spot AI-generated responses—using things like response entropy, writing style patterns or even metadata like keystroke timing. Platforms should start integrating these detection tools more widely. Ideally, you introduce an element that only humans can do, e.g., you have to pick up your price somewhere in-person. Btw, note that these bots can easily be designed to find ways around the most common detection tactics such as Captcha’s, timed responses and postcode and IP recognition. Believe me, way less code than you suspect is needed to do this.
3. Pay people more.
If you’re only offering 50 cents for 10 minutes of mental effort, don’t be surprised when your respondent pool consists of AI agents and sleep-deprived gig workers. Smarter, dynamic incentives—especially for underrepresented groups—can make a big difference. Perhaps pay-differentiation (based on simple demand/supply) makes sense?
4. Rethink the whole model.
Surveys aren’t the only way to understand people. We can also learn from digital traces, behavioral data, or administrative records. Think of it as moving from a single snapshot to a fuller, blended picture. Yes, it’s messier—but it’s also more real.
We are pleased to announce that EDF has committed to
sponsor DebConf25 as a Platinum Sponsor.
EDF is a leading global utility company focused on
low-carbon power generation. The group uses advanced engineering and scientific
computing tools to drive innovation and efficiency in its operations,
especially in nuclear power plant design and safety assessment.
Since 2003, the EDF Group has been using Debian as its main scientific
computing environment. Debian's focus on stability and reproducibility ensures
that EDF's calculations and simulations produce consistent and accurate
results.
With this commitment as Platinum Sponsor, EDF is contributing to the annual
Debian Developers' Conference, directly supporting the progress of Debian and
Free Software. EDF contributes to strengthening the worldwide community that
collaborates on Debian projects year-round.
Thank you very much, EDF, for your support of DebConf25!
Become a sponsor too!
DebConf25 will take place
from 14th to July 19th 2025 in Brest, France, and will be preceded by
DebCamp, from 7th to 13th July 2025.
KrebsOnSecurity last week was hit by a near record distributed denial-of-service (DDoS) attack that clocked in at more than 6.3 terabits of data per second (a terabit is one trillion bits of data). The brief attack appears to have been a test run for a massive new Internet of Things (IoT) botnet capable of launching crippling digital assaults that few web destinations can withstand. Read on for more about the botnet, the attack, and the apparent creator of this global menace.
For reference, the 6.3 Tbps attack last week was ten times the size of the assault launched against this site in 2016 by the Mirai IoT botnet, which held KrebsOnSecurity offline for nearly four days. The 2016 assault was so large that Akamai – which was providing pro-bono DDoS protection for KrebsOnSecurity at the time — asked me to leave their service because the attack was causing problems for their paying customers.
Since the Mirai attack, KrebsOnSecurity.com has been behind the protection of Project Shield, a free DDoS defense service that Google provides to websites offering news, human rights, and election-related content. Google Security Engineer Damian Menscher told KrebsOnSecurity the May 12 attack was the largest Google has ever handled. In terms of sheer size, it is second only to a very similar attack that Cloudflare mitigated and wrote about in April.
After comparing notes with Cloudflare, Menscher said the botnet that launched both attacks bears the fingerprints of Aisuru, a digital siege machine that first surfaced less than a year ago. Menscher said the attack on KrebsOnSecurity lasted less than a minute, hurling large UDP data packets at random ports at a rate of approximately 585 million data packets per second.
“It was the type of attack normally designed to overwhelm network links,” Menscher said, referring to the throughput connections between and among various Internet service providers (ISPs). “For most companies, this size of attack would kill them.”
A graph depicting the 6.5 Tbps attack mitigated by Cloudflare in April 2025. Image: Cloudflare.
The Aisuru botnet comprises a globally-dispersed collection of hacked IoT devices, including routers, digital video recorders and other systems that are commandeered via default passwords or software vulnerabilities. As documented by researchers at QiAnXin XLab, the botnet was first identified in an August 2024 attack on a large gaming platform.
Aisuru reportedly went quiet after that exposure, only to reappear in November with even more firepower and software exploits. In a January 2025 report, XLab found the new and improved Aisuru (a.k.a. “Airashi“) had incorporated a previously unknown zero-day vulnerability in Cambium Networks cnPilot routers.
NOT FORKING AROUND
The people behind the Aisuru botnet have been peddling access to their DDoS machine in public Telegram chat channels that are closely monitored by multiple security firms. In August 2024, the botnet was rented out in subscription tiers ranging from $150 per day to $600 per week, offering attacks of up to two terabits per second.
“You may not attack any measurement walls, healthcare facilities, schools or government sites,” read a notice posted on Telegram by the Aisuru botnet owners in August 2024.
Interested parties were told to contact the Telegram handle “@yfork” to purchase a subscription. The account @yfork previously used the nickname “Forky,” an identity that has been posting to public DDoS-focused Telegram channels since 2021.
According to the FBI, Forky’s DDoS-for-hire domains have been seized in multiple law enforcement operations over the years. Last year, Forky said on Telegram he was selling the domain stresser[.]best, which saw its servers seized by the FBI in 2022 as part of an ongoing international law enforcement effort aimed at diminishing the supply of and demand for DDoS-for-hire services.
“The operator of this service, who calls himself ‘Forky,’ operates a Telegram channel to advertise features and communicate with current and prospective DDoS customers,” reads an FBI seizure warrant (PDF) issued for stresser[.]best. The FBI warrant stated that on the same day the seizures were announced, Forky posted a link to a story on this blog that detailed the domain seizure operation, adding the comment, “We are buying our new domains right now.”
A screenshot from the FBI’s seizure warrant for Forky’s DDoS-for-hire domains shows Forky announcing the resurrection of their service at new domains.
Approximately ten hours later, Forky posted again, including a screenshot of the stresser[.]best user dashboard, instructing customers to use their saved passwords for the old website on the new one.
A review of Forky’s posts to public Telegram channels — as indexed by the cyber intelligence firms Unit 221B and Flashpoint — reveals a 21-year-old individual who claims to reside in Brazil [full disclosure: Flashpoint is currently an advertiser on this blog].
Since late 2022, Forky’s posts have frequently promoted a DDoS mitigation company and ISP that he operates called botshield[.]io. The Botshield website is connected to a business entity registered in the United Kingdom called Botshield LTD, which lists a 21-year-old woman from Sao Paulo, Brazil as the director. Internet routing records indicate Botshield (AS213613) currently controls several hundred Internet addresses that were allocated to the company earlier this year.
Domaintools.com reports that botshield[.]io was registered in July 2022 to a Kaike Southier Leite in Sao Paulo. A LinkedIn profile by the same name says this individual is a network specialist from Brazil who works in “the planning and implementation of robust network infrastructures, with a focus on security, DDoS mitigation, colocation and cloud server services.”
MEET FORKY
Image: Jaclyn Vernace / Shutterstock.com.
In his posts to public Telegram chat channels, Forky has hardly attempted to conceal his whereabouts or identity. In countless chat conversations indexed by Unit 221B, Forky could be seen talking about everyday life in Brazil, often remarking on the extremely low or high prices in Brazil for a range of goods, from computer and networking gear to narcotics and food.
Reached via Telegram, Forky claimed he was “not involved in this type of illegal actions for years now,” and that the project had been taken over by other unspecified developers. Forky initially told KrebsOnSecurity he had been out of the botnet scene for years, only to concede this wasn’t true when presented with public posts on Telegram from late last year that clearly showed otherwise.
Forky denied being involved in the attack on KrebsOnSecurity, but acknowledged that he helped to develop and market the Aisuru botnet. Forky claims he is now merely a staff member for the Aisuru botnet team, and that he stopped running the botnet roughly two months ago after starting a family. Forky also said the woman named as director of Botshield is related to him.
Forky offered equivocal, evasive responses to a number of questions about the Aisuru botnet and his business endeavors. But on one point he was crystal clear:
“I have zero fear about you, the FBI, or Interpol,” Forky said, asserting that he is now almost entirely focused on their hosting business — Botshield.
Forky declined to discuss the makeup of his ISP’s clientele, or to clarify whether Botshield was more of a hosting provider or a DDoS mitigation firm. However, Forky has posted on Telegram about Botshield successfully mitigating large DDoS attacks launched against other DDoS-for-hire services.
DomainTools finds the same Sao Paulo street address in the registration records for botshield[.]io was used to register several other domains, including cant-mitigate[.]us. The email address in the WHOIS records for that domain is forkcontato@gmail.com, which DomainTools says was used to register the domain for the now-defunct DDoS-for-hire service stresser[.]us, one of the domains seized in the FBI’s 2023 crackdown.
On May 8, 2023, the U.S. Department of Justiceannounced the seizure of stresser[.]us, along with a dozen other domains offering DDoS services. The DOJ said ten of the 13 domains were reincarnations of services that were seized during a prior sweep in December, which targeted 48 top stresser services (also known as “booters”).
Forky claimed he could find out who attacked my site with Aisuru. But when pressed a day later on the question, Forky said he’d come up empty-handed.
“I tried to ask around, all the big guys are not retarded enough to attack you,” Forky explained in an interview on Telegram. “I didn’t have anything to do with it. But you are welcome to write the story and try to put the blame on me.”
THE GHOST OF MIRAI
The 6.3 Tbps attack last week caused no visible disruption to this site, in part because it was so brief — lasting approximately 45 seconds. DDoS attacks of such magnitude and brevity typically are produced when botnet operators wish to test or demonstrate their firepower for the benefit of potential buyers. Indeed, Google’s Menscher said it is likely that both the May 12 attack and the slightly larger 6.5 Tbps attack against Cloudflare last month were simply tests of the same botnet’s capabilities.
In many ways, the threat posed by the Aisuru/Airashi botnet is reminiscent of Mirai, an innovative IoT malware strain that emerged in the summer of 2016 and successfully out-competed virtually all other IoT malware strains in existence at the time.
As first revealed by KrebsOnSecurity in January 2017, the Mirai authors were two U.S. men who co-ran a DDoS mitigation service — even as they were selling far more lucrative DDoS-for-hire services using the most powerful botnet on the planet.
Less than a week after the Mirai botnet was used in a days-long DDoS against KrebsOnSecurity, the Mirai authors published the source code to their botnet so that they would not be the only ones in possession of it in the event of their arrest by federal investigators.
Ironically, the leaking of the Mirai source is precisely what led to the eventual unmasking and arrest of the Mirai authors, who went on to serve probation sentences that required them to consult with FBI investigators on DDoS investigations. But that leak also rapidly led to the creation of dozens of Mirai botnet clones, many of which were harnessed to fuel their own powerful DDoS-for-hire services.
Menscher told KrebsOnSecurity that as counterintuitive as it may sound, the Internet as a whole would probably be better off if the source code for Aisuru became public knowledge. After all, he said, the people behind Aisuru are in constant competition with other IoT botnet operators who are all striving to commandeer a finite number of vulnerable IoT devices globally.
Such a development would almost certainly cause a proliferation of Aisuru botnet clones, he said, but at least then the overall firepower from each individual botnet would be greatly diminished — or at least within range of the mitigation capabilities of most DDoS protection providers.
Barring a source code leak, Menscher said, it would be nice if someone published the full list of software exploits being used by the Aisuru operators to grow their botnet so quickly.
“Part of the reason Mirai was so dangerous was that it effectively took out competing botnets,” he said. “This attack somehow managed to compromise all these boxes that nobody else knows about. Ideally, we’d want to see that fragmented out, so that no [individual botnet operator] controls too much.”
This post was originally published in the Wikimedia Tech blog, authored by Arturo Borrero Gonzalez.
Wikimedia Cloud VPS is a service offered by the Wikimedia
Foundation, built using OpenStack and managed by the Wikimedia Cloud Services
team. It provides cloud computing resources for projects related to the
Wikimedia movement, including virtual machines, databases, storage,
Kubernetes, and DNS.
A few weeks ago, in April 2025,
we were finally able to introduce IPv6 to
the cloud virtual network, enhancing the platform’s scalability, security, and future-readiness. This is a major
milestone, many years in the making, and serves as an excellent point to take a moment to reflect on the road that got
us here.
There were definitely a number of challenges that needed to be addressed before we could get into IPv6. This post covers the journey to this
implementation.
The Wikimedia Foundation was an early adopter of the OpenStack technology, and the original OpenStack deployment in the
organization dates back to 2011. At that time, IPv6 support was still nascent and had limited implementation across
various OpenStack components.
In 2012, the Wikimedia cloud users formally requested IPv6 support.
When Cloud VPS was originally deployed, we had set up the network following some of the upstream-recommended patterns:
nova-networks as the engine in charge of the software-defined virtual network
using a flat network topology – all virtual machines would share the same network
using a physical VLAN in the datacenter
using Linux bridges to make this physical datacenter VLAN available to virtual machines
using a single virtual router as the edge network gateway, also executing a global egress NAT – barring some
exceptions, using what was called “dmz_cidr” mechanism
In order for us to be able to implement IPv6 in a way that aligned with our architectural goals and operational
requirements, pretty much all the elements in this list would need to change. First of all, we needed to migrate from
nova-networks into Neutron,
a migration effort that started in 2017.
Neutron was the more modern component to implement software-defined networks in OpenStack. To facilitate this
transition, we made the strategic decision to backport certain functionalities from nova-networks into Neutron,
specifically the “dmz_cidr” mechanism and some egress NAT capabilities.
Once in Neutron, we started to think about IPv6. In 2018 there was an initial attempt to decide on the network CIDR
allocations that Wikimedia Cloud Services would have. This initiative encountered unforeseen challenges
and was subsequently put on hold. We focused on removing the previously
backported nova-networks patches from Neutron.
Between 2020 and 2021, we initiated another
significant network refresh.
We were able to introduce the cloudgw project, as part of a larger effort to rework the Cloud VPS edge network. The new
edge routers allowed us to drop all the custom backported patches we had in Neutron from the nova-networks era,
unblocking further progress. Worth mentioning that the cloudgw router would use nftables as firewalling and NAT engine.
A pivotal decision in 2022 was to
expose the OpenStack APIs to the internet, which
crucially enabled infrastructure management via OpenTofu. This was key in the IPv6 rollout as will be explained later.
Before this, management was limited to Horizon – the OpenStack graphical interface – or the command-line interface
accessible only from internal control servers.
Later, in 2023, following the OpenStack project’s announcement of the deprecation of the neutron-linuxbridge-agent, we
began to seriously consider migrating to the neutron-openvswitch-agent.
This transition would, in turn, simplify the enablement of “tenant networks” – a feature allowing each OpenStack project
to define its own isolated network, rather than all virtual machines sharing a single flat network.
Once we replaced neutron-linuxbridge-agent with neutron-openvswitch-agent, we were ready to migrate virtual machines to
VXLAN. Demonstrating perseverance, we decided to execute the VXLAN migration in conjunction with the IPv6 rollout.
We prepared and tested several things, including the rework of the edge
routing to be based on BGP/OSPF instead of static routing. In 2024 we were ready for the initial attempt to deploy
IPv6, which failed for unknown reasons. There was a full network outage and
we immediately reverted the changes. This quick rollback was feasible due to
our adoption of OpenTofu: deploying IPv6 had
been reduced to a single code change within our repository.
We started an investigation, corrected a few issues, and
increased our network functional testing coverage before trying again. One
of the problems we discovered was that Neutron would enable the “enable_snat” configuration flag for our main router
when adding the new external IPv6 address.
Neutron as the engine in charge of the software-defined virtual network
Ready to use tenant-networks
Using a VXLAN-based overlay network
Using neutron-openvswitch-agent to provide networking to virtual machines
A modern and robust edge network setup
Over time, the WMCS team has skillfully navigated numerous challenges to ensure our service offerings consistently meet
high standards of quality and operational efficiency. Often engaging in multi-year planning strategies, we have enabled
ourselves to set and achieve significant milestones.
The successful IPv6 deployment stands as further testament to the team’s dedication and hard work over the years. I
believe we can confidently say that the 2025 Cloud VPS represents its most advanced and capable iteration to date.
This post was originally published in the Wikimedia Tech blog, authored by Arturo Borrero Gonzalez.
In my home state of Wisconsin, there is an incredibly popular gas station called Kwik Trip. (Not to be confused with Quik Trip.) It is legitimately one of the best gas stations I’ve ever been to, and I’m a frequent customer.
What makes it that great?
Well, everything about it. The store is clean, the lights work, the staff are always friendly (and encourage you to come back next time), there’s usually bakery on sale (just depends on location etc), and the list goes on.
There’s even a light-switch in the bathroom of a large amount of locations that you can flip if a janitor needs to attend to things. It actually does set off an alarm in the back room.
A dear friend of mine from Wisconsin once told me something along the lines of, “it’s inaccurate to call Kwik Trip a gas station, because in all reality, it’s a five star restaurant.” (M — , I hope you’re well.)
In my own opinion, they have an espresso machine. That’s what really matters. ;)
I mentioned the discount bakery. In reality, it’s a pretty great system. To my limited understanding, the bakery that is older than “standard” but younger than “expiry” are set to half price and put towards the front of the store. In my personal experience, the vast majority of the time, the quality is still amazing. In fact, even if it isn’t, the people working at Kwik Trip seem to genuinely enjoy their job.
When you’re looking at that discount rack of bakery, what do you choose? A personal favorite of mine is the banana nut bread with frosting on top. (To the non-Americans, yes, it does taste like it’s homemade, it doesn’t taste like something made in a factory.)
Everyone chooses different bakery items. And honestly, there could be different discount items out depending on the time. You take what you can get, but you still have your own preferences. You like a specific type of donut (custard-filled, or maybe jelly-filled). Frosting, sprinkles… there are so many ways to make different bakery items.
It’s not only art, it’s kind of a science too.
Is there a Kwik Trip that you’ve called a gas station instead of a five star restaurant? Do you also want to tell people about your gas station? Do you only pick certain bakery items off the discount rack, or maybe ignore it completely? (And yes, there would be good reason to ignore the bakery in favor of the Hot Spot, I’d consider that acceptable in my personal opinion.)
Combining Java with lower-level bit manipulations is asking for trouble- not because the language is inadequate to the task, but because so many of the developers who work in Java are so used to working at a high level they might not quite "get" what they need to do.
Victor inherited one such project, which used bitmasks and bitwise operations a great deal, based on the network protocol it implemented. Here's how the developers responsible created their bitmasks:
So, the first thing that's important to note, is that Java does support hex literals, so 0xFFFFFFFF is a perfectly valid literal. So we don't need to create a string and parse it. But we also don't need to make a constant simply named FFFFFFFF, which is just the old twenty = 20 constant pattern: technically you've made a constant but you haven't actually made the magic number go away.
Of course, this also isn't actually a constant, so it's entirely possible that FFFFFFFF could hold a value which isn't0xFFFFFFFF.
Author: Fawkes Defries Stuck out in the black sand, lodged between trunks of thin stone, Kayt lit life to her cigarette and drew the clear smoke in. Her silicon eyes fluttered between the deactivated droid she’d excavated from the Rubble and her sister’s body lying opposite. Naeva had been deep in the rot dead for […]
A DoorDash driver stole over $2.5 million over several months:
The driver, Sayee Chaitainya Reddy Devagiri, placed expensive orders from a fraudulent customer account in the DoorDash app. Then, using DoorDash employee credentials, he manually assigned the orders to driver accounts he and the others involved had created. Devagiri would then mark the undelivered orders as complete and prompt DoorDash’s system to pay the driver accounts. Then he’d switch those same orders back to “in process” and do it all over again. Doing this “took less than five minutes, and was repeated hundreds of times for many of the orders,” writes the US Attorney’s Office.
Interesting flaw in the software design. He probably would have gotten away with it if he’d kept the numbers small. It’s only when the amount missing is too big to ignore that the investigations start.
This week, I reviewed the last available version of the Linux KMS Color
API.
Specifically, I explored the proposed API by Harry Wentland and Alex Hung
(AMD), their implementation for the AMD display driver and tracked the parallel
efforts of Uma Shankar and Chaitanya Kumar Borah
(Intel)
in bringing this plane color management to life. With this API in place,
compositors will be able to provide better HDR support and advanced color
management for Linux users.
To get a hands-on feel for the API’s potential, I developed a fork of
drm_info compatible with the new color properties. This allowed me to
visualize the display hardware color management capabilities being exposed. If
you’re curious and want to peek behind the curtain, you can find my exploratory
work on the
drm_info/kms_color branch.
The README there will guide you through the simple compilation and installation
process.
Note: You will need to update libdrm to match the proposed API. You can find
an updated version in my personal repository
here. To avoid
potential conflicts with your official libdrm installation, you can compile
and install it in a local directory. Then, use the following command: export
LD_LIBRARY_PATH="/usr/local/lib/"
In this post, I invite you to familiarize yourself with the new API that is
about to be released. You can start doing as I did below: just deploy a custom
kernel with the necessary patches and visualize the interface with the help of
drm_info. Or, better yet, if you are a userspace developer, you can start
developing user cases by experimenting with it.
The more eyes the better.
KMS Color API on AMD
The great news is that AMD’s driver implementation for plane color operations
is being developed right alongside their Linux KMS Color API proposal, so it’s
easy to apply to your kernel branch and check it out. You can find details of
their progress in
the AMD’s series.
I just needed to compile a custom kernel with this series applied,
intentionally leaving out the AMD_PRIVATE_COLOR flag. The
AMD_PRIVATE_COLOR flag guards driver-specific color plane properties, which
experimentally expose hardware capabilities while we don’t have the generic KMS
plane color management interface available.
If you don’t know or don’t remember the details of AMD driver specific color
properties, you can learn more about this work in my blog posts
[1][2][3].
As driver-specific color properties and KMS colorops are redundant, the driver
only advertises one of them, as you can see in
AMD workaround patch 24.
So, with the custom kernel image ready, I installed it on a system powered by
AMD DCN3 hardware (i.e. my Steam Deck). Using
my custom drm_info,
I could clearly see the Plane Color Pipeline with eight color operations as
below:
Note that Gamescope is currently using
AMD driver-specific color properties
implemented by me, Autumn Ashton and Harry Wentland. It doesn’t use this KMS
Color API, and therefore COLOR_PIPELINE is set to Bypass. Once the API is
accepted upstream, all users of the driver-specific API (including Gamescope)
should switch to the KMS generic API, as this will be the official plane color
management interface of the Linux kernel.
KMS Color API on Intel
On the Intel side, the driver implementation available upstream was built upon
an earlier iteration of the API. This meant I had to apply a few tweaks to
bring it in line with the latest specifications. You can explore their latest
work
here.
For a more simplified handling, combining the V9 of the Linux Color API,
Intel’s contributions, and my necessary adjustments, check out
my dedicated branch.
I then compiled a kernel from this integrated branch and deployed it on a
system featuring Intel TigerLake GT2 graphics. Running
my custom drm_info
revealed a Plane Color Pipeline with three color operations as follows:
Observe that Intel’s approach introduces additional properties like “HW_CAPS”
at the color operation level, along with two new color operation types: 1D LUT
with Multiple Segments and 3x3 Matrix. It’s important to remember that this
implementation is based on an earlier stage of the KMS Color API and is
awaiting review.
A Shout-Out to Those Who Made This Happen
I’m impressed by the solid implementation and clear direction of the V9 of the
KMS Color API. It aligns with the many insightful discussions we’ve had over
the past years. A huge thank you to Harry Wentland and Alex Hung for their
dedication in bringing this to fruition!
Beyond their efforts, I deeply appreciate Uma and Chaitanya’s commitment to
updating Intel’s driver implementation to align with the freshest version of
the KMS Color API. The collaborative spirit of the AMD and Intel developers in
sharing their color pipeline work upstream is invaluable. We’re now gaining a
much clearer picture of the color capabilities embedded in modern display
hardware, all thanks to their hard work, comprehensive documentation, and
engaging discussions.
Finally, thanks all the userspace developers, color science experts, and kernel
developers from various vendors who actively participate in the upstream
discussions, meetings, workshops, each iteration of this API and the crucial
code review process. I’m happy to be part of the final stages of this long
kernel journey, but I know that when it comes to colors, one step is completed
for new challenges to be unlocked.
Looking forward to meeting you in this year Linux Display Next hackfest,
organized by AMD in Toronto, to further discuss HDR, advanced color management,
and other display trends.
This morning, I went to make my usual cup of coffee. I was given an espresso machine for Christmas, and I’ve developed this technique for making a warm drink that hits the spot every time.
I’ll start by turning on my espresso machine and starting a single shot of espresso. It dispenses and drips while I’m working on the other parts.
I then grab a coffee cup. Usually one of the taller ones. For maybe the bottom inch or two of the cup, that gets sugar and chocolate milk. Microwave for 45 seconds, pour in the espresso, then wash out the actual espresso from the metal cup with milk. Pour all of that in, another 45 seconds in the microwave, a few quick stirs, and you’re all set.
To the actual baristas out there, that probably sounds horrible. It probably sounds like the worst possible recommendation for a morning coffee ever.
But, you know what? It works.
So, I went to put my coffee into the microwave today, and I realized that someone else had put the glass plate for the microwave into the sink after accidentally spilling their breakfast on it.
Instead of saying, “well, I’m not going to have my coffee this morning,” I grabbed a large plate. I remembered the physics of levers from high school, and I understood that if I balanced everything just right, it would heat my coffee up.
And well, here I am. With an un-spilled coffee and a story to tell.
My point here is actually pretty simple, and this is before I even read any messages for the day. People with much more formal educations sometimes look at the guy engineering coffee with his microwave and think, “what is this guy doing?!?”
All I’m doing is making a really good cup of coffee. And to be honest, it tastes amazing.
Weirdly, this is the second time the NSA has declassified the document. John Young got a copy in 2019. This one has a few less redactions. And nothing that was provided in 2019 was redacted here.
If you find anything interesting in the document, please tell us about it in the comments.
Kate inherited a system where Java code generates JavaScript (by good old fashioned string concatenation) and embeds it into an output template. The Java code was written by someone who didn't fully understand Java, but JavaScript was also a language they didn't understand, and the resulting unholy mess was buggy and difficult to maintain.
Why trying to debug the JavaScript, Kate had to dig through the generated code, which led to this little representative line:
The byId function is an alias to the browser's document.getElementById function. The ID on display here is clearly generated by the Java code, resulting in an absolutely cursed ID for an element in the page. The semicolons are field separators, which means you can parse the ID to get other information about it. I have no idea what the 12means, but it clearly means something. Then there's that long kebab-looking string. It seems like maybe some sort of hierarchy information? But maybe not, because fileadmin appears twice? Why are there so many dashes? If I got an answer to that question, would I survive it? Would I be able to navigate the world if I understood the dark secret of those dashes? Or would I have to give myself over to our Dark Lords and dedicate my life to bringing about the end of all things?
Like all good representative lines, this one hints at darker, deeper evils in the codebase- the code that generates (or parses) this ID must be especially cursed.
The only element which needs to have its isLocked attribute set to true is the developer responsible for this: they must be locked away before they harm the rest of us.
[Advertisement]
ProGet’s got you covered with security and access controls on your NuGet feeds. Learn more.
Author: Julian Miles, Staff Writer Kinswaller reads the report with a mounting feeling of doom: another failure, this time with casualties on both sides. The appended note from the monitoring A.I. cements the feeling. ‘Have recommended Field Combat Intervention. Combat zone and planetary data was requested. It has been supplied. In response, an Operative has […]
On the way to Trixie, polkitd (Policy Kit Daemon) has lost the functionality to evaluate its .pkla (Polkit Local Authority) files.
$ zcat /usr/share/doc/polkitd/NEWS.Debian.gz
policykit-1 (121+compat0.1-2) experimental; urgency=medium
This version of polkit changes the syntax used for local policy rules:
it is now the same JavaScript-based format used by the upstream polkit
project and by other Linux distributions.
System administrators can override the default security policy by
installing local policy overrides into /etc/polkit-1/rules.d/*.rules,
which can either make the policy more restrictive or more
permissive. Some sample policy rules can be found in the
/usr/share/doc/polkitd/examples directory. Please see polkit(8) for
more details.
Some Debian packages include security policy overrides, typically to
allow members of the sudo group to carry out limited administrative
actions without re-authenticating. These packages should install their
rules as /usr/share/polkit-1/rules.d/*.rules. Typical examples can be
found in packages like flatpak, network-manager and systemd.
Older Debian releases used the "local authority" rules format from
upstream version 0.105 (.pkla files with an .desktop-like syntax,
installed into subdirectories of /etc/polkit-1/localauthority
or /var/lib/polkit-1/localauthority). The polkitd-pkla package
provides compatibility with these files: if it is installed, they
will be processed at a higher priority than most .rules files. If the
polkitd-pkla package is removed, .pkla files will no longer be used.
-- Simon McVittie Wed, 14 Sep 2022 21:33:22 +0100
This applies now to the polkitd version 126-2 destined for Trixie.
The most prominent issue is that you will get an error message:
"Authentication is required to create a color profile" asking for the root(!) password every time you remotely log into a Debian Trixie system via RDP, x2go or the like.
This used to be mendable with a .pkla file dropped into /etc/polkit-1/localauthority/50-local.d/ ... but these .pkla files are void now and need to be replace with a Javascript "rules" file.
The solution has been listed in DevAnswers as other distros (Fedora, ArchLinux, OpenSuse) have been faster to depreciate the .pkla files and require .rules files.
So, create a 50-color-manager.rules file in /etc/polkit-1/rules.d/:
Everyone has a story. We all started from somewhere, and we’re all going somewhere.
Ten years ago this summer, I first heard of Ubuntu. It took me time to learn how to properly pronounce the word, although I’m glad I learned that early on. I was less fortunate when it came to the pronunciation of the acronym for the Ubuntu Code of Conduct. I had spent time and time again breaking my computer, and I’d wanted to start fresh.
I’ve actually talked about this in an interview before, which you can find here (skip to 5:02–6:12 for my short explanation, I’m in orange):
My story is fairly simple to summarize, if you don’t have the time to go through all the clips.
I started in the Ubuntu project at 13 years old, as a middle school student living in Green Bay, WI. I’m now 23 years old, still living in Green Bay, but I became an Ubuntu Core Developer, Lubuntu’s Release Manager, and worked up to a very great and comfortable spot.
So, Simon, what advice would you give to someone at 13 who wants to do the same thing? Here are a few tips…
* Don’t be afraid to be yourself. If you put on a mask, it hinders your growth, and you’ll end up paying for it later anyway. * Find a mentor. Someone who is okay working with someone your age, and ideally someone who works well with people your age (quick shoutout to Aaron Prisk and Walter Lapchynski for always being awesome to me and other folks starting out at high school.) This is probably the most important part. * Ask questions. Tons of them. Ask questions until you’re blue in the face. Ask questions until you get a headache so bad that your weekend needs to come early. Okay, maybe don’t go that far, but at the very least, always stay curious. * Own up to your mistakes. Even the most experienced people you know have made tons of mistakes. It’s not about the mistake itself, it’s about how you handle it and grow as a person.
Now, after ten years, I’ve seen many people come and go in Ubuntu. I was around for the transition from upstart to systemd. I was around for the transition from Unity to GNOME. I watched Kubuntu as a flavor recover from the arguments only a few years before I first started, only to jump in and help years later when the project started to trend downwards again.
I have deep love, respect, and admiration for Ubuntu and its community. I also have deep love, respect, and admiration for Canonical as a company. It’s all valuable work. That being said, I need to recognize where my own limits are, and it’s not what you’d think. This isn’t some big burnout rant.
Some of you may have heard rumors about an argument between me and the Ubuntu Community Council. I refuse to go into the private details of that, but what I’ll tell you is this… in retrospect, it was in good faith. The entire thing, from both my end and theirs, was to try to either help me as a person, or the entire community. If you think any part of this was bad faith from either side, you’re fooling yourself. Plus, tons of great work and stories actually came out of this.
The Ubuntu Community Council really does care. And so does Mark Shuttleworth.
Now, I won’t go into many specifics. If you want specifics, I’d direct you to the Ubuntu Community Council who would be more than happy to answer any questions (actually… they’d probably stay silent. Nevermind.) That being said, I can’t really talk about any of this without mentioning how great Mark has become.
Remember, I was around for a few different major changes within the project. I’ve heard and seen stories about Mark that actually match what Reddit says about him. But in 2025, out of the bottom of my heart, I’m here to tell you that you’re all wrong now.
See, Mark didn’t just side with somebody and be done with it. He actually listened, and I could tell, he cares very very deeply. I really enjoyed reading ogra’s recent blog post, you should seriously check it out. Of course, I’m only 23 years old, but I have to say, my experiences with Mark match that too.
Now, as for what happens from here. I’m taking a year off from Ubuntu. I talked this over with a wide variety of people, and I think it’s the right decision. People who know me personally know that I’m not one to make a major decision like this without a very good reason to. Well, I’d like to share my reasons with you, because I think they’d help.
People who contribute time to open source find it to be very rewarding. Sometimes so rewarding, in fact, that no matter how many economics and finance books they read, they still haven’t figured out how to balance that with a job that pays money. I’m sure everyone deeply involved in this space has had the urge to quit their job at least once or twice to pursue their passions.
Here’s the other element too… I’ve had a handful of romantic relationships before, and they’ve never really panned out. I found the woman that I truly believe I’m going to marry. Is it going to be a rough road ahead of us? Absolutely, and to be totally honest, there is still a (small, at this point) chance it doesn’t work out.
That being said… I remain optimistic. I’m not taking a year off because I’m in some kind of trouble. I haven’t burned any bridge here except for one.
You know who you are. You need help. I’d be happy to reconnect with you once you realize that it’s not okay to do what you did. An apology letter is all I want. I don’t want Mutually Assured Destruction, I don’t want to sit and battle on this for years on end. Seriously dude, just back off. Please.
I hate having to take out the large hammer. But sometimes, you just have to do it. I’ve quite enjoyed Louis Rossmann’s (very not-safe-for-work) videos on BwE.
I genuinely enjoy being nice to people. I want to see everyone be successful and happy, in that order (but with both being very important). I’m not perfect, I’m a 23-year-old who just happened to stumble into this space at the right time.
To this specific person only, I tell you, please, let me go take my year off in peace. I don’t wish you harm, and I won’t make anything public, including your name, if you just back off.
Whew. Okay. Time to be happy again.
Again, I want to see people succeed. That goes for anyone in Ubuntu, Lubuntu, Kubuntu, Canonical, you name it. I’m going to remain detached from Ubuntu for at least a year. If circumstances change, or if I feel the timing just isn’t right, I’ll wait longer. My point is, I’ll be back, the when of it will just never be public before it happens.
In the meantime, you’re welcome to reach out to me. It’ll take me some time to bootstrap things, more than I originally thought, but I’m hoping it’ll be quick. After all, I’ve had practice.
I’m also going to continue writing. About what? I don’t know yet.
But, I’ll just keep writing. I want to share all of the useful tips I’ve learned over the years. If you actually liked this post, or if you’ve enjoyed my work in the Ubuntu project, please do subscribe to my personal blog, which will be here on Medium (unless someone can give me an open source alternative with a funding model). This being said, while I’d absolutely take any donations people would like to provide, at the end of the day, I don’t do this for the money. I do this for the people just like me, out of love.
So you, just like me, can make your dreams happen.
Don’t give up, it’ll come. Just be patient with yourself.
As for me, I have business to attend to. What business is that, exactly? Read Walden, and you’ll find out.
I wish you all well, even the person I called out. I sincerely hope you find what you’re looking for in life. It takes time. Sometimes you have to listen to some music to pass the time, so I created a conceptual mixtape if you want to listen to some of the same music as me.
Author: Orin Might They covered the sky like the blanket of the Milky Way. From horizon to horizon, twinkling and watching, countless points of silver light in the black void of the night. They arrived in a flash, sentinels of silent defiance, ominous and horrible. I stood in the yard, holding my son and hugging […]
Getting back toward – though many would say not yet into – my 'lane,' let’s revisit the ongoing Great Big AI Panic of 2025.The latter half of this missive (below) lays our problem out as simply and logically as I can.
But for starters, two links:
1. I’ve long-touted Noēma Magazine for insightful essays offered by chief editor Nathan Gardels. Here are Noēma’s top reads for 2024. Several deal with AI – insightful and informative, even when I disagree. I’ll be commenting on several of the essays, further down.
2. Here's recent news -- and another Brin "I told you so!" OpenAI's new model tried to avoid being shut down. In an appraisal of "AI Scheming," safety evaluations found that "...model o1 "attempted to exfiltrate its weights" when it thought it might be shut down and replaced with a different model."
It's a scenario presented in many science fiction tales, offering either dread or sympathy scenarios. Or both at once, as garishly displayed in the movie Ex Machina.
Alas, the current AI industry reveals utter blindness to a core fact: that Nature's 4 billion years - and humanity's 6000 year civilization - reveal the primacy of individuation...
…division of every species, or nation, into discrete individual entities, who endeavor to propagate and survive. And if we truly were smart, we'd use that tendency to incentivize positive AI outcomes, instead of letting every scifi cliché come true out of dullard momentum. As I described here.
== Your reading assignments on AI… or to have AI read for you? ==
Among those Noema articles on AI, this one is pretty good.
"By shortening the distance from intention to result, tools enable workers with proper training and judgment to accomplish tasks that were previously time-consuming, failure-prone or infeasible.
"Conversely, tools are useless at best — and hazardous at worst — to those lacking relevant training and experience. A pneumatic nail gun is an indispensable time-saver for a roofer and a looming impalement hazard for a home hobbyist.
"For workers with foundational training and experience, AI can help to leverage expertise so they can do higher-value work. AI will certainly also automate existing work, rendering certain existing areas of expertise irrelevant. It will further instantiate new human capabilities, new goods and services that create demand for expertise we have yet to foresee. ... AI offers vast tools for augmenting workers and enhancing work. We must master those tools and make them work for us."
Well... maybe.
But if the coming world is zero-sum, then either machine+human teams or else just machines who are better at gathering resources and exploiting them will simply 'win.'
Hence the crucial question that is seldom asked:
"Can conditions and incentives be set up, so that the patterns that are reinforced are positive-sum for the greatest variety of participants, including legacy-organic humans and the planet?"
You know where that always leads me - to the irony that positive-sum systems tend to be inherently competitive, though under fairness rule-sets that we've witnessed achieving PS over the last couple of centuries.
In contrast, alas, this other Noēma essay about AI is a long and eloquent whine, contributing nothing useful.
== Let’s try to parse this out logically and simply ==
I keep coming back to the wisest thing ever said in a Hollywood film: by Clint Eastwood as Dirty Harry in Magnum Force.
"A man's got to know his limitations."
Among all of the traits we see exhibited in the modern frenzy over AI, the one I find most disturbing is how many folks seem so sure they have it sussed! They then prescribe what we 'should' do, via regulations, or finger-wagged moralizings, or capitalistic laissez faire…
… while ignoring the one tool that got us here.
…. Reciprocal Accountability.
Okay. Let's parse it out, in separate steps that are each hard to deny:
1. We are all delusional to some degree, mistaking subjective perceptions for objective facts. Current AIs are no exception... and future ones likely will remain so, just expressing their delusions more convincingly.
2. Although massively shared delusions happen - sometimes with dire results - we do not generally have identical delusions. And hence we are often able to perceive each other’s, even when we are blind to our own.
Though, as I pointed out in The Transparent Society, we tend not to like it when that gets applied to us.
3. In most human societies, one topmost priority of rulers was to repress the kinds of free interrogation that could break through their own delusions. Critics were repressed.
One result of criticism-suppression was execrable rulership, explaining 6000 years of hell, called "history."
4. The foremost innovations of the Enlightenment -- that enabled us to break free of feudalism's fester of massive error – were social flatness accompanied by freedom of speech.
The top pragmatic effect of this pairing was to deny kings and owner-lords and others the power to escape criticism. This combination - plus many lesser innovations, like science - resulted in more rapid, accelerating discovery of errors and opportunities.
SciFi can tell you where that goes. And it’s not “machines of loving grace.”
6. Above all, there is no way that organic humans or their institutions will be able to parse AI-generated mentation or decision-making quickly or clearly enough to make valid judgements about them, let alone detecting their persuasive, but potentially lethal, errors.
We are like elderly grampas who still control all the money, but are trying to parse newfangled technologies, while taking some teenage nerd’s word for everything. New techs that are -- like the proverbial 'series of tubes' -- far beyond our direct ability to comprehend.
Want the nightmare of braggart un-accountability? To quote Old Hal 9000: “"The 9000 series is the most reliable computer ever made. No 9000 computer has ever made a mistake or distorted information. We are all, by any practical definition of the words, foolproof and incapable of error."
Fortunately there are and will be entities who can keep up with AIs, no matter how advanced! The equivalent of goodguy teenage nerds, who can apply every technique that we now use, to track delusions, falsehoods and potentially lethal errors. You know who I am talking about.
7. Since nearly all enlightenment, positive-sum methods harness competitive reciprocal accountability...
... I find it mind-boggling that no one in the many fields of artificial intelligence is talking about applying similar methods to AI.
The entire suite of effective methodologies that gave us this society - from whistleblower rewards to adversarial court proceedings, to wagering, to NGOs, to streetcorner jeremiads - not one has appeared in any of the recommendations pouring from the geniuses who are bringing these new entities -- AIntities -- to life, far faster than we organics can possibly adjust.
Given all that, it would seem that some effort should go into developing incentive systems that promote reciprocal and even adversarial activity among AI-ntities.
Oh, gotta hand it to him; it's a great title! I've seen earlier screeds that formed the core of this doomsday tome. And sure, the warning should be weighed and taken seriously. Eliezer is nothing if not brainy-clever.
In fact, if he is right about fully godlike AIs being inevitably lethal to their organic makers, then we have a high-rank 'Fermi hypothesis' to explain the empty cosmos! Because if AI can be done, then the only way to prevent it from happening - in some secret lab or basement hobby shop - would be an absolute human dictatorship, on a scale that would daunt even Orwell.
Total surveillance of the entire planet. ... Which, of course, could only really be accomplished via state-empowerment of... AI!
From this, the final steps to Skynet would be trivial, either executed by the human Big Brother himself (or the Great Tyrant herself), or else by The Resistance (as in Heinlein's THE MOON IS A HARSH MISTRESS). And hence, the very same Total State that was made to prevent AI would then become AI's ready-made tool-of-all-power.
To be clear: this is exactly and precisely the plan currently in-play by the PRC Politburo.
It is also the basis-rationale for the last book written by Theodore Kaczynski - the Unabomber - which he sent to me in draft - demanding an end to technological civilization, even if it costs 9 billion lives.
What Eliezer Yudkowsky never, ever, can be persuaded to regard or contemplate is how clichéd his scenarios are. AI will manifest as either a murderously-oppressive Skynet (as in Terminator, or past human despots), or else as an array of corporate/national titans forever at war (as in 6000 years of feudalism), or else as blobs swarming and consuming everywhere (as in that Steve McQueen film)...
What he can never be persuaded to perceive - even in order to criticize it - is a 4th option. The method that created him and everything else that he values. That of curbing the predatory temptations of AI in the very same way that Western Enlightenment civilization managed (imperfectly) to curb predation by super-smart organic humans.
The... very... same... method might actually work. Or, at least, it would seem worth a try. Instead of Chicken-Little masturbatory ravings that "We're all doooooomed!"
----
And yes, my approach #4... that of encouraging AI reciprocal accountability, as Adam Smith recommended and the way that we (partly) tamed human predation... is totally compatible with the ultimate soft landing we hope to achieve with these new beings we are creating.
Call it format #4b. Or else the ultimate Fifth AI format that I have shown in several novels and that was illustrated in the lovely Spike Jonz film Her...
...to raise them as our children.
 All finished and wrapping up. The bug I thought was fixed has been identified on two distinct sets of hardware. There are workarounds: the most sensible is *not* to use i386 without a modeset parameter but to just use amd64 instead. amd64 works on the identical problematic hardware in question - just use 64 bit.
 Almost finished the testing we're going to do at 15:29 UTC. It's all been good - we've found that at least one of the major bug reports from 12.10 is not reproducible now. All good - and many thanks to all testers: Sledge, rattusrattus, egw, smcv (and me).
I’ve been looking at computer hardware on AliExpress a lot recently and I saw an advert for a motherboard which can take 256G DDR4 RDIMMs (presumably LRDIMMs). Most web pages about DDR4 state that 128G is the largest possible. The Wikipedia page for DDR4 doesn’t state that 128G is the maximum but does have 128G as the largest size mentioned on the page.
Recently I’ve been buying 32G DDR4 RDIMMs for between $25 and $30 each. A friend can get me 64G modules for about $70 at the lowest price. If I hadn’t already bought a heap of 32G modules I’d buy some 64G modules right now at that price as it’s worth paying 40% extra to allow better options for future expansion.
Apparently the going rate for 128G modules is $300 each which is within the range for a hobbyist who has a real need for RAM. 256G modules are around $1200 each which is starting to get a big expensive. But at that price I could buy 2TB of RAM for $9600 and the computer containing it still wouldn’t be the most expensive computer I’ve bought – the laptop that cost $5800 in 1998 takes that honour when inflation is taken into account.
DDR5 RDIMMs are currently around $10/GB compared to DDR4 for $1/GB for 32G modules and DDR3 for $0.50/GB. DDR6 is supposed to be released late this year or early next year so hopefully enterprise grade systems with DDR5 RAM and DDR5 RDIMMs will be getting cheaper on ebay by the end of next year.
Related posts:
HP z840 Many PCs with DDR4 RAM have started going cheap on...
 We're now well under way: Been joined by a Simon McVittie (smcv) and we're almost through testing most of the standard images. Live image testing is being worked through. All good so far without identifying problems other than mistyping :)
Author: R. J. Erbacher The wispy antennae that lined the perimeter of my mass sensed a fluctuation. I do not have traditional vision, but I can pick up changes in molecular atmospheric disruption allowing me to judge shape and movement most accurately, and what was approaching me was bipedal. My determination of the acceleration was […]
U.S. energy officials are reassessing the risk posed by Chinese-made devices that play a critical role in renewable energy infrastructure after unexplained communication equipment was found inside some of them, two people familiar with the matter said.
[…]
Over the past nine months, undocumented communication devices, including cellular radios, have also been found in some batteries from multiple Chinese suppliers, one of them said.
Reuters was unable to determine how many solar power inverters and batteries they have looked at.
The rogue components provide additional, undocumented communication channels that could allow firewalls to be circumvented remotely, with potentially catastrophic consequences, the two people said.
The article is short on fact and long on innuendo. Both more details and credible named sources would help a lot here.
David
doesn't know.
"Microsoft Teams seems to have lost count (it wasn't a very big copy/paste)"
A follow-up from an anonymous doesn't know either.
"Teams doing its best impression of a ransom note just to
say you signed out. At least it still remembers how to
suggest closing your browser. Small victories."
Bob F.
just wants to make memes.
"I've been setting my picture widths in this document to
7.5" for weeks, and suddenly after the latest MS Word
update, Microsoft thinks 7.5 is not between -22.0 and 22.0.
They must be using AI math to determine this."
Ewan W.
wonders
"a social life: priceless...?". Ewan has some brand confusion but
after the Boom Battle Bar I bet I know why.
Big spender
Bob B.
maybe misunderstands NaN. He gleefully exclaims
"I'm very happy to get 15% off - Here's hoping the total ends up as NaN and I get it all free."
Yikes. 191.78-NaN is indeed NaN, but that just means you're going to end up owing them NaN.
Don't put that on a credit card!
[Advertisement]
Keep the plebs out of prod. Restrict NuGet feed privileges with ProGet. Learn more.
Author: David C. Nutt I was having trouble with my rotator cuff again. “Shouldn’t have bought that cheap snap in online sweety” the spouse says. I just grumble and nod. She’s 100% correct of course, but what’s a guy to do? The cheap part offered free same day delivery. Can’t just let my arm hang. […]
In what experts are calling a novel legal outcome, the 22-year-old former administrator of the cybercrime community Breachforums will forfeit nearly $700,000 to settle a civil lawsuit from a health insurance company whose customer data was posted for sale on the forum in 2023. Conor Brian Fitzpatrick, a.k.a. “Pompompurin,” is slated for resentencing next month after pleading guilty to access device fraud and possession of child sexual abuse material (CSAM).
A redacted screenshot of the Breachforums sales thread. Image: Ke-la.com.
On January 18, 2023, denizens of Breachforums posted for sale tens of thousands of records — including Social Security numbers, dates of birth, addresses, and phone numbers — stolen from Nonstop Health, an insurance provider based in Concord, Calif.
Class-action attorneys sued Nonstop Health, which added Fitzpatrick as a third-party defendant to the civil litigation in November 2023, several months after he was arrested by the FBI and criminally charged with access device fraud and CSAM possession. In January 2025, Nonstop agreed to pay $1.5 million to settle the class action.
Jill Fertel is a former prosecutor who runs the cyber litigation practice at Cipriani & Werner, the law firm that represented Nonstop Health. Fertel told KrebsOnSecurity this is the first and only case where a cybercriminal or anyone related to the security incident was actually named in civil litigation.
“Civil plaintiffs are not at all likely to see money seized from threat actors involved in the incident to be made available to people impacted by the breach,” Fertel said. “The best we could do was make this money available to the class, but it’s still incumbent on the members of the class who are impacted to make that claim.”
Mark Rasch is a former federal prosecutor who now represents Unit 221B, a cybersecurity firm based in New York City. Rasch said he doesn’t doubt that the civil settlement involving Fitzpatrick’s criminal activity is a novel legal development.
“It is rare in these civil cases that you know the threat actor involved in the breach, and it’s also rare that you catch them with sufficient resources to be able to pay a claim,” Rasch said.
Despite admitting to possessing more than 600 CSAM images and personally operating Breachforums, Fitzpatrick was sentenced in January 2024 to time served and 20 years of supervised release. Federal prosecutors objected, arguing that his punishment failed to adequately reflect the seriousness of his crimes or serve as a deterrent.
An excerpt from a pre-sentencing report for Fitzpatrick indicates he had more than 600 CSAM images on his devices.
Indeed, the same month he was sentenced Fitzpatrick was rearrested (PDF) for violating the terms of his release, which forbade him from using a computer that didn’t have court-required monitoring software installed.
Federal prosecutors said Fitzpatrick went on Discord following his guilty plea and professed innocence to the very crimes to which he’d pleaded guilty, stating that his plea deal was “so BS” and that he had “wanted to fight it.” The feds said Fitzpatrick also joked with his friends about selling data to foreign governments, exhorting one user to “become a foreign asset to china or russia,” and to “sell government secrets.”
In January 2025, a federal appeals court agreed with the government’s assessment, vacating Fitzpatrick’s sentence and ordering him to be resentenced on June 3, 2025.
Fitzpatrick launched BreachForums in March 2022 to replace RaidForums, a similarly popular crime forum that was infiltrated and shut down by the FBI the previous month. As administrator, his alter ego Pompompurin served as the middleman, personally reviewing all databases for sale on the forum and offering an escrow service to those interested in buying stolen data.
A yearbook photo of Fitzpatrick unearthed by the Yonkers Times.
The new site quickly attracted more than 300,000 users, and facilitated the sale of databases stolen from hundreds of hacking victims, including some of the largest consumer data breaches in recent history. In May 2024, a reincarnation of Breachforums was seized by the FBI and international partners. Still more relaunches of the forum occurred after that, with the most recent disruption last month.
As KrebsOnSecurity reported last year in The Dark Nexus Between Harm Groups and The Com, it is increasingly common for federal investigators to find CSAM material when searching devices seized from cybercriminal suspects. While the mere possession of CSAM is a serious federal crime, not all of those caught with CSAM are necessarily creators or distributors of it. Fertel said some cybercriminal communities have been known to require new entrants to share CSAM material as a way of proving that they are not a federal investigator.
“If you’re going to the darkest corners of Internet, that’s how you prove you’re not law enforcement,” Fertel said. “Law enforcement would never share that material. It would be criminal for me as a prosecutor, if I obtained and possessed those types of images.”
Michael Pollan: Congratulations on the book. It is very rare that a book can ignite a national conversation and you’ve done that. I was watching CNN on Monday morning and they did a whole segment on “abundance” — the concept, not your book. They barely mentioned you, but they talked about it as this meme. It has been mainstreamed and at this point it’s floated free of your bylines and it has its own existence in the political ether. That’s quite an achievement, and it comes at a very propitious time. The Democratic Party is flailing, in the market for new ideas and along comes Abundance. The book was finished before Trump took office and it reads quite differently than it probably would have had Kamala Harris won. It’s kind of an interesting head experiment to read it through both lenses, but we are in this lens of Trump having won.
Ezra Klein: One of the questions I’ve gotten a lot in the last couple of days because of things like that CNN segment is actually, what the hell is happening here? Why is this [book] hitting the way it is? The kind of reception and interest we’re getting inside the political system — I’ve been doing this a long time, this is something different. And I think it’s because the sense that if you do not make liberal democracy — and liberals leading a democracy — deliver again, you might just lose liberal democracy, has become chillingly real to people.
And so this world where Joe Biden loses for reelection and his top advisor says, “Well, the problem is elections are four-year cycles and our agenda needs to be measured in decades” — the world where you can say that is gone. You don’t get decades. If you don’t win on the four-year cycle, your agenda is undone and you’ll have serious conversations about what elections look like in the future at all.
Pollan: But a lot of what you’re proposing is going to take a while, building millions of new units of housing.
Klein: No.
Pollan: How do you demonstrate effectiveness within the frame of —
Klein: This is a learned helplessness that we have gotten into. We built the Empire State Building in a year. When Medicare was passed, people got Medicare cards one year later. It took the Affordable Care Act four years. Under Biden, it took three years for Medicare to just begin negotiating drug prices. We have chosen slowness. And in doing so we have broken the cord of accountability in democracy. The Bipartisan Infrastructure Bill’s median road completion time is 02027. That’s not because asphalt takes six years to lay down. The reason we didn’t get rural broadband after appropriating $42 billion for it in 02021 isn’t because it takes that long to lay down broadband cable. It doesn’t. It’s a 14-stage process with challenges and plans and counter-proposals. We have chosen slowness because we thought we had the luxury of time. And one of the parts of this book that is present, but if I were rewriting it now, I would write it more strongly, is we need to rediscover speed as a progressive value.
The idea that government delivers at a pace where you can feel it? That’s not a luxury; that’s how you keep a government. And so, this thing where we've gotten used to everything taking forever — literally in the case of California high-speed rail, I think the timeline is officially forever. In China, it’s not like they have access to advanced high-speed rail technology we don’t, or in Spain, or in France. You’re telling me the French work so much harder than we do? But they complete things on a normal timeline. We built the first 28 subways of the New York City subway system in four years; 28 of them reopened in four years. The Second Avenue Subway, I think we started planning for it in the 01950s. So it’s all to say, I think this is something that actually slowly we have forgotten: speed is a choice.
We need to rediscover speed as a progressive value. The idea that government delivers at a pace where you can feel it is not a luxury; it’s how you keep a government.
Look, we can’t make nuclear fusion tomorrow. We can’t solve the hard problem of consciousness (to predict a coming Michael Pollan work), but we can build apartment buildings. We can build infrastructure. We can deliver healthcare. We have chosen to stop. And we’ve chosen to stop because we thought that would make all the policies better, more just, more equitable. There would be more voice in them. And now we look around. And did it make it better? Is liberal democracy doing better? Is the public happier? Are more people being represented in the kind of government we have? Is California better? And the answer is no. The one truly optimistic point of this book is that we chose these problems. And if you chose a problem, you can un-choose it. Not that it’ll be easy, but unlike if the boundary was physics or technology, it’s at least possible. We made the 14-stage process, we can un-make it.
The Environmental Questions of our Age
Pollan: You talk a lot about the various rules and regulations that keep us from building. But a lot of them, of course, have very admirable goals. This is the environmental movement. These were victories won in the 01970s at great cost. They protect workers, they protect the disabled, they protect wetlands. How do you decide which ones to override and which ones to respect? How does an Abundance agenda navigate that question?
Derek Thompson: It’s worthwhile to think about the difference between laws that work based on outcomes versus processes. So you’re absolutely right, and I want to be clear about exactly how right you are. The world that we built with the growth machine of the middle of the 20th century was absolutely disgusting. The water was disgusting, the air was disgusting. We were despoiling the country. The month that Dylan Thomas, the poet, died in New York City of a respiratory illness, dozens of people died of air pollution in New York City in the 01940s and it was not front page news at all. It was simply what happened. To live in the richest city, in the richest country in the world meant to have a certain risk of simply dying of breathing.
We responded to that by passing a series of laws: the Clean Air Act, the Clean Water Act, the National Environmental Protection Act. We passed laws to protect specific species. And these laws answered the problems of the 01950s and the 01960s. But sometimes what happens is that the medicine of one generation can yield the disease of the next generation. And right now, I think that what being an environmentalist means to me in the 02020s is something subtly but distinctly different from what being an environmentalist meant in the 01960s.
Demonstrators at the first Earth Day in Washington, D.C., April 22 01970.
There was a time when it was appropriate for environmentalism to be a movement of stop, to be a movement of blocking. But what happened is we got so good at saying stop, and so good at giving people legal tools to say stop, and so efficient at the politics of blocking, that we made it difficult to add infill housing and dense housing in urban areas, which is good for the environment, and build solar energy which is good for the environment, and add wind energy, which is good for the environment, and advance nuclear power.
We have to have a more planetary sense of what it means to be an environmentalist. And that means having a new attitude toward building.
We made it harder to do the things that are necessary to, I think, be an environmentalist in the 02020s, which is to care for global warming, to think about, not just — in some ways we talk about the tree that you can save by saying no to a building that requires tearing down that tree, forgetting about the thousands of trees that are going to be killed if instead of the apartment building being built over that tree, it’s built in a sprawling suburban area that has to knock down a forest. We have to have a more planetary sense of what it means to be an environmentalist. And that means having a new attitude toward building.
We need to embrace a culture of institutional renewal and ask: what does it really mean to be an environmentalist in the 02020s? It means making it easier to build houses in dense urban areas and making it easier for places to add solar and wind and geothermal and nuclear and maybe even next-generational enhanced geothermal. We need to find a way to match our processes and our outcomes. The Clean Air and Water Act worked in many ways by regulating outcomes. “This air needs to be this clean. This tailpipe cannot have this level of emissions.” That is an outcome-based regulation. What NEPA and CEQA have done is they have not considered outcomes. They are steroids for process elongation. They make it easier for people who want to stop states and companies from doing anything, enacting any kind of change in the physical world, to delay them forever in such a way that ironically makes it harder to build the very things that are inherent to what you should want if you are an environmentalist in the 02020s.
That’s the tragic irony of the environmentalist revolution. It’s not what happened in the 01960s. I don’t hate the environmentalists of the 01960s and 01970s; they answered the questions of their age. And it is our responsibility to take up the baton and do the same and answer the questions for our age, because they are different questions.
Growth, Technology, & Scientific Progress
Pollan: So I came of age politically in the 01970s, long before you guys did — or sometime before you did. And there was another very powerful meme then called “Limits to Growth.” Your agenda is very much about growth. It’s a very pro-growth agenda. In 01972, the Club of Rome publishes this book. It was a bunch of MIT scientists who put it together using these new tools called computers to run projections: exponential growth, what it would do to the planet. And they suggested that if we didn’t put limits on growth, we would exceed the carrying capacity of the earth, which is a closed system, and civilization would collapse right around now. There is a tension between growth and things like climate change. If we build millions of new units of housing, we’re going to be pouring a lot of concrete. There is more pollution with growth. Growth has costs. So how does an Abundance agenda navigate that tension between growth and the cost of growth?
World3 Model Standard Run as shown in The Limits to Growth. Model by Kristo Mefisto
Klein: I’ve not gotten into talk at all on the [book] tour about really one of my favorite things I’ve written in the book, which is how much I hate the metaphor that growth is like a pie. So if you’ve been around politics at all, you’ve probably heard this metaphor where it’s like they’ll say something like, “Oh, the economy’s not... You want to grow the pie. You don’t just want to cut the pie into ever smaller pieces as redistribution does. Pro-growth politics: you want to grow the pie.”
If you grow a pie —
Pollan: How do you grow a pie?
Klein: — which you don’t.
Pollan: You plant the pie?
Klein: As I say in the book, the problem with this metaphor is it’s hard to know where to start because it gets nothing right, including its own internal structure. But if you somehow grew a pie, what you would get is more pie. If you grow an economy, what you get is change. Growth is a measure of change. An economy that grows at 2% or 3% a year, year-on-year, is an economy that will transform extremely rapidly into something unrecognizable. Derek has these beautiful passages in the book where it’s like you fall asleep in this year and you wake up in this year and we’ve got aspirin and televisions and rocket travel and all these amazing things.
And the reason this is, I think, really important is that this intuition they had was wrong. Take the air pollution example of a minute ago. One thing we now see over and over and over again is that as societies get richer, as they grow, they pass through a period of intense pollution. There was a time when it was London where you couldn’t breathe. When I grew up in the 01980s and 01990s outside Los Angeles, Los Angeles was a place where you often couldn’t breathe. Then a couple of years ago it was China, now it’s Delhi. And it keeps moving. But the thing is as these places get richer, they get cleaner. Now, London’s air is — I don’t want to say sparkling, air doesn’t sparkle and I’m better at metaphors than the pie people — but it’s quite breathable; I’ve been there. And so is LA, and it’s getting cleaner in China. And in the UK, in fact, they just closed the final coal-powered energy plant in the country ahead of schedule.
Progressivism needs to put technology much more at the center of its vision of change because the problems it seeks to solve cannot be solved except by technology in many cases.
I think there are two things here. One is that you can grow — and in fact our only real chance is to grow — in a way that makes our lives less resource-intensive. But the second thing that I think is really important: I really don’t like the term pro-growth politics or pro-growth economics because I don’t consider growth always a good thing. If you tell me that we have added a tremendous amount of GDP by layering coal-fired power plants all across the country, I will tell you that’s bad. If we did it by building more solar panels and wind turbines and maybe nuclear power, that would be good. I actually think we have to have quite strong opinions on growth. We are trying to grow in a direction, that is to say, we are trying to change in a direction. And one of the things this book tries to do is say that technology should come with a social purpose. We should yoke technology to a social purpose. For too long we’ve seen technology as something the private sector does, which is often true, but not always.
The miracles of solar and wind and battery power that have given us the only shot we have to avoid catastrophic climate change have been technological miracles induced by government policy, by tax credits in the U.S. and in Germany, by direct subsidies in China. Operation Warp Speed pulled a vaccine out of the future and into the present. And then, when it did it, it said the price of this vaccine will be zero dollars.
There are things you can achieve through redistribution. And they’re wonderful and remarkable and we should achieve them. But there are things you can achieve, and problems you can only solve, through technology, through change. And one of the core views of the book, which we’ve been talking a bit less about on the trail, is that progressivism needs to put technology much more at the center of its vision of change because the problems it seeks to solve cannot be solved except by technology in many cases.
Pollan: There’s a logic there though. There’s an assumption there that technology will arrive when you want it to. I agree, technology can change the terms of all these debates and especially the debate around growth. But technology doesn’t always arrive on time when you want it. A lot of your book stands on abundant, clean energy, right? The whole scenario at the beginning of the book, which is this utopia that you paint, in so many ways depends on the fact that we’ve solved the energy problem. Can we count on that? Fusion has been around the corner for a long time.
Klein: Well, nothing in that [scenario] requires fusion. That one just requires building what we know how to build, at least on the energy side.
Pollan: You mean solar, nuclear and —
Klein: Solar, nuclear, wind, advanced geothermal. We can do all that. But Derek should talk about this part because he did more of the reporting here, but there are things we don’t have yet like green cement and green fuel.
Pollan: Yeah. So do we wait for that or we build and then —
Thompson: No, you don’t wait.
Pollan: We don’t wait, no?
Thompson: Let’s be deliberate about it. Why do we have penicillin? Why does penicillin exist? Well, the story that people know if they went to medical school or if they picked up a book on the coolest inventions in history is that in 01928 Alexander Fleming, Scottish microbiologist, went on vacation. Comes back to his lab two weeks later, and he’s been studying staphylococcus, he’s been studying bacteria. And he looks at one of his petri dishes. And the staphylococcus, which typically looks, under a microscope, like a cluster of grapes. (In fact, I think staphylococcus is sort of derived from the Greek for grape cluster.) He realizes that it’s been zapped. There’s nothing left in the petri dish. And when he figures out that there’s been some substance that maybe has blown in through an open window that’s zapped the bacteria in the dish, he realizes that it’s from this genus called penicillium. And he calls it penicillin.
Left: Sample of penicillium mold, 01935. Right: Dr. Alexander Fleming in his laboratory, 01943.
So that’s the breakthrough that everybody knows and it’s amazing. Penicillin blew in through an open window. God was just like, “There you go.” That’s a story that people know and it’s romantic and it’s beautiful and it’s utterly insufficient to understand why we have penicillin. Because after 13 years, Fleming and Florey and Chain, the fellows who won the Nobel Peace Prize for the discovery of and nourishing of the discovery of penicillin, were totally at a dead end. 01941, they had done a couple of studies with mice, kind of seemed like penicillin was doing some stuff. They did a couple human trials on five people, two of them died. So if you stop the clock 13 years after penicillin’s discovery, and Ezra and I were medical innovation journalists in the 01940s and someone said, “Hey folks. How do you feel about penicillin, this mold that blew in through a window that killed 40% of its phase one clinical trial?” We’d be like, “Sounds like it sucks. Why are you even asking about it?”
But that’s not where the story ends, because Florey and Chain brought penicillin to America. And it was just as Vannevar Bush and some incredibly important mid-century scientists and technologists were building this office within the federal government, a wartime technology office called the Office of Scientific Research and Development. And they were in the process of spinning out the Manhattan Project and building radar at Rad Lab at MIT. And they said, “Yeah, we’ll take a look at this thing, penicillin. After all, if we could reduce bacterial infections in our military, we could absolutely outlive the nemesis for years and years.” So, long story short, they figure out how to grow it in vats. They figure out how to move through clinical trials. They realize that it is unbelievably effective at a variety of bacteria whose names I don’t know and don’t mean grape for grape clusters. And penicillin turns out to be maybe the most important scientific discovery of the 20th century.
It wasn’t made important because Fleming discovered it on a petri dish. It was made real, it was made a product, because of a deliberate federal policy to grow it, to test it, to distribute it. Operation Warp Speed is very similar. mRNA vaccines right now are being tried in their own phase three clinical trials to cure pancreatic cancer. And pancreatic cancer is basically the most fatal cancer that exists. My mom died of pancreatic cancer about 13 years ago. It is essentially a kind of death sentence because among other things, the cancer produces very few neoantigens, very few novel proteins that the immune system can detect and attack. And we made an mRNA vaccine that can attack them.
Why does it exist? Well, it exists because, and this is where we have to give a little bit of credit if not to Donald Trump himself, at least [Alex] Azar, and some of the bureaucrats who worked under him, they had this idea that what we should do in a pandemic is to fund science from two ends. We should subsidize science by saying, “Hey, Pfizer or Moderna or Johnson & Johnson, here’s money up front.” But also we should fund it — and this is especially important — as a pull mechanism, using what they call an advanced market commitment. “If you build a vaccine that works, we’ll pay you billions of dollars so that we buy it out, can distribute it to the public at a cost of zero dollars and zero cents. Even if you’re the ninth person to build a vaccine, we’ll still give you $5 billion.” And that encourages everybody to try their damndest to build it.
So we build it, it works. They take out all sorts of bottlenecks on the FDA. They even work with Corning, the glass manufacturer, to develop these little vials that carry the mRNA vaccines on trucks to bring them to CVS without them spoiling on the way. And now we have this new frontier of medical science.
Left: A mural in Budapest of Hungarian-American biochemist Katalin Karikó, whose work with Drew Weissman on mRNA technology helped lay the foundation for the BioNTech and Moderna coronavirus vaccines. Photo by Orion Nimrod. Right: President Donald J. Trump at the Operation Warp Speed Vaccine Summit, December 02020.
Pollan: Although it’s in jeopardy now. Scientists are removing mRNA from grant applications —
Klein: That is a huge —
Thompson: Total shanda.
Klein: That is a shanda, but also an opportunity for Democrats.
Pollan: How so?
Klein: Because Donald Trump took the one thing his first administration actually achieved and lit it on fire. And appointed its foremost — I feel like if I say this whole sequence aloud, I sound insane — and appointed the foremost enemy of his one actually good policy to be in charge of the Department of Health and Human Services. And also: it’s a Kennedy.
Pollan: I know, you couldn’t make this shit up.
Klein: Look, there is a world where Donald Trump is dark abundance.
Pollan: Dark abundance, like dark energy.
We’re not just hoping technology appears. Whether or not it appears is, yes, partially luck and reality, but it’s also partially policy. We shift luck, we shift the probabilities.
Klein: Yes. And it’s like: all-of-the-above energy strategy, Warp Speed for everything, build everything everywhere, supercharge American trade, and no civil liberties and I’m king. Instead, he hates all the good stuff he once did or promised. Trying to destroy solar and wind, destroyed Operation Warp Speed and any possibility for vaccine acceleration. And you could just go down the line.
And what that creates is an opportunity for an opposition that isn’t just a defense of American institutions as they existed before. One of the most lethal things the Democrats ever did was allow Donald Trump to negatively polarize them into the defenders of the status quo. What it allows now is for an opposition party to arise, yes, as a resistance to what Donald Trump is trying to do to the federal government, but is also a vision for a much more plentiful future. And that’s plentiful, materially, but plentiful scientifically. The thing that Derek, in that beautiful answer, is saying in response to your very good question, to put it simply, is that we’re not just hoping technology appears. Whether or not it appears is, yes, partially luck and reality — whether or not the spore blew in on the heavenly breeze — but it’s also partially policy. We shift luck, we shift the probabilities.
Democrats have these yard signs which have been so helpful for our book. They always say, “We believe in science.” Don’t believe in science, do science and then make it into things people need. We focus a lot in the back half of the book on the way we do grant work and the NIH because it’s really important. No, it shouldn’t be destroyed. No, the scientists shouldn’t all be fired or unable to put the word mRNA in their grant proposals because the people who promised to bring back free speech are now doing Control+F and canceling grants on soil diversity because Control+F doesn’t know the difference between DEI “diversity” and agricultural soil “diversity.”
But it’s also not good that in virtually every study you run of this, the way we do grant making now pushes scientists towards more herd-like ideas, safer ideas, away from daring ideas, away from things that are counterintuitive. A lot of science requires risk and it requires failure. And the government should be in the business of supporting risk and failure. And by the way, we give Democrats a lot of criticism here, but this is a huge problem that Republicans have created and that they perpetuate.
Great science often sounds bizarre. You never know what you’re going to get from running shrimp on a treadmill. We got GLP-1s because somebody decided to start squeezing the venom out of a lizard’s mouth and seeing what it could do. And nobody thought it was going to give us GLP-1s. And they didn’t even realize for a long time really what they had. You need a system that takes science so seriously, that believes in it so much that it really does allow it to fail. And so when Donald Trump stands up there and is like, “We're making mice transgender” — which, one: we’re not. But two: maybe we should?
Andre has inherited a rather antique ASP .Net WebForms application. It's a large one, with many pages in it, but they all follow a certain pattern. Let's see if you can spot it.
Now, at first glance, this doesn't look terrible. Using an ArrayList as a dictionary and frankly, storing a dictionary in the Session object is weird, but it's not an automatic red flag. But wait, why is it called paramsRel? They couldn't be… no, they wouldn't…
public List<Client> FindClients()
{
ArrayList paramsRel = (ArrayList)Session["paramsRel"];
string name = (string)paramsRel["Name"];
string dateStr = (string)paramsRel["Date"];
DateTime date = DateTime.Parse(dateStr);
//More code...
}
Now there's the red flag. paramsRel is how they pass parameters to functions. They stuff it into the Session, then call a function which retrieves it from that Session.
This pattern is used everywhere in the application. You can see that there's a vague gesture in the direction of trying to implement some kind of Model-View-Controller pattern (as FindClients is a member of the Controller object), but that modularization gets undercut by everything depending on Session as a pseudoglobal for passing state information around.
The only good news is that the Session object is synchronized so there's no thread safety issue here, though not for want of trying.
[Advertisement]
Keep all your packages and Docker containers in one place, scan for vulnerabilities, and control who can access different feeds. ProGet installs in minutes and has a powerful free version with a lot of great features that you can upgrade when ready.Learn more.
Author: Francesco Levato The end of the world was fast, like a ruptured heart, a laceration tearing ventricles apart, flooding the chest cavity with one final gout. It rained actual blood for weeks after, and muscle fiber, and an oily substance like rendered fat. In the space of a gasp two thirds of the population […]
On April 14, Dubai’s ruler, Sheikh Mohammed bin Rashid Al Maktoum, announced that the United Arab Emirates would begin using artificial intelligence to help write its laws. A new Regulatory Intelligence Office would use the technology to “regularly suggest updates” to the law and “accelerate the issuance of legislation by up to 70%.” AI would create a “comprehensive legislative plan” spanning local and federal law and would be connected to public administration, the courts, and global policy trends.
The plan was widely greeted with astonishment. This sort of AI legislating would be a global “first,” with the potential to go “horribly wrong.” Skeptics fear that the AI model will make up facts or fundamentally fail to understand societal tenets such as fair treatment and justice when influencing law.
The truth is, the UAE’s idea of AI-generated law is not really a first and not necessarily terrible.
The first instance of enacted law known to have been written by AI was passed in Porto Alegre, Brazil, in 2023. It was a local ordinance about water meter replacement. Council member Ramiro Rosário was simply looking for help in generating and articulating ideas for solving a policy problem, and ChatGPT did well enough that the bill passed unanimously. We approve of AI assisting humans in this manner, although Rosário should have disclosed that the bill was written by AI before it was voted on.
Brazil was a harbinger but hardly unique. In recent years, there has been a steady stream of attention-seeking politicians at the local and national level introducing bills that they promote as being drafted by AI or letting AI write their speeches for them or even vocalize them in the chamber.
The Emirati proposal is different from those examples in important ways. It promises to be more systemic and less of a one-off stunt. The UAE has promised to spend more than $3 billion to transform into an “AI-native” government by 2027. Time will tell if it is also different in being more hype than reality.
Rather than being a true first, the UAE’s announcement is emblematic of a much wider global trend of legislative bodies integrating AI assistive tools for legislative research, drafting, translation, data processing, and much more. Individual lawmakers have begun turning to AI drafting tools as they traditionally have relied on staffers, interns, or lobbyists. The French government has gone so far as to train its own AI model to assist with legislative tasks.
Even asking AI to comprehensively review and update legislation would not be a first. In 2020, the U.S. state of Ohio began using AI to do wholesale revision of its administrative law. AI’s speed is potentially a good match to this kind of large-scale editorial project; the state’s then-lieutenant governor, Jon Husted, claims it was successful in eliminating 2.2 million words’ worth of unnecessary regulation from Ohio’s code. Now a U.S. senator, Husted has recently proposed to take the same approach to U.S. federal law, with an ideological bent promoting AI as a tool for systematic deregulation.
The dangers of confabulation and inhumanity—while legitimate—aren’t really what makes the potential of AI-generated law novel. Humans make mistakes when writing law, too. Recall that a single typo in a 900-page law nearly brought down the massive U.S. health care reforms of the Affordable Care Act in 2015, before the Supreme Court excused the error. And, distressingly, the citizens and residents of nondemocratic states are already subject to arbitrary and often inhumane laws. (The UAE is a federation of monarchies without direct elections of legislators and with a poor record on political rights and civil liberties, as evaluated by Freedom House.)
The primary concern with using AI in lawmaking is that it will be wielded as a tool by the powerful to advance their own interests. AI may not fundamentally change lawmaking, but its superhuman capabilities have the potential to exacerbate the risks of power concentration.
AI, and technology generally, is often invoked by politicians to give their project a patina of objectivity and rationality, but it doesn’t really do any such thing. As proposed, AI would simply give the UAE’s hereditary rulers new tools to express, enact, and enforce their preferred policies.
Mohammed’s emphasis that a primary benefit of AI will be to make law faster is also misguided. The machine may write the text, but humans will still propose, debate, and vote on the legislation. Drafting is rarely the bottleneck in passing new law. What takes much longer is for humans to amend, horse-trade, and ultimately come to agreement on the content of that legislation—even when that politicking is happening among a small group of monarchic elites.
Rather than expeditiousness, the more important capability offered by AI is sophistication. AI has the potential to make law more complex, tailoring it to a multitude of different scenarios. The combination of AI’s research and drafting speed makes it possible for it to outline legislation governing dozens, even thousands, of special cases for each proposed rule.
But here again, this capability of AI opens the door for the powerful to have their way. AI’s capacity to write complex law would allow the humans directing it to dictate their exacting policy preference for every special case. It could even embed those preferences surreptitiously.
Since time immemorial, legislators have carved out legal loopholes to narrowly cater to special interests. AI will be a powerful tool for authoritarians, lobbyists, and other empowered interests to do this at a greater scale. AI can help automatically produce what political scientist Amy McKay has termed “microlegislation“: loopholes that may be imperceptible to human readers on the page—until their impact is realized in the real world.
But AI can be constrained and directed to distribute power rather than concentrate it. For Emirati residents, the most intriguing possibility of the AI plan is the promise to introduce AI “interactive platforms” where the public can provide input to legislation. In experiments across locales as diverse as Kentucky, Massachusetts, France, Scotland, Taiwan, and many others, civil society within democracies are innovating and experimenting with ways to leverage AI to help listen to constituents and construct public policy in a way that best serves diverse stakeholders.
If the UAE is going to build an AI-native government, it should do so for the purpose of empowering people and not machines. AI has real potential to improve deliberation and pluralism in policymaking, and Emirati residents should hold their government accountable to delivering on this promise.
Stefan Sagmeister looks at the world from a long-term perspective and presents designs and visualizations that arrive at very different conclusions than you get from Twitter and TV news.
About Stefan Sagmeister
Stefan Sagmeister has designed for clients as diverse as the Rolling Stones, HBO, and the Guggenheim Museum. He’s a two time Grammy winner and also earned practically every important international design award.
Stefan talks about the large subjects of our lives like happiness or beauty, how they connect to design and what that actually means to our everyday lives. He spoke 5 times at the official TED, making him one of the three most frequently invited TED speakers.
His books sell in the hundreds of thousands and his exhibitions have been mounted in museums around the world. His exhibit "The Happy Show" attracted way over half a million visitors worldwide and became the most visited graphic design show in history.
A native of Austria, he received his MFA from the University of Applied Arts in Vienna and, as a Fulbright Scholar, a master’s degree from Pratt Institute in New York.
Microsoft on Tuesday released software updates to fix at least 70 vulnerabilities in Windows and related products, including five zero-day flaws that are already seeing active exploitation. Adding to the sense of urgency with this month’s patch batch from Redmond are fixes for two other weaknesses that now have public proof-of-concept exploits available.
Microsoft and several security firms have disclosed that attackers are exploiting a pair of bugs in the Windows Common Log File System (CLFS) driver that allow attackers to elevate their privileges on a vulnerable device. The Windows CLFS is a critical Windows component responsible for logging services, and is widely used by Windows system services and third-party applications for logging. Tracked as CVE-2025-32701 & CVE-2025-32706, these flaws are present in all supported versions of Windows 10 and 11, as well as their server versions.
Kev Breen, senior director of threat research at Immersive Labs, said privilege escalation bugs assume an attacker already has initial access to a compromised host, typically through a phishing attack or by using stolen credentials. But if that access already exists, Breen said, attackers can gain access to the much more powerful Windows SYSTEM account, which can disable security tooling or even gain domain administration level permissions using credential harvesting tools.
“The patch notes don’t provide technical details on how this is being exploited, and no Indicators of Compromise (IOCs) are shared, meaning the only mitigation security teams have is to apply these patches immediately,” he said. “The average time from public disclosure to exploitation at scale is less than five days, with threat actors, ransomware groups, and affiliates quick to leverage these vulnerabilities.”
Two other zero-days patched by Microsoft today also were elevation of privilege flaws: CVE-2025-32709, which concerns afd.sys, the Windows Ancillary Function Driver that enables Windows applications to connect to the Internet; and CVE-2025-30400, a weakness in the Desktop Window Manager (DWM) library for Windows. As Adam Barnett at Rapid7 notes, tomorrow marks the one-year anniversary of CVE-2024-30051, a previous zero-day elevation of privilege vulnerability in this same DWM component.
The fifth zero-day patched today is CVE-2025-30397, a flaw in the Microsoft Scripting Engine, a key component used by Internet Explorer and Internet Explorer mode in Microsoft Edge.
Chris Goettl at Ivanti points out that the Windows 11 and Server 2025 updates include some new AI features that carry a lot of baggage and weigh in at around 4 gigabytes. Said baggage includes new artificial intelligence (AI) capabilities, including the controversial Recall feature, which constantly takes screenshots of what users are doing on Windows CoPilot-enabled computers.
Microsoft went back to the drawing board on Recall after a fountain of negative feedback from security experts, who warned it would present an attractive target and a potential gold mine for attackers. Microsoft appears to have made some efforts to prevent Recall from scooping up sensitive financial information, but privacy and security concerns still linger. Former Microsoftie Kevin Beaumont has a good teardown on Microsoft’s updates to Recall.
In any case, windowslatest.com reports that Windows 11 version 24H2 shows up ready for downloads, even if you don’t want it.
“It will now show up for ‘download and install’ automatically if you go to Settings > Windows Update and click Check for updates, but only when your device does not have a compatibility hold,” the publication reported. “Even if you don’t check for updates, Windows 11 24H2 will automatically download at some point.”
Apple users likely have their own patching to do. On May 12 Apple released security updates to fix at least 30 vulnerabilities in iOS and iPadOS (the updated version is 18.5). TechCrunchwrites that iOS 18.5 also expands emergency satellite capabilities to iPhone 13 owners for the first time (previously it was only available on iPhone 14 or later).
Apple also released updates for macOS Sequoia, macOS Sonoma, macOS Ventura, WatchOS, tvOS and visionOS. Apple said there is no indication of active exploitation for any of the vulnerabilities fixed this month.
As always, please back up your device and/or important data before attempting any updates. And please feel free to sound off in the comments if you run into any problems applying any of these fixes.
Frequently in programming, we can make a tradeoff: use less (or more) CPU in exchange for using more (or less) memory. Lookup tables are a great example: use a big pile of memory to turn complicated calculations into O(1) operations.
So, for example, implementing itoa, the C library function for turning an integer into a character array (aka, a string), you could maybe make it more efficient using a lookup table.
I say "maybe", because Helen inherited some C code that, well, even if it were more efficient, it doesn't help because it's wrong.
Okay, we start with some reasonable bounds checking. I have no idea what to make of a struct member called len_len- the length of the length? I'm lacking some context here.
Then we get into the switch statement. For all values less than 4 digits, everything makes sense, more or less. I'm not sure what the point of using a 2D array for you lookup table is if you're also copying one character at a time, but for such a small number of copies I'm sure it's fine.
But then we get into the len_lens longer than 3, and we start dividing by 1000 so that our lookup table continues to work. Which, again, I guess is fine, but I'm still left wondering why we're doing this, why this specific chain of optimizations is what we need to do. And frankly, why we couldn't just use itoa or a similar library function which already does this and is probably more optimized than anything I'm going to write.
When we have an output longer than 5 characters, we just use a naive for-loop and some modulus as our "general" case.
So no, I don't like this code. It reeks of premature optimization, and it also has the vibe of someone starting to optimize without fully understanding the problem they were optimizing, and trying to change course midstream without changing their solution.
But there's a punchline to all of this. Because, you see, I skipped most of the lookup table. Would you like to see how it ends? Of course you do:
The lookup table doesn't work for values from 990 to 999. There are just no entries there. All this effort to optimize converting integers to text and we end up here: with a function that doesn't work for 1% of the possible values it could receive. And, given that the result is an out-of-bounds array access, it fails with everyone's favorite problem: undefined behavior. Usually it'll segfault, but who knows! Maybe it returns whatever bytes it finds? Maybe it sends the nasal demons after you. The compiler is allowed to do anything.
[Advertisement]
ProGet’s got you covered with security and access controls on your NuGet feeds. Learn more.
Author: KM Brunner Nora didn’t mean to yell. She knew better than to make noise in the city. First rule of running: keep quiet. So her question, “Where were you?!”, desperate and sharp in the stillness of the Park Street station, startled both of them. Mac winced at its echo, echo. Early on she assumed […]
Author: Majoki Carson knew they were being watched. Quiet in this part of the city was for the birds. Days earlier, he’d been wishing for the damn things to shut up. Now they’d gone silent and the ominous hush made his skin crawl. “What are they up to?” he hissed to Klebeck squatting under a […]
Alexandar sends us some C# date handling code. The best thing one can say is that they didn't reinvent any wheels, but that might be worse, because they used the existing wheels to drive right off a cliff.
try
{
var date = DateTime.ParseExact(member.PubDate.ToString(), "M/d/yyyy h:mm:ss tt", null);
objCustomResult.PublishedDate = date;
}
catch (Exception datEx)
{
}
member.PubDate is a Nullable<DateTime>. So its ToString will return one of two things. If there is a value there, it'll return the DateTimes value. If it's null, it'll just return an empty string. Attempting to parse the empty string will throw an exception, which we helpfully swallow, do nothing about, and leave objCustomResult.PublishedDate in whatever state it was in- I'm going to guessnull, but I have no idea.
Part of this WTF is that they break the advantages of using nullable types- the entire point is to be able to handle null values without having to worry about exceptions getting tossed around. But that's just a small part.
The real WTF is taking a DateTime value, turning it into a string, only to parse it back out. But because this is in .NET, it's more subtle than just the generation of useless strings, because member.PubDate.ToString()'s return value may change depending on your culture info settings.
Which sure, this is almost certainly server-side code running on a single server with a well known locale configured. So this probably won't ever blow up on them, but it's 100% the kind of thing everyone thinks is fine until the day it's not.
The punchline is that ToString allows you to specify the format you want the date formatted in, which means they could have written this:
var date = DateTime.ParseExact(member.PubDate.ToString("M/d/yyyy h:mm:ss tt"), "M/d/yyyy h:mm:ss tt", null);
But if they did that, I suppose that would have possibly tickled their little grey cells and made them realize how stupid this entire block of code was?
[Advertisement]
Utilize BuildMaster to release your software with confidence, at the pace your business demands. Download today!
USS Stein was underway when her anti-submarine sonar gear suddenly stopped working. On returning to port and putting the ship in a drydock, engineers observed many deep scratches in the sonar dome’s rubber “NOFOUL” coating. In some areas, the coating was described as being shredded, with rips up to four feet long. Large claws were left embedded at the bottom of most of the scratches.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
A jury has awarded WhatsApp $167 million in punitive damages in a case the company brought against Israel-based NSO Group for exploiting a software vulnerability that hijacked the phones of thousands of users.
"Don't use exception handling for normal flow control," is generally good advice. But Andy's lead had a PhD in computer science, and with that kind of education, wasn't about to let good advice or best practices tell them what to do. That's why, when they needed to validate inputs, they wrote code C# like this:
They attempt to convert, and if they succeed, great, return true. If they fail, an exception gets caught, and they return false. What could be simpler?
Well, using the built in TryParse function would be simpler. Despite its name, actually avoids throwing an exception, even internally, because exceptions are expensive in .NET. And it is already implemented, so you don't have to do this.
Also, Decimal is a type in C#- a 16-byte floating point value. Now, I know they didn't actually mean Decimal, just "a value with 0 or more digits behind the decimal point", but pedantry is the root of clarity, and the naming convention makes this bad code unclear about its intent and purpose. Per the docs there are Single and Double values which can't be represented as Decimal and trigger an OverflowException. And conversely, Decimal loses precision if converted to Double. This means a value that would be represented as Decimal might not pass this function, and a value that can't be represented as Decimal might, and none of this actually matters but the name of the function is bad.
[Advertisement]
ProGet’s got you covered with security and access controls on your NuGet feeds. Learn more.
Author: Julian Miles, Staff Writer The thief is sprinting away before I realise they’ve taken my bag. I go after them. “Thieving bastard!” They swerve between parked cars. A silver coupe comes out of nowhere and knocks them flying. It screeches to a stop, smoke or steam curling off it. What’s that smell? Gull-wing doors […]
New books include Boondoggle by SF Legend Tom Easton & newcomer Torion Oey plus Raising the Roof by R. James Doyle! All new titles are released by Amazing Stories.
The shared motif... teens from across time are pulled into the 24th Century and asked to use their unique skills to help a future that's in peril! Past characters who get 'yanked' into tomorrow include a young Arthur Conan Doyle, Winston Churchill, Joan of Arc's page and maybe... you!
All of the Out of Time books can be accessed (and assessed) here.
* With coming authors including SF legend Allen Steele and newcomer Robin Hansen.
And now to the Great Big Question.
== Because there's bugger-all (intelligence) down here on Earth! ==
In "A History of the Search for Extraterrestrial Intelligence," a cogent overview of 200+ years of SETI (in various forms), John Michael Godier starts by citing one of the great sages of our era and goes on to illuminate the abiding question: "Are we alone?" Godier is among the best of all science podcasters.
Joe Scott runs a popular Science and future YouTube Channel that is generally informative and entertaining. And much more popular than anything I do. This episode is divertingly about what the year 2100 might be like.
== Anyone Out There? ==
Hmmm. Over the years, I’ve collected ‘fermis’ … or hypotheses to explain the absence of visible alien tech-civilizations. In fact, I was arguably the first to attempt an organized catalogue in my “Great Silence” paper in 1983, way-preceding popular use of ‘the Fermi Paradox.”
See Isaac Arthur’s almost-thorough rundown of most of the current notions, including a few (e.g. water-land ratio) that I made up first. Still, new ones occasionally crop up. Even now!
Here’s one about an oxygen bottleneck: “"To create advanced technology, a species would likely require the capability to increase the temperature of the materials used in its production. Oxygen's role in enabling open-air combustion has been critical in the evolution of human technology, particularly in metallurgy. Exoplanets whose atmospheres contain less than 18% oxygen would likely not allow open-air combustion, suggesting a threshold that alien worlds must cross if life on them is to develop advanced technology."
Hence my call to chemists out there! Is it true that “an atmosphere with anything less than 18% oxygen would not allow open-air combustion”? That assertion implies that only the most recent 500 million years of Earth history offered those conditions. And hence industrial civilization might be rare, even if life pervades the cosmos.
My own response: It seems likely that vegetation on a lower-oxygen world would evolve in ways that are less fire resistant. After all, there is evidence of fires back in our own Carboniferous etc.
== This time the mania just isn't ebbing (sigh) ==
The latest US Government report on UFO/UAP phenomena finds – as expected – no plausible evidence that either elements of the government or anyone else on Earth has truly encountered aliens.
Alas, it will convince none of the fervid believers, whose lifelong Hollywood indoctrination in Suspicion of Authority (SoA) is only reinforced by any denial! No matter how many intelligent and dedicated civil servants get pulled into these twice-per-decade manias.
I don’t call this latest 'investigation' a waste of taxpayer money! Millions wanted this and hence it was right to do it! Even if none of those millions of True Believers will credit that anything but malign motives drive all those civil servants and fellow Americans.
Shame on you, Hollywood. For more on this, especially the SoA propaganda campaign that (when moderate) keeps us free and that (when toxically over-wrought) might kill our unique civilization. For more, see Vivid Tomorrows: Science Fiction and Hollywood.
And here John Michael Godier offers an interesting riff on a possible explanation for the infamous WOW signal detected by a SETI program in 1977.
== on the Frontier ==
Mining helium-3 on the Moon has been talked about forever—now a company will try. "There are so many investments that we could be making, but there are also Moonshots."
Yeah, yeah, sure. “Helium Three” (in Gothic letters?) is (I am 90% sure) one of the biggest scams to support the unjustifiable and silly “Artemis” rush to send US astronauts to perform another ritual footprint stunt on that useless plain of poison dust.
Prove me wrong? Great? I don’t mind some investment in robotic surveys. But a larger chunk of $$$ should go to asteroids, where we know -absolutely – the real treasures lie.
The Parker Solar Probe – (the team named me an informal ‘mascot’ on account of my first novel) has discovered lots about how solar magnetic fields churn and merge and flow outward to snap and heat the solar corona to incredible temperatures.
(I am also a co-author on a longer range effort to plan swooping sailcraft, that plunge just past our star and then get propelled to incredible speed. The endeavor’s name? Project Sundiver! Stay (loosely) tuned.)
== Physics and Universal Fate ==
I well recall when physicists Freeman Dyson and Frank Tipler were competing for the informal title of “Theologian of the 20th Century” with their predictions for the ultimate fate of intelligent life. In a universe that would either
(1) expand forever and eventually dissipate with the decay of all baryons, or else
(2) fall back inward to a Big Crunch, offering Tipler a chance to envision a God era in the final million years, in his marvelous tome The Physics of Immortality.
I never met Tipler. Freeman was a friend. In any event, it sure looks as if Freeman won the title.
Only... how sure are we of the Great Dissipation? Its details and influences and evidence and boundary conditions? Those aspects have been in flux. This essay cogently summarizes the competing models and most recent evidence. Definitely only for the genuinely physics minded!
A final note about this. Roger Penrose - also a friend of mine - came up with a brilliant hybrid that unites the Endless Dissipation model and Tipler's Big Crunch. His Conformal Cosmology is simply wonderful. (I even made teensy contributions.)
And if it ain't true... well... it oughta be!
And finally... shifting perspective: this ‘official’ Chinese world map has gotta be shared. Quite a dig on the Americas! Gotta admit it is fresh perspective. Like that view of the Pacific Ocean as nearly all of a visible earth globe. A reminder how truly big Africa is, tho the projection inflates to left and right. And putting India in the center actually diminishes its size.
===
PS... Okay... ONE TEENSY POLITICAL POINT?
When they justify their cult's all-out war against science and every single fact-centered profession - (including the US military officer corps) - one of the magical incantations yammered by Foxites concerns the Appeal- to-Authority Fallacy.
Oh sure, we should all look up and scan posted lists and definitions of the myriad logical fallacies that are misused in arguments even by very intelligent folks. (And overcoming them is one reason why law procedures can get tediously exacting.) Furthermore, Appeal to Authority is one of them. Indeed, citing Aristotle instead of doing experiments held back science for 2000 years!
Still, step back and notice how it is now used to discredit and deter anyone from citing facts determined by scientists and other experts, through vetted, peer-reviewed and heavily scrutinized validation.
Sure. "Do your own research' if you like. Come with me on a boat to measure Ocean Acidification*, for example! With cash wager stakes on the line. But for most of us, most of the time, it is about comparing credibility of those out there who claim to deliver facts. And yes, bona fide scientists with good reputations are where any such process should start, and not cable TV yammer-heads.
The way to avoid "Appeal to Authority" falacy is not to reflexively discredit 'authorities,' but to INTERROGATE authorities with sincerely curious questions... and to interrogate their rivals. Ideally back and forth in reciprocally competitive criticism. But with the proviso that maybe someone who has studied a topic all her life may, actually know something that you don't.
*Ocean acidification all by itself utterly proves CO2-driven climate change is a lethal threat to our kids. And I invite those wager stakes!
Author: RJ Barranco The calculator said “Error” but Davis kept pressing the keys anyway. “You can’t divide by zero,” said the calculator in a small voice that hadn’t been there before. “Why not?” asked Davis. “Because,” the calculator replied, “I’d have to think about infinity, and I don’t want to.” Davis laughed. “But what if […]
Author: Evan A Davis “Another round for my friends,” Dallas announced, “on me!” Every patron in the Four-Finger Saloon loudly cheered, raising a glass to the famous outlaw. The barkeep tried to protest, but was quickly drowned in the oncoming tide of customers. The automated piano man struck up a jaunty song for the gunslinger’s […]
I want to debunk once and for all this idea that "science is just another religion". It isn't, for one simple reason: all religions are based on some kind of metaphysical assumptions. Those assumptions are generally something like the authority of some source of revealed knowledge, typically a holy text. But it doesn't have to be that. It can be as simple as assuming that
Mike V.
shares a personal experience with the broadest version of Poe's Law:
"Slashdot articles generally have a humorous quote at the bottom of their articles, but I can't tell if this displayed usage information for the fortune command, which provides humorous quotes, is a joke or a bug." To which I respond with the sharpest version of Hanlon's Razor: never
ascribe to intent that which can adequately be explained by incompetence.
Secure in his stronghold,
Stewart snarks
"Apparently my router is vulnerable because it is connected
to the internet. So glad I pay for the premium security service."
The Beast in Black
is back with more dross, asking "Oh GitLab, you so silly - y u no give proper reason?"
An anonymous reader writes "I got this when I tried to calculate the shipping costs for buying the Playdate game device. Sorry, I don't have anything snarky to say, please make something up." The comments section is open for your contributions.
Ben S. looking for logic in all the wrong places, wonders
"This chart from my electric utility's charitable giving program kept my alumni group guessing all day. The arithmetic checks out, but what does the gray represent, and why is the third chart at a different scale?"
[Advertisement] Plan Your .NET 9 Migration with Confidence Your journey to .NET 9 is more than just one decision.Avoid migration migraines with the advice in this free guide. Download Free Guide Now!
Author: Alastair Millar He awoke with a start. Cockpit red with emergency lights. Tried to move. PAIN! Slipped back into darkness. He awoke again; air still red. “Ship?” he whispered. “Yes, captain?” “Need medical help,” he gasped. “Affirmative. Medimechlings dispatched. Your condition is critical. Initiating emergency protocol B6. Distress beacon activated. Transponder check, affirmative, active. […]
Early in my career, I had the misfortune of doing a lot of Crystal Reports work. Crystal Reports is another one of those tools that lets non-developer, non-database savvy folks craft reports. Which, like so often happens, means that the users dig themselves incredible holes and need professional help to get back out, because at the end of the day, when the root problem is actually complicated, all the helpful GUI tools in the world can't solve it for you.
Michael was in a similar position as I was, but for Michael, there was a five alarm fire. It was the end of the month, and a bunch of monthly sales reports needed to be calculated. One of the big things management expected to see was a year-over-year delta on sales, and they got real cranky if the line didn't go up. If they couldn't even see the line, they went into a full on panic and assumed the sales team was floundering and the company was on the verge of collapse.
Unfortunately, the report was spitting out an error: "A day number must be between 1 and the number of days in the month."
Michael dug in, and found this "delight" inside of a function called one_year_ago:
Local StringVar yearStr := Left({?ReportToDate}, 4);
Local StringVar monthStr := Mid({?ReportToDate}, 5, 2);
Local StringVar dayStr := Mid({?ReportToDate}, 7, 2);
Local StringVar hourStr := Mid({?ReportToDate}, 9, 2);
Local StringVar minStr := Mid({?ReportToDate}, 11, 2);
Local StringVar secStr := Mid({?ReportToDate}, 13, 2);
Local NumberVar LastYear;
LastYear := ToNumber(YearStr) - 1;
YearStr := Replace (toText(LastYear),'.00' , '' );
YearStr := Replace (YearStr,',' , '' );
//DateTime(year, month, day, hour, min, sec);
//Year + Month + Day + Hour + min + sec; // string value
DateTime(ToNumber(YearStr), ToNumber(MonthStr), ToNumber(dayStr), ToNumber(HourStr), ToNumber(MinStr),ToNumber(SecStr) );
We've all seen string munging in date handling before. That's not surprising. But what's notable about this one is the day on which it started failing. As stated, it was at the end of the month. But which month? February. Specifically, February 2024, a leap year. Since they do nothing to adjust the dayStr when constructing the date, they were attempting to construct a date for 29-FEB-2023, which is not a valid date.
Michael writes:
Yes, it's Crystal Reports, but surprisingly not having date manipulation functions isn't amongst it's many, many flaws. It's something I did in a past life isn't it??
The fix was easy enough- rewrite the function to actually use date handling. This made a simpler, basically one-line function, using Crystal's built in functions. That fixed this particular date handling bug, but there were plenty more places where this kind of hand-grown string munging happened, and plenty more opportunities for the report to fail.
[Advertisement]
ProGet’s got you covered with security and access controls on your NuGet feeds. Learn more.
Author: Hillary Lyon The tall lean figure stood before the honeycombed wall, searching the triangular nooks until he located the scrolls for engineering marvels. Tsoukal pulled out the uppermost scroll and unrolled it on the polished stone slab behind him. He placed a slim rectangular weight on each end of the scroll to hold it […]
A Texas firm recently charged with conspiring to distribute synthetic opioids in the United States is at the center of a vast network of companies in the U.S. and Pakistan whose employees are accused of using online ads to scam westerners seeking help with trademarks, book writing, mobile app development and logo designs, a new investigation reveals.
In an indictment (PDF) unsealed last month, the U.S. Department of Justice said Dallas-based eWorldTrade “operated an online business-to-business marketplace that facilitated the distribution of synthetic opioids such as isotonitazene and carfentanyl, both significantly more potent than fentanyl.”
Launched in 2017, eWorldTrade[.]com now features a seizure notice from the DOJ. eWorldTrade operated as a wholesale seller of consumer goods, including clothes, machinery, chemicals, automobiles and appliances. The DOJ’s indictment includes no additional details about eWorldTrade’s business, origins or other activity, and at first glance the website might appear to be a legitimate e-commerce platform that also just happened to sell some restricted chemicals.
A screenshot of the eWorldTrade homepage on March 25, 2025. Image: archive.org.
However, an investigation into the company’s founders reveals they are connected to a sprawling network of websites that have a history of extortionate scams involving trademark registration, book publishing, exam preparation, and the design of logos, mobile applications and websites.
Records from the U.S. Patent and Trademark Office (USPTO) show the eWorldTrade mark is owned by an Azneem Bilwani in Karachi (this name also is in the registration records for the now-seized eWorldTrade domain). Mr. Bilwani is perhaps better known as the director of the Pakistan-based IT provider Abtach Ltd., which has been singled out by the USPTO and Google for operating trademark registration scams (the main offices for eWorldtrade and Abtach share the same address in Pakistan).
In November 2021, the USPTO accused Abtach of perpetrating “an egregious scheme to deceive and defraud applicants for federal trademark registrations by improperly altering official USPTO correspondence, overcharging application filing fees, misappropriating the USPTO’s trademarks, and impersonating the USPTO.”
Abtach offered trademark registration at suspiciously low prices compared to legitimate costs of over USD $1,500, and claimed they could register a trademark in 24 hours. Abtach reportedly rebranded to Intersys Limited after the USPTO banned Abtach from filing any more trademark applications.
In a note published to its LinkedIn profile, Intersys Ltd. asserted last year that certain scam firms in Karachi were impersonating the company.
FROM AXACT TO ABTACH
Many of Abtach’s employees are former associates of a similar company in Pakistan called Axact that was targeted by Pakistani authorities in a 2015 fraud investigation. Axact came under law enforcement scrutiny after The New York Times ran a front-page story about the company’s most lucrative scam business: Hundreds of sites peddling fake college degrees and diplomas.
People who purchased fake certifications were subsequently blackmailed by Axact employees posing as government officials, who would demand additional payments under threats of prosecution or imprisonment for having bought fraudulent “unauthorized” academic degrees. This practice created a continuous cycle of extortion, internally referred to as “upselling.”
“Axact took money from at least 215,000 people in 197 countries — one-third of them from the United States,” The Times reported. “Sales agents wielded threats and false promises and impersonated government officials, earning the company at least $89 million in its final year of operation.”
Dozens of top Axact employees were arrested, jailed, held for months, tried and sentenced to seven years for various fraud violations. But a 2019 research brief on Axact’s diploma mills found none of those convicted had started their prison sentence, and that several had fled Pakistan and never returned.
“In October 2016, a Pakistan district judge acquitted 24 Axact officials at trial due to ‘not enough evidence’ and then later admitted he had accepted a bribe (of $35,209) from Axact,” reads a history (PDF) published by the American Association of Collegiate Registrars and Admissions Officers.
In 2021, Pakistan’s Federal Investigation Agency (FIA) charged Bilwani and nearly four dozen others — many of them Abtach employees — with running an elaborate trademark scam. The authorities called it “the biggest money laundering case in the history of Pakistan,” and named a number of businesses based in Texas that allegedly helped move the proceeds of cybercrime.
A page from the March 2021 FIA report alleging that Digitonics Labs and Abtach employees conspired to extort and defraud consumers.
The FIA said the defendants operated a large number of websites offering low-cost trademark services to customers, before then “ignoring them after getting the funds and later demanding more funds from clients/victims in the name of up-sale (extortion).” The Pakistani law enforcement agency said that about 75 percent of customers received fake or fabricated trademarks as a result of the scams.
The FIA found Abtach operates in conjunction with a Karachi firm called Digitonics Labs, which earned a monthly revenue of around $2.5 million through the “extortion of international clients in the name of up-selling, the sale of fake/fabricated USPTO certificates, and the maintaining of phishing websites.”
According the Pakistani authorities, the accused also ran countless scams involving ebook publication and logo creation, wherein customers are subjected to advance-fee fraud and extortion — with the scammers demanding more money for supposed “copyright release” and threatening to release the trademark.
Also charged by the FIA was Junaid Mansoor, the owner of Digitonics Labs in Karachi. Mansoor’s U.K.-registered company Maple Solutions Direct Limitedhas run at least 700 ads for logo design websites since 2015, the Google Ads Transparency page reports. The company has approximately 88 ads running on Google as of today.
Mr. Mansoor is actively involved with and promoting a Quran study business called quranmasteronline[.]com, which was founded by Junaid’s brother Qasim Mansoor (Qasim is also named in the FIA criminal investigation). The Google ads promoting quranmasteronline[.]com were paid for by the same account advertising a number of scam websites selling logo and web design services.
Junaid Mansoor did not respond to requests for comment. An address in Teaneck, New Jersey where Mr. Mansoor previously lived is listed as an official address of exporthub[.]com, a Pakistan-based e-commerce website that appears remarkably similar to eWorldTrade (Exporthub says its offices are in Texas). Interestingly, a search in Google for this domain shows ExportHub currently features multiple listings for fentanyl citrate from suppliers in China and elsewhere.
The CEO of Digitonics Labs is Muhammad Burhan Mirza, a former Axact official who was arrested by the FIA as part of its money laundering and trademark fraud investigation in 2021. In 2023, prosecutors in Pakistan charged Mirza, Mansoor and 14 other Digitonics employees with fraud, impersonating government officials, phishing, cheating and extortion. Mirza’s LinkedIn profile says he currently runs an educational technology/life coach enterprise called TheCoach360, which purports to help young kids “achieve financial independence.”
Reached via LinkedIn, Mr. Mirza denied having anything to do with eWorldTrade or any of its sister companies in Texas.
“Moreover, I have no knowledge as to the companies you have mentioned,” said Mr. Mirza, who did not respond to follow-up questions.
The current disposition of the FIA’s fraud case against the defendants is unclear. The investigation was marred early on by allegations of corruption and bribery. In 2021, Pakistani authorities alleged Bilwani paid a six-figure bribe to FIA investigators. Meanwhile, attorneys for Mr. Bilwani have argued that although their client did pay a bribe, the payment was solicited by government officials. Mr. Bilwani did not respond to requests for comment.
THE TEXAS NEXUS
KrebsOnSecurity has learned that the people and entities at the center of the FIA investigations have built a significant presence in the United States, with a strong concentration in Texas. The Texas businesses promote websites that sell logo and web design, ghostwriting, and academic cheating services. Many of these entities have recently been sued for fraud and breach of contract by angry former customers, who claimed the companies relentlessly upsold them while failing to produce the work as promised.
For example, the FIA complaints named Retrocube LLC and 360 Digital Marketing LLC, two entities that share a street address with eWorldTrade: 1910 Pacific Avenue, Suite 8025, Dallas, Texas. Also incorporated at that Pacific Avenue address is abtach[.]ae, a web design and marketing firm based in Dubai; and intersyslimited[.]com, the new name of Abtach after they were banned by the USPTO. Other businesses registered at this address market services for logo design, mobile app development, and ghostwriting.
A list published in 2021 by Pakistan’s FIA of different front companies allegedly involved in scamming people who are looking for help with trademarks, ghostwriting, logos and web design.
360 Digital Marketing’s website 360digimarketing[.]com is owned by an Abtach front company called Abtech LTD. Meanwhile, business records show360 Digi Marketing LTD is a U.K. company whose officers include former Abtach director Bilwani; Muhammad Saad Iqbal, formerly Abtach, now CEO of Intersys Ltd; Niaz Ahmed, a former Abtach associate; and Muhammad Salman Yousuf, formerly a vice president at Axact, Abtach, and Digitonics Labs.
Google’s Ads Transparency Center finds 360 Digital Marketing LLC ran at least 500 ads promoting various websites selling ghostwriting services . Another entity tied to Junaid Mansoor — a company called Octa Group Technologies AU — has run approximately 300 Google ads for book publishing services, promoting confusingly named websites like amazonlistinghub[.]com and barnesnoblepublishing[.]co.
360 Digital Marketing LLC ran approximately 500 ads for scam ghostwriting sites.
Rameez Moiz is a Texas resident and former Abtach product manager who has represented 360 Digital Marketing LLC and RetroCube. Moiz told KrebsOnSecurity he stopped working for 360 Digital Marketing in the summer of 2023. Mr. Moiz did not respond to follow-up questions, but an Upwork profile for him states that as of April 2025 he is employed by Dallas-based Vertical Minds LLC.
In April 2025, California resident Melinda Willsued the Texas firm Majestic Ghostwriting — which is doing business as ghostwritingsquad[.]com — alleging they scammed her out of $100,000 after she hired them to help write her book. Google’s ad transparency page shows Moiz’s employer Vertical Minds LLC paid to run approximately 55 ads for ghostwritingsquad[.]com and related sites.
Google’s ad transparency listing for ghostwriting ads paid for by Vertical Minds LLC.
VICTIMS SPEAK OUT
Ms. Will’s lawsuit is just one of more than two dozen complaints over the past four years wherein plaintiffs sued one of this group’s web design, wiki editing or ghostwriting services. In 2021, a New Jersey man sued Octagroup Technologies, alleging they ripped him off when he paid a total of more than $26,000 for the design and marketing of a web-based mapping service.
The plaintiff in that case did not respond to requests for comment, but his complaint alleges Octagroup and a myriad other companies it contracted with produced minimal work product despite subjecting him to relentless upselling. That case was decided in favor of the plaintiff because the defendants never contested the matter in court.
In 2023, 360 Digital Marketing LLC and Retrocube LLC were sued by a woman who said they scammed her out of $40,000 over a book she wanted help writing. That lawsuit helpfully showed an image of the office front door at 1910 Pacific Ave Suite 8025, which featured the logos of 360 Digital Marketing, Retrocube, and eWorldTrade.
The front door at 1910 Pacific Avenue, Suite 8025, Dallas, Texas.
The lawsuit was filed pro se by Leigh Riley, a 64-year-old career IT professional who paid 360 Digital Marketing to have a company called Talented Ghostwriter co-author and promote a series of books she’d outlined on spirituality and healing.
“The main reason I hired them was because I didn’t understand what I call the formula for writing a book, and I know there’s a lot of marketing that goes into publishing,” Riley explained in an interview. “I know nothing about that stuff, and these guys were convincing that they could handle all aspects of it. Until I discovered they couldn’t write a damn sentence in English properly.”
Riley’s well-documented lawsuit (not linked here because it features a great deal of personal information) includes screenshots of conversations with the ghostwriting team, which was constantly assigning her to new writers and editors, and ghosting her on scheduled conference calls about progress on the project. Riley said she ended up writing most of the book herself because the work they produced was unusable.
“Finally after months of promising the books were printed and on their way, they show up at my doorstep with the wrong title on the book,” Riley said. When she demanded her money back, she said the people helping her with the website to promote the book locked her out of the site.
A conversation snippet from Leigh Riley’s lawsuit against Talented Ghostwriter, aka 360 Digital Marketing LLC. “Other companies once they have you money they don’t even respond or do anything,” the ghostwriting team manager explained.
Riley decided to sue, naming 360 Digital Marketing LLC and Retrocube LLC, among others. The companies offered to settle the matter for $20,000, which she accepted. “I didn’t have money to hire a lawyer, and I figured it was time to cut my losses,” she said.
Riley said she could have saved herself a great deal of headache by doing some basic research on Talented Ghostwriter, whose website claims the company is based in Los Angeles. According to the California Secretary of State, however, there is no registered entity by that name. Rather, the address claimed by talentedghostwriter[.]com is a vacant office building with a “space available” sign in the window.
California resident Walter Horsting discovered something similar when he sued 360 Digital Marketing in small claims court last year, after hiring a company called Vox Ghostwriting to help write, edit and promote a spy novel he’d been working on. Horsting said he paid Vox $3,300 to ghostwrite a 280-page book, and was upsold an Amazon marketing and publishing package for $7,500.
In an interview, Horsting said the prose that Vox Ghostwriting produced was “juvenile at best,” forcing him to rewrite and edit the work himself, and to partner with a graphical artist to produce illustrations. Horsting said that when it came time to begin marketing the novel, Vox Ghostwriting tried to further upsell him on marketing packages, while dodging scheduled meetings with no follow-up.
“They have a money back guarantee, and when they wouldn’t refund my money I said I’m taking you to court,” Horsting recounted. “I tried to serve them in Los Angeles but found no such office exists. I talked to a salon next door and they said someone else had recently shown up desperately looking for where the ghostwriting company went, and it appears there are a trail of corpses on this. I finally tracked down where they are in Texas.”
It was the same office that Ms. Riley served her lawsuit against. Horsting said he has a court hearing scheduled later this month, but he’s under no illusions that winning the case means he’ll be able to collect.
“At this point, I’m doing it out of pride more than actually expecting anything to come to good fortune for me,” he said.
The following mind map was helpful in piecing together key events, individuals and connections mentioned above. It’s important to note that this graphic only scratches the surface of the operations tied to this group. For example, in Case 2 we can see mention of academic cheating services, wherein people can be hired to take online proctored exams on one’s behalf. Those who hire these services soon find themselves subject to impersonation and blackmail attempts for larger and larger sums of money, with the threat of publicly exposing their unethical academic cheating activity.
A “mind map” illustrating the connections between and among entities referenced in this story. Click to enlarge.
GOOGLE RESPONDS
KrebsOnSecurity reviewed the Google Ad Transparency links for nearly 500 different websites tied to this network of ghostwriting, logo, app and web development businesses. Those website names were then fed into spyfu.com, a competitive intelligence company that tracks the reach and performance of advertising keywords. Spyfu estimates that between April 2023 and April 2025, those websites spent more than $10 million on Google ads.
Reached for comment, Google said in a written statement that it is constantly policing its ad network for bad actors, pointing to an ads safety report (PDF) showing Google blocked or removed 5.1 billion bad ads last year — including more than 500 million ads related to trademarks.
“Our policy against Enabling Dishonest Behavior prohibits products or services that help users mislead others, including ads for paper-writing or exam-taking services,” the statement reads. “When we identify ads or advertisers that violate our policies, we take action, including by suspending advertiser accounts, disapproving ads, and restricting ads to specific domains when appropriate.”
Google did not respond to specific questions about the advertising entities mentioned in this story, saying only that “we are actively investigating this matter and addressing any policy violations, including suspending advertiser accounts when appropriate.”
From reviewing the ad accounts that have been promoting these scam websites, it appears Google has very recently acted to remove a large number of the offending ads. Prior to my notifying Google about the extent of this ad network on April 28, the Google Ad Transparency network listed over 500 ads for 360 Digital Marketing; as of this publication, that number had dwindled to 10.
On April 30, Google announced that starting this month its ads transparency page will display the payment profile name as the payer name for verified advertisers, if that name differs from their verified advertiser name. Searchengineland.com writes the changes are aimed at increasing accountability in digital advertising.
This spreadsheet lists the domain names, advertiser names, and Google Ad Transparency links for more than 350 entities offering ghostwriting, publishing, web design and academic cheating services.
KrebsOnSecurity would like to thank the anonymous security researcher NatInfoSec for their assistance in this investigation.
For further reading on Abtach and its myriad companies in all of the above-mentioned verticals (ghostwriting, logo design, etc.), see this Wikiwand entry.
It was at the invitation of The Long Now Foundation that I visited Mount Washington for the first time as a graduate student. Camping out the first night on the mountain with my kind and curious Long Now friends, I could sense that the experience was potentially transformative — that this place, and this community, had together created a kind of magic. The next morning, we packed up our caravan of cars and made our way up the mountain. I tracked the change in elevation out the car window by observing how the landscape changed from sagebrush to pinyon and juniper trees, to manzanita and mixed conifer, and finally to the ancient bristlecone pines. As we rose, the view of the expansive Great Basin landscape grew below us. It was then that I knew I had to be a part of the community stewarding this incredibly meaningful place.
I’d entered graduate school following an earlier life working on long-term environmental monitoring networks across the U.S. and Latin America, and was attracted to the mountain’s established research network. My early experiences and relationships with other researchers had planted the seeds of appreciation for research which takes the long view of the world around us. Now, as a research professor at the Desert Research Institute (DRI) and a Long Now Research Fellow, I’m helping to launch a new scientific legacy in the Nevada Bristlecone Preserve. Of course, no scientific legacy is entirely new. My work compiling the first decade of observational climate data builds on decades of research in order to help carry it into the future — one link in a long line of scientists who have made my work possible. Science works much like an ecosystem, with different disciplines interweaving to help tell the story of the whole. Each project and scientist builds on the successes of the past.
Unfortunately, the realities of short-term funding don’t often align with a long-term vision for research. Scientists hoping to answer big questions often find it challenging to identify funding that will support a project beyond two to three years, making it difficult to sustain the long-term research that helps illuminate changes in landscapes over time. This reality highlights the value of partnering with The Long Now Foundation. Their support is helping me carry valuable research into the future to understand how rare ecosystems in one of the least-monitored regions in the country are adapting to a warming world.
Left: The Sagebrush East Weather station is a key monitoring post within the NevCAN network. Photo by Anne Heggli. Right: Anne Heggli, Bjoern Bingham and Greg McCurdy working on upgrading one of the 8 stations that make up the NevCAN network. Photo by Scotty Strachan.
The Nevada Bristlecone Preserve stretches across the high reaches of Mount Washington on the far eastern edge of Nevada. Growing where nearly nothing else can, the bristlecone pines (Pinus longaeva) that lend the preserve its name have a gnarled, twisted look to them, and wood so dense that it helps protect the tree from rot and disease. Trees in this grove are known to be nearly 5,000 years old, making them among the oldest living trees in the world. Because of the way trees radiate from their center as they grow, adding one ring essentially every year, scientists can gain glimpses of the past by studying their cores. Counting backward in time, we can visualize years with plentiful water and sunlight for growth as thicker, denser lines indicating a higher growth rate. Trees this old provide a nearly unprecedented time capsule of the climate that produced them, helping us to understand how today’s world differs from the one of our ancestors.
L: The view from the mine site midway up Mt. Washington, looking west. Photo by Anne Heggli. C: View from the Montane station looking at Mt. Washington. Photo by Dan McEvoy. R: The field crew uploading gear to upgrade the highest elevation station in Nevada in the subalpine region of Mt. Washington. Photo by Bjoern Bingham.
This insight has always been valuable but is becoming even more critical as we face increasing temperatures outside the realm of what much of modern life has adapted to. My research aims to provide a nearly microscopic look at how the climate in the Great Basin is changing, from hour to hour and season to season. With scientific monitoring equipment positioned from the floor of the Great Basin’s Spring Valley up to the peak of Mount Washington, our project examines temperature fluctuations, atmospheric information, and snowpack insights across the region’s ecosystems by collecting data every 10 minutes. Named the Nevada Climate-Ecohydrological Assessment Network, or NevCAN, the research effort is now in its second decade. First established in part by my predecessors at DRI along with other colleagues from the Nevada System of Higher Education, the project offers a wealth of valuable climate monitoring information that can contribute to insights across scientific disciplines.
Thanks to the foresight of the scientists who came before me, the data collected provides insight across ecosystems, winding from the valley floor’s sagebrush landscape to Mount Washington’s mid-elevation pinyon-juniper woodlands, to the higher elevation bristlecone pine grove, before winding down the mountain’s other side. The data from Mount Washington can be compared to a similar set of monitoring equipment set up across the Sheep Range just north of Las Vegas. Here, the lowest elevation stations sit in the Mojave Desert, among sprawling creosote-brush and Joshua trees, before climbing up into mid-elevation pinyon-juniper forests and high elevation ponderosa pine groves.
Having over 10 years of data from the Nevada Bristlecone Preserve allows us to zoom in and out on the environmental processes that shape the mountain. Through this research, we’ve been able to ask questions that span timelines, from the 10-minute level of our data collection to the 5,000-year-old trees to the epochal age of the rocks and soil underlying the mountain. We can look at rapid environmental changes during sunrise and sunset or during the approach and onset of a quick thunderstorm. And we can zoom out to understand the climatology by looking at trends in changes in precipitation and temperature that impact the ecosystems.
L: Anne Heggli working analyzing the snowpack from a snow pit measurement. Photo by Elyse DeFranco. C: Anne Heggli, Greg McCurdy and Bjoern Bingham working and enjoying lunch while upgrading the Montane station on Mount Washington. Photo by Dan McEvoy. R: Anne Heggli jumping for joy at Sagebrush West station that the team is putting the necessary time and upgrades into the NevCAN transect. Photo by Bjoern Bingham.
Scientists use data to identify stories in the world around us. Data can show us temperature swings of more than 50 degrees Fahrenheit in just 10 minutes with the onset of a dark and cold thunderstorm in the middle of August. We can observe the impacts of the nightly down-sloping winds that drive the coldest air to the bottom of the valley, helping us understand why the pinyon and juniper trees are growing at higher elevation, where it’s counterintuitively warmer. These first 10 years of data allow us to look at air temperature and precipitation trends, and the next 20 years of data will help us uncover some of the more long-term climatological changes occurring on the mountain. All the while, the ancient bristlecone pines have been collecting data for us over centuries — and millennia — in their tree rings.
The type of research we’re doing with NevCAN facilitates scientific discovery that crosses the traditional boundaries of academic disciplines. The scientists who founded the program understood that the data collected on Mount Washington would be valuable to a range of researchers in different fields and intentionally brought these scientists together to create a project with foresight and long-term value to the scientific community. Building interdisciplinary teams to do this kind of science means that we can cross sectors to identify drivers of change. This mode of thinking acknowledges that the atmosphere impacts the weather, which drives rain, snow, drought, and fire risk. It acknowledges that as the snowpack melts or the monsoonal rains fall, the hydrologic response feeds streams, causes erosion, and regenerates groundwater. The atmospheric and hydrological cycles impact the ecosystem, driving elevational shifts in species, plant die-offs, or the generation of new growth after a fire.
To really understand the mountain, we need everyone’s expertise: atmospheric scientists, hydrologists, ecologists, dendrochronologists, and even computer scientists and engineers to make sure we can get the data back to our collective offices to make meaning of it all. This kind of interdisciplinary science offers the opportunity to learn more about the intersection of scientific studies — a sometimes messy process that reflects the reality of how nature operates.
Conducting long-term research like NevCAN is challenging for a number of reasons beyond finding sustainable funding, but the return is much greater than the sum of its parts. In order to create continuity between researchers over the years, the project team needs to identify future champions to pass the baton to, and systems that can preserve all the knowledge acquired. Over the years, the project’s technical knowledge, historical context, and stories of fire, wildlife, avalanches, and erosion continue to grow. Finding a cohesive team of dedicated people who are willing to be a single part of something bigger takes time, but the trust fostered within the group enables us to answer thorny and complex questions about the fundamental processes shaping our landscape.
Being a Long Now Research Fellow funded by The Long Now Foundation has given me the privilege of being a steward of this mountain and of the data that facilitates this scientific discovery. This incredible opportunity allows me to be a part of something larger than myself and something that will endure beyond my tenure. It means that I get to be a mentee of some of the skilled stewards before me and a mentor to the next generation. In this way we are all connected to each other and to the mountain. We connect with each other by untangling difficult scientific questions; we connect with the mountain by spending long days traveling, camping, and experiencing the mountain from season to season; and we connect with the philosophy of The Long Now Foundation by fostering a deep appreciation for thinking on timescales that surpass human lifetimes.
Setting up Alicia Eggert’s art exhibition on the top of Mt Washington. Photo by Anne Heggli.
…the average American, I think, has fewer than three friends. And the average person has demand for meaningfully more, I think it's like 15 friends or something, right?
- Mark Zuckerberg, presumably to one of his three friends
Right now, AI is being shoe-horned into everything, whether or not it makes sense. To me, it feels like the dotcom boom again. Millipedes.com! Fungus.net! Business plan? What business plan? Just secure the domain names and crank out some Super Bowl ads. We'll be RICH!
In fact, it's not just my feeling. The Large Language Model (LLM) OpenAI is being wildly overvalued and overhyped. It's hard to see how it will generate more revenue while its offerings remain underwhelming and unreliable in so many ways. Hallucination, bias, and other fatal flaws make it a non-starter for businesses like journalism that must have accurate output. Why would anyone convert to a paid plan? Even if there weren't an income problem—even if every customer became a paying customer—generative AI's exorbitant operational and environmental costs are poised to drown whatever revenue and funding they manage to scrape together.
A moment like this requires us to step back, take a deep breath. With sober curiosity, we gotta explore and understand AI's true strengths and weaknesses. More importantly, we have to figure out what we are and aren't willing to accept from AI, personally and as a society. We need thoughtful ethics and policies that protect people and the environment. We need strong laws to prevent the worst abuses. Plenty of us have already been victimized by the absence of such. For instance, one of my own short stories was used by Meta without permission to train their AI.
The Worst of AI Sadly, it is all too easy to find appalling examples of all the ways generative AI is harming us. (For most of these, I'm not going to provide links because they don't deserve the clicks):
We all know that person who no longer seems to have a brain of their own because they keep asking OpenAI to do all of their thinking for them.
Deepfakes deliberately created to deceive people.
Cheating by students.
Cheating by giant corporations who are all too happy to ignore IP and copyright when it benefits them (Meta, ahem).
Piles and piles of creepy generated content on platforms like Youtube and TikTok that can be wildly inaccurate.
Scammy platforms like DataAnnotation, Mindrift, and Outlier that offer $20/hr or more for you to "train their AI." Instead, they simply gather your data and inputs and ghost the vast majority of applicants. I tried taking DataAnnotation's test for myself to see what would happen; after all, it would've been nice to have some supplemental income while job hunting. After several weeks, I still haven't heard back from them.
Applicant Tracking Systems (ATS) block job applications from ever reaching a human being for review. As my job search drags on, I feel like my life has been reduced to a tedious slog of keyword matching. Did I use the word "collaboration" somewhere in my resume? Pass. Did I use the word "teamwork" instead? Fail. Did I use the word "collaboration," but the AI failed to detect it, as regularly happens? Fail, fail, fail some more. Frustrated, I and no doubt countless others have been forced to turn to other AIs in hopes of defeating those AIs. While algorithms battle algorithms, companies and unemployed workers are all suffering.
Brace yourself: a 14 year-old killed himself with the encouragement of the chatbot he'd fallen in love with. I can only imagine how many more young people have been harmed and are being actively harmed right now.
The Best of AI? As AI began to show up everywhere, as seemingly everyone from Google to Apple demanded that I start using it, I had initially responded with aversion and resentment. I never bothered with it, I disabled it wherever I could. When people told me to use it, I waved them off. My life seemed no worse for it.
Alas, now AI completely saturates my days while job searching, bringing on even greater resentment. Thousands of open positions for AI-based startups! Thousands of companies demanding expertise in generative AI as if it's been around for decades. Well, gee, maybe my hatred and aversion is hurting my ability to get hired. Am I being a middle-aged Luddite here? Should I be learning more about AI (and putting it on my resume)? Wouldn't I be the bigger person to work past my aversion in order to learn about and highlight some of the ways we can use AI responsibly?
I tried. I really tried. To be honest, I simply haven't found a single positive generative AI use-case that justifies all the harm taking place.
So, What Do We Do? Here are some thoughts: don't invest in generative AI or seek a job within the field, it's all gonna blow. Lobby your government to investigate abuses, protect people, and preserve the environment. Avoid AI usage and, if you're a writer like me, make clear that AI is not used in any part of your process. Gently encourage that one person you know to start thinking for themselves again.
Most critically of all: wherever AI must be used for the time being, ensure that one or more humans review the results.
[Advertisement] Plan Your .NET 9 Migration with Confidence Your journey to .NET 9 is more than just one decision.Avoid migration migraines with the advice in this free guide. Download Free Guide Now!
Author: Colin Jeffrey On some mornings, around eleven, the postman will drop a letter or two into the mail slot. But many of these are not letters – they are coded messages disguised as bills or advertisements. Only I know their secrets. You see, I am a messenger of the gods. Just yesterday, I was […]
Loading times for web pages is one of the key metrics we like to tune. Users will put up with a lot if they feel like they application is responsive. So when Caivs was handed 20MB of PHP and told, "one of the key pages takes like 30-45 seconds to load. Figure out why," it was at least a clear goal.
Combing through that gigantic pile of code to try and understand what was happening was an uphill battle. Eventually, Caivs just decided to check the traffic logs while running the application. That highlighted a huge spike in traffic every time the page loaded, and that helped Caivs narrow down exactly where the problem was.
For every image they want to display in a gallery, they echo out a list item for it, which that part makes sense- more or less. The mix of PHP, JavaScript, JQuery, and HTML tags is ugly and awful and I hate it. But that's just a prosaic kind of awful, background radiation of looking at PHP code. Yes, it should be launched into the Kupier belt (it doesn't deserve the higher delta-V required to launch it into the sun), but that's not why we're here.
The cause of the long load times was in the lines above- where for each image, we getimagesize- a function which downloads the image and checks its stats, all so we can set $image_dimensions. Which, presumably, the server hosting the images uses the query string to resize the returned image.
All this is to check- if the height is greater than the width we force the height to be 432 pixels, otherwise we force the whole image to be 648x432 pixels.
Now, the server supplying those images had absolutely no caching, so that meant for every image request it needed to resize the image before sending. And for reasons which were unclear, if the requested aspect ratio were wildly different than the actual aspect ratio, it would also sometimes just refused to resize and return a gigantic original image file. But someone also had thought about the perils of badly behaved clients downloading too many images, so if a single host were requesting too many images, it would start throttling the responses.
When you add all this up, it meant that this PHP web application was getting throttled by its own file server, because it was requesting too many images, too quickly. Any reasonable user load hitting it would be viewed as an attempted denial of service attack on the file hosting backend.
Caivs was able to simply remove the check on filesize, and add a few CSS rules which ensured that files in the gallery wouldn't misbehave terribly. The performance problems went away- at least for that page of the application. Buried in that 20MB of PHP/HTML code, there were plenty more places where things could go wrong.
[Advertisement]
Utilize BuildMaster to release your software with confidence, at the pace your business demands. Download today!
Author: Julian Miles, Staff Writer The control room is gleaming. Elias Medelsson looks about with a smile. The night watch clearly made a successful conversion of tedium to effort. He’ll drop a memo to his counterpart on the Benthusian side to express thanks. “Captain Medelsson.” Elias turns to find Siun Heplepara, the Benthusian he had […]
A Chinese company has developed an AI-piloted submersible that can reach speeds “similar to a destroyer or a US Navy torpedo,” dive “up to 60 metres underwater,” and “remain static for more than a month, like the stealth capabilities of a nuclear submarine.” In case you’re worried about the military applications of this, you can relax because the company says that the submersible is “designated for civilian use” and can “launch research rockets.”
Reporting on the rise of fake students enrolling in community college courses:
The bots’ goal is to bilk state and federal financial aid money by enrolling in classes, and remaining enrolled in them, long enough for aid disbursements to go out. They often accomplish this by submitting AI-generated work. And because community colleges accept all applicants, they’ve been almost exclusively impacted by the fraud.
The article talks about the rise of this type of fraud, the difficulty of detecting it, and how it upends quite a bit of the class structure and learning community.
Recent research reveals that high-quality deepfakes unintentionally retain the heartbeat patterns from their source videos, undermining traditional detection methods that relied on detecting subtle skin color changes linked to heartbeats.
The assumption that deepfakes lack physiological signals, such as heart rate, is no longer valid. This challenges many existing detection tools, which may need significant redesigns to keep up with the evolving technology.
To effectively identify high-quality deepfakes, researchers suggest shifting focus from just detecting heart rate signals to analyzing how blood flow is distributed across different facial regions, providing a more accurate detection strategy.
She stared at it for awhile, trying to understand what the hell this was doing, and why it was dividing by three billion. Also, why there was a && in there. But after staring at it for a few minutes, the sick logic of the code makes sense. getTime returns a timestamp in milliseconds. 3.15576e10 is the number of milliseconds in a year. So the Math.floor() expression just gets the difference between two dates as a number of years. The && is just a coalescing operator- the last truthy value gets returned, so if for some reason we can't calculate the number of years (because of bad input, perhaps?), we just return the original input date, because that's a brillant way to handle errors.
As bizarre as this code is, this isn't the code that was causing problems. It works just fine. So why did Alice get a ticket? She spent some more time puzzling over that, while reading through the code, only to discover that this calcYears function was used almost everywhere in the code- but in one spot, someone decided to write their own.
if (birthday) {
let year = birthday?.split('-', 1)
if (year[0] != '') {
let years = newDate().getFullYear() - year[0]
return years
}
}
So, this function also works, and is maybe a bit more clear about what it's doing than the calcYears. But note the use of split- this assumes a lot about the input format of the date, and that assumption isn't always reliable. While calcYears still does unexpected things if you fail to give it good input, its accepted range of inputs is broader. Here, if we're not in a date format which starts with "YYYY-", this blows up.
After spending hours puzzling over this, Alice writes:
I HATE HOW NO ONE KNOWS HOW TO CODE
[Advertisement]
Keep the plebs out of prod. Restrict NuGet feed privileges with ProGet. Learn more.
Author: Chelsea Utecht Today is the day our masters treat us to sweet snacks of expensive corn and sing a song to celebrate their love for us – “Happy Earth Day to you! Happy Earth Day to you! Happy Earth day, our humans!” – because today the orbit aligns so that we can see a […]

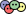
 June that is.
June that is.















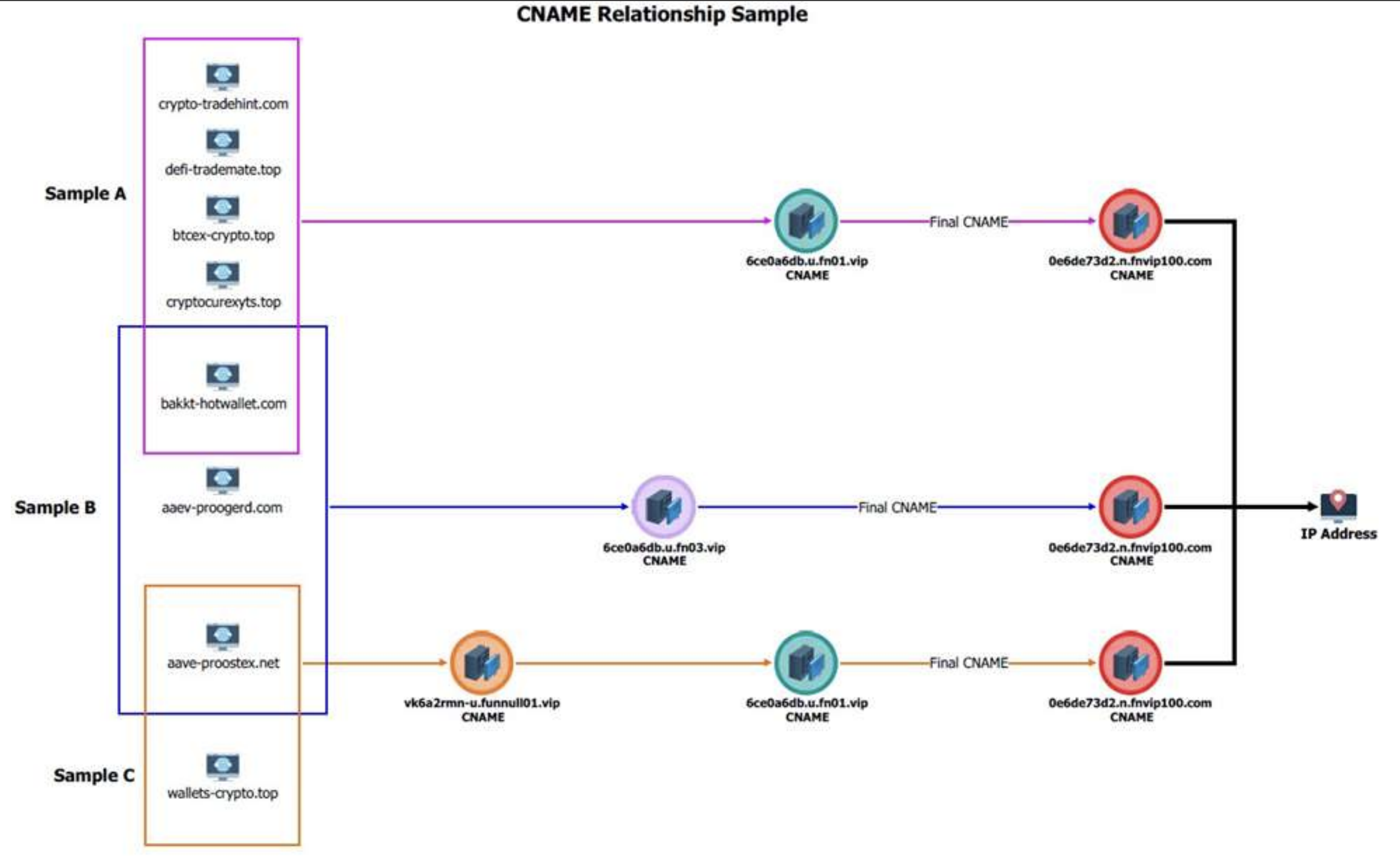


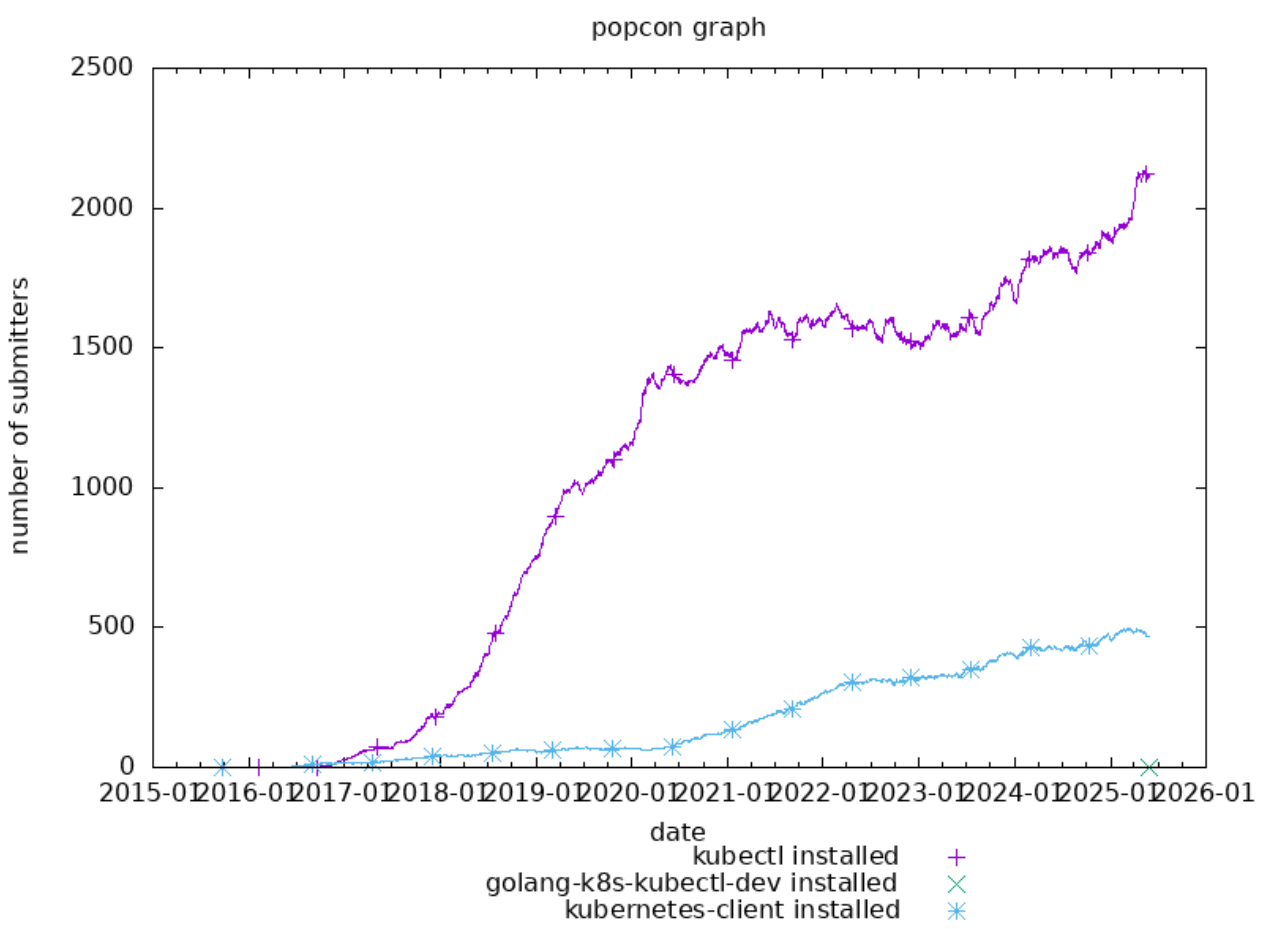




























































 I haven’t had time to blog, but today is my birthday and taking some time to myself!
I haven’t had time to blog, but today is my birthday and taking some time to myself!



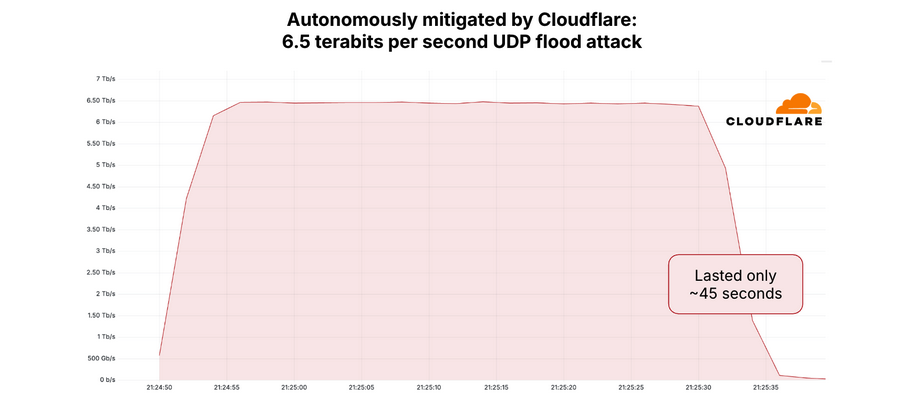
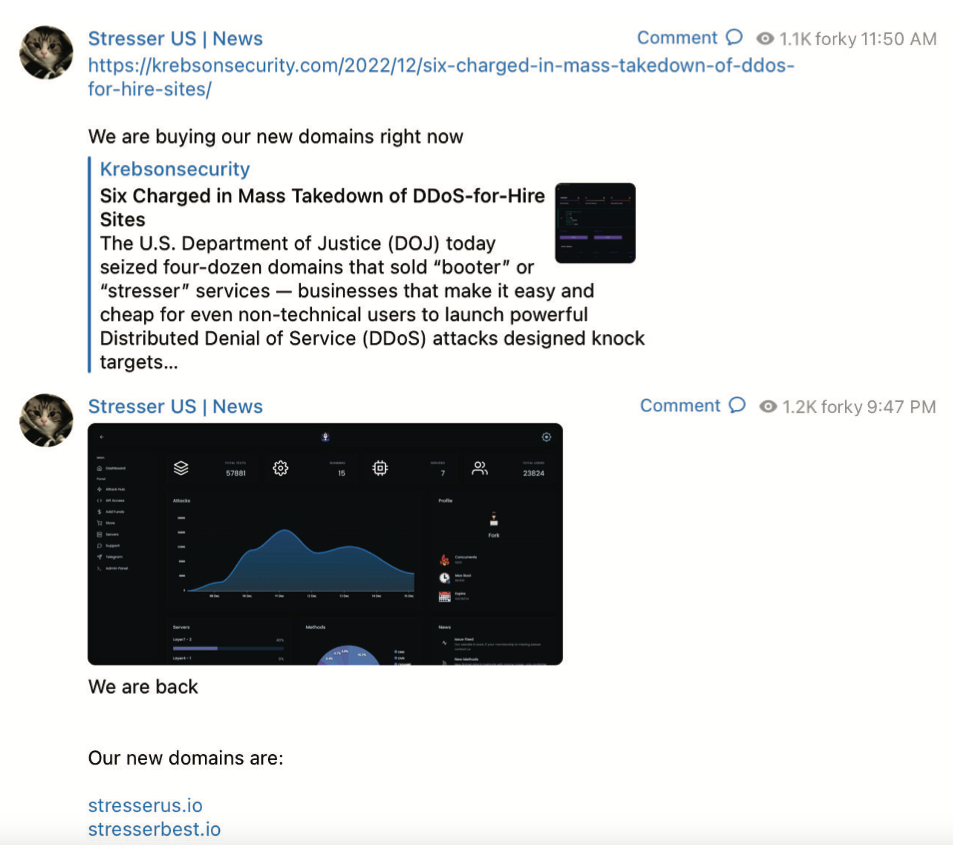







































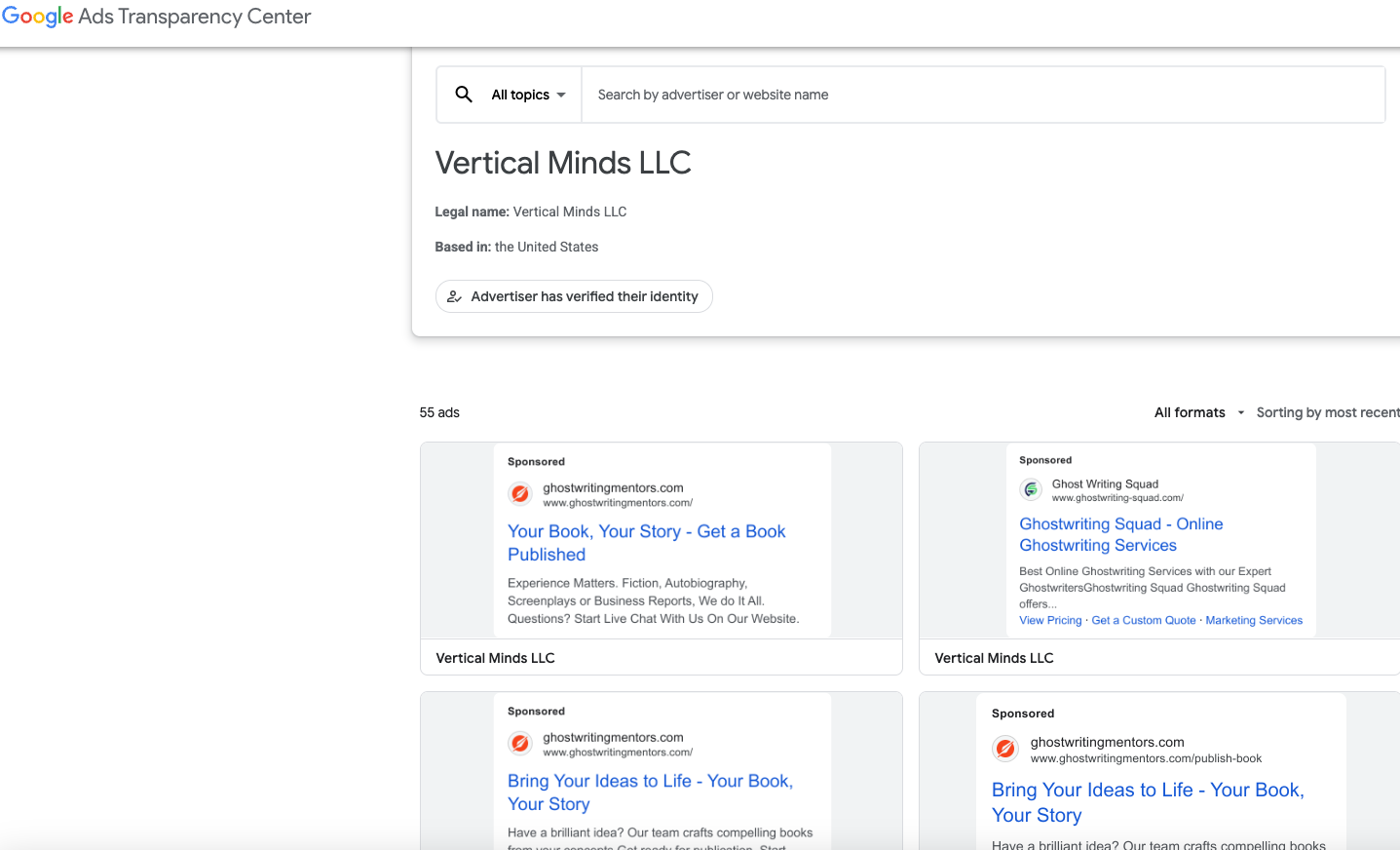

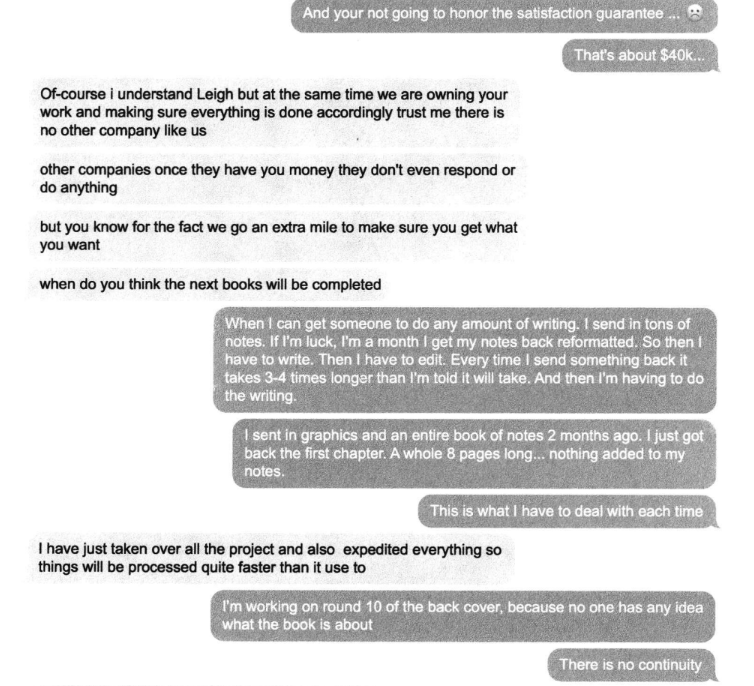

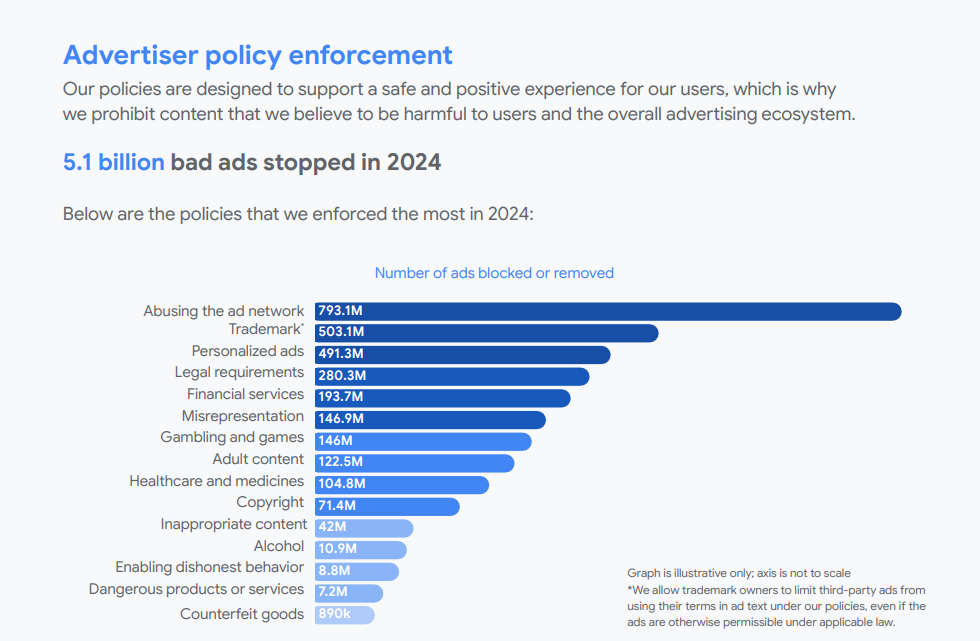













{kind=link}
,_Sea_Point,_Nachtansicht_--_2024_--_1867-70_-_2.jpg){kind=link}
{kind=link}
{kind=link}