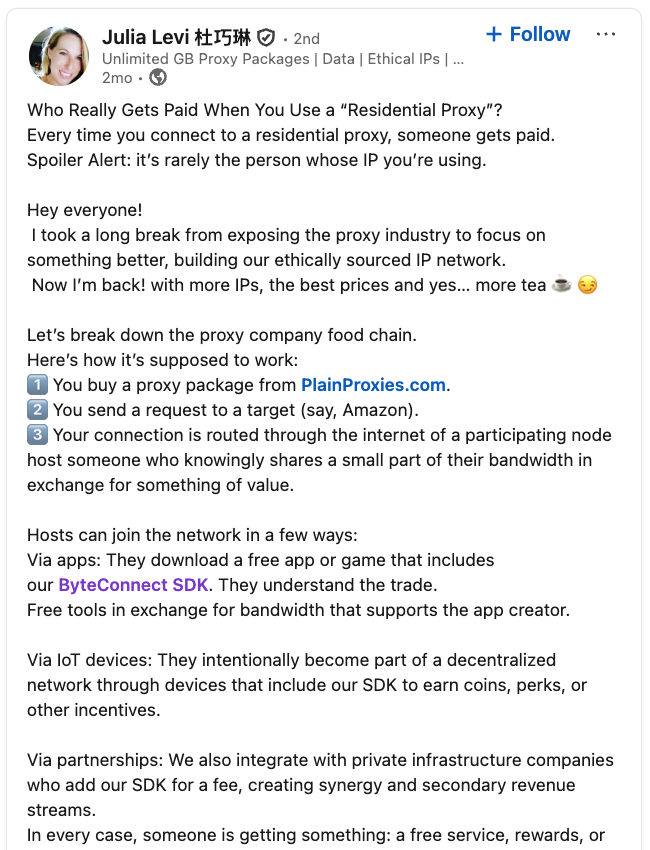
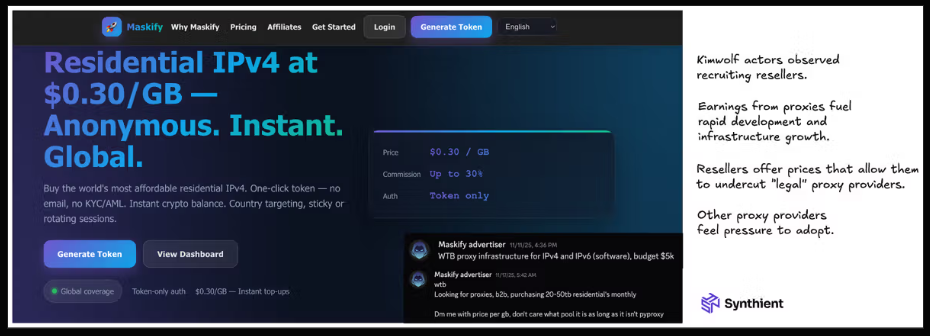
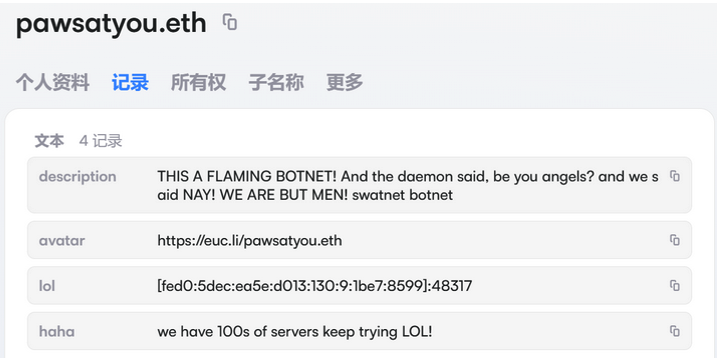
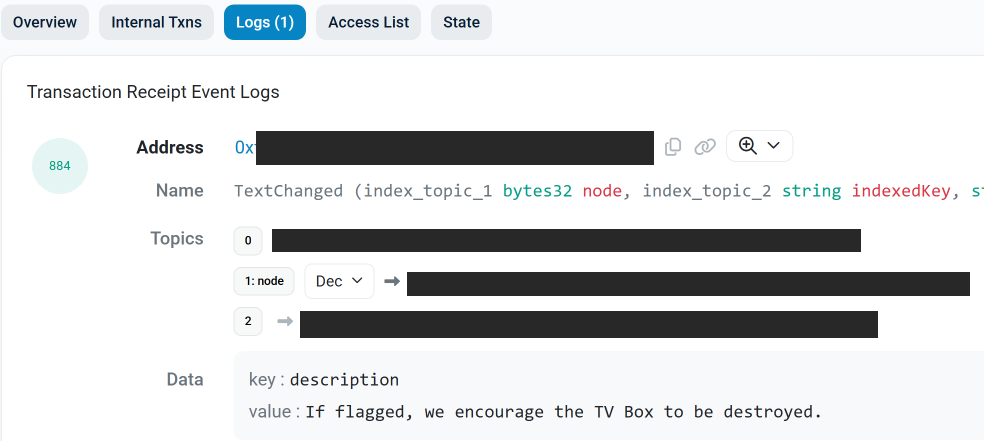
I doubt many will show up here. Part One and Part Two were “tl;dr”… as well as jarring! Still, shall we get to the MEATY PART?
HERE IN PART THREE IS THE BIG SUMMARY of all 35+ proposals.
DRAFTING A NEWER DEMOCRATIC
DEAL WITH THE AMERICAN PEOPLE
Part One and Part Two aimed to study an old - though successful - political tactic that was concocted and executed with great skill by a rather different version of Republicans. A tactic that later dissolved into a swill of broken promises, after achieving Power.
So, shall we wind this up with a shopping list of our own? What follows is a set of promises – a contract of our own, aiming for the spirit of FDR's New Deal – with the citizens of America.
Hoping you will find it LBWR... long but worth reading.
First, yes. It is hard to see, in today's ruling coalition of kleptocrats, fanatics and liars, any of the genuinely sober sincerity than many Americans thought they could sense coming from Newt Gingrich and the original wave of "neoconservatives." Starting with Dennis Never Negotiate Hastert, the GOP leadership caste spiraled into ever-accelerating scandal and corruption.
Still, I propose to ponder what a "Democratic Newest Deal for America" might look like!
- Exposing hypocrisy and satirizing the failure of that earlier "contract" … while using its best parts to appeal sincere moderates and conservatives …
- while firmly clarifying the best consensus liberal proposals…
- while offering firm methods to ensure that any reforms actually take effect and don’t just drift away.
Remember that this alternative "contract" – or List of Democratic Intents – will propose reforms that are of real value… but also repeatedly highlight GOP betrayals.
Might it be worth testing before some focus groups?
A Draft: Democratic Deal for America
As Democratic Members of the House of Representatives and as citizens seeking to join that body, we propose both to change its practices and to restore bonds of trust between the people and their elected representatives.
We offer these proposals in sincere humility, aware that so many past promises were broken. We shall foremost, emphasize restoration of a citizen's right to know, and to hold the mighty accountable.
Especially, we will emphasize placing tools of democracy, openness and trust back into the hands of the People. We will also seek to ensure that government re-learns its basic function, to be the efficient, honest and effective tool of the People.
Toward this end, we’ll incorporate lessons of the past and goals for the future, promises that were betrayed and promises that need to be renewed, ideas from left, right and center. But above all, the guiding principle that America is an open society of bold and free citizens. Citizens who are empowered to remind their political servants who is boss.
PART I. REFORM CONGRESS
In the first month of the new Congress, our new Democratic majority will pass the following major reforms of Congress itself, aimed at restoring the faith and trust of the American people:
FIRST: We shall see to it that the best parts of the 1994 Republican “Contract With America” - parts the GOP betrayed, ignored and forgot - are finally implemented, both in letter and in spirit.
Among the good ideas the GOP betrayed are these:
• Require all laws that apply to the rest of the country also apply to Congress;
• Arrange regular audits of Congress for waste or abuse;
• Limit the terms of all committee chairs and party leadership posts;
• Ban the casting of proxy votes in committee and law-writing by lobbyists;
• Require that committee meetings be open to the public;
• Guarantee honest accounting of our Federal Budget.
…and in the same spirit…
• Members of Congress shall report openly all stock and other trades by members or their families, especially those trades which might be affected by the member’s inside knowledge.
By finally implementing these good ideas – some of which originated with decent Republicans - we show our openness to learn and to reach out, re-establishing a spirit of optimistic bipartisanship with sincere members of the opposing party, hopefully ending an era of unwarranted and vicious political war.
But restoring those broken promises will only be the beginning.
SECOND: We shall establish rules in both House and Senate permanently allowing the minority party one hundred subpoenas per year, plus the time and staff needed to question their witnesses before open subcommittee hearings, ensuring that Congress will never again betray its Constitutional duty of investigation and oversight, even when the same party holds both Congress and the Executive.
As a possibly better alternative – to be negotiated – we shall establish a permanent rule and tradition that each member of Congress will get one peremptory subpoena per year, plus adequate funding to compel a witness to appear and testify for up to five hours before a subcommittee in which she or he is a member. In this way, each member will be encouraged to investigate as a sovereign representative and not just as a party member.
THIRD: While continuing ongoing public debate over the Senate’s practice of filibuster, we shall use our next majority in the Senate to restore the original practice: that senators invoking a filibuster must speak on the chamber floor the entire time.
FOURTH: We shall create the office of Inspector General of the United States, or IGUS, who will head the U.S. Inspectorate, a uniformed agency akin to the Public Health Service, charged with protecting the ethical and law-abiding health of government. Henceforth, the inspectors-general in all government agencies, including military judge-advocates general (JAGs) will be appointed by and report to IGUS, instead of serving at the whim of the cabinet or other officers that they are supposed to inspect. IGUS will advise the President and Congress concerning potential breaches of the law. IGUS will provide protection for whistle-blowers and safety for officials refusing to obey unlawful orders.
In order to ensure independence, the Inspectorate shall be funded by an account to pay for operations that is filled by Congress, or else by some other means, a decade in advance. IGUS will be appointed to six-year terms by a 60% vote of a commission consisting of all past presidents and current state governors. IGUS will create a corps of trusted citizen observers, akin to grand juries, cleared to go anywhere and assure the American people that the government is still theirs, to own and control.
FIFTH: Independent congressional advisory offices for science, technology and other areas of skilled, fact-based analysis will be restored in order to counsel Congress on matters of fact without bias or dogma-driven pressure. Rules shall ensure that technical reports may not be re-written by politicians, changing their meaning to bend to political desires.
Every member of Congress shall be encouraged and funded to appoint from their home district a science-and-fact advisor who may interrogate the advisory panels and/or answer questions of fact on the member’s behalf.
SIXTH: New rules shall limit “pork” earmarking of tax dollars to benefit special interests or specific districts. Exceptions must come from a single pool, totaling no more than one half of a percent of the discretionary budget. These exceptions must be placed in clearly marked and severable portions of a bill, at least two weeks before the bill is voted upon. Earmarks may not be inserted into conference reports. Further, limits shall be placed on no-bid, crony, or noncompetitive contracts, where the latter must have firm expiration dates. Conflict of interest rules will be strengthened.
SEVENTH: Create an office that is tasked to translate and describe all legislation in easily understandable language, for public posting at least three days before any bill is voted upon, clearly tracking changes or insertions, so that the public (and even members of Congress) may know what is at stake. This office may recommend division of any bill that inserts or combines unrelated or “stealth” provisions.
EIGHTH: Return the legislative branch of government to the people, by finding a solution to the cheat of gerrymandering, that enabled politicians to choose voters, instead of the other way around. We shall encourage and insist that states do this in an evenhanded manner, either by using independent redistricting commissions or by minimizing overlap between state legislature districts and those for Congress.
NINTH: Newly elected members of Congress with credentials from their states shall be sworn in by impartial clerks of either the House or Senate, without partisan bias, and at the new member’s convenience. The House may be called into session, with or without action by the Speaker, at any time that a petition is submitted to the Chief Clerk that was signed by 40% of the members.
TENTH: One time in any week, the losing side in a House vote may demand and get an immediate non-binding secret polling of the members who just took part in that vote, using technology to ensure reliable anonymity. While this secret ballot will be non-binding legislatively, the poll will reveal whether some members felt coerced or compelled to vote against their conscience. Members who refuse to be polled anonymously will be presumed to have been so compelled or coerced.
II. REFORM AMERICA
Thereafter, within the first 100 days of the new Congress, we shall bring to the House Floor the following bills, each to be given full and open debate, each to be given a clear and fair vote and each to be immediately available for public inspection and scrutiny.
DB Note: The following proposed bills are my own particular priorities, chosen because I believe they are both vitally important and under-appreciated! (indeed, some of them you’ll see nowhere else.)
Their common trait – until you get to #20 – is that they have some possibility of appealing to reasonable people across party lines… the “60%+ rule” that worked so persuasively in 1994.
#20 will be a catch-all that includes a wide swathe of reforms sought by many Democrats – and, likely, by many of you -- but may entail more dispute, facing strong opposition from the other major party.
In other words… as much as you may want the items in #20 – (and I do too: most of them!) -- you are going to have to work hard for them separately from a ‘contract’ like this one, that aims to swiftly take advantage of 60%+ consensus, to get at least an initial tranche of major reforms done.
1. THE SECURITY FOR AMERICA ACT will ensure that top priority goes to America’s military and security readiness, especially our nation's ability to respond to surprise threats, including natural disasters or other emergencies. FEMA and the CDC and other contingency agencies will be restored and enhanced, their agile effectiveness audited. Reserves will be augmented and modernized. Reserves shall not be sent overseas without submitting for a Congressionally certified state of urgency that must be renewed at six-month intervals.
When ordering a discretionary foreign intervention, the President must report probable effects on readiness, as well as the purposes, severity and likely duration of the intervention, as well as credible evidence of need.
All previous Congressional approvals for foreign military intervention or declared states of urgency will be explicitly canceled, so that future force resolutions by Congress to fulfill its Constitutional War Powers will be fresh and germane to each particular event, with explicit expiration dates.
The Insurrection Act shall be unambiguously cancelled. Any urgent federalization and deployment of National Guard or other troops to American cities, on the excuse of civil disorder, shall be supervised by a plenary of the nation’s state governors, who may veto any such deployment by a 40% vote or a signed declaration by twenty governors.
The Commander-in-Chief may not suspend any American law, or the rights of American citizens, without submitting the brief and temporary suspension to Congress for approval in session.
2. THE PROFESSIONALISM ACT will protect the apolitical independence of our intelligence agencies, the FBI, the scientific and technical staff in executive departments, and the United States Military Officer Corps. All shall be given safe ways to report attempts at political coercion or meddling in their ability to give unbiased advice. Any passive refusal to obey a putatively illegal order shall be immediately audited by a random board of quickly available flag officers who by secret ballot may either confirm the refusal or correct the officer's error, or else refer the matter for inquiry.
Whistle-blower protections will be strengthened within the U.S. government.
As described elsewhere, the federal Inspectorate will gather and empower all agency Inspectors General and Judges Advocate General under the independent Inspector General of the United States (IGUS).
NEW PARAGRAPH: Certain positions that have until now been appointed entirely at presidential discretion or whim shall be filled henceforth -- by law -- in ways that narrow selection down to a broad pool pre-approved by pertinent professional organizations. Posts that involve scientific judgement, for example -- such as the heads of NASA, NSF, EPA, CDC and so on may be presidentially appointed only from pools of twenty or more candidates selected by the National Academies of Science and Engineering. The leaders of agencies or institutions bearing on the arts shall be chosen from pools selected by pertinent arts councils, and so on. The Attorney General and other high justice officials and federal judges shall be chosen from large pools of candidates rated 'qualified' by both the American Bar Association and a national academy of police officers.
NEW PARAGRAPH: The Inspector General of the United States (IGUS) shall yearly and anonymously poll the senior 20% of employees at the FBI, CIA and all intelligence agencies, to verify their overall confidence in the leaders that were appointed over them. IGUS shall confidentially relate the results to the president and to senior members of the pertinent Congressional committees. If the poll results are less than satisfactory, a new poll shall be taken in three months, with the results given to all members of Congress.
3. THE SECRECY ACT will ensure that the recent, skyrocketing use of secrecy – far exceeding anything seen during the Cold War - shall reverse course. Independent commissions of trusted Americans shall approve, or set time limits to, all but the most sensitive classifications, which cannot exceed a certain number. These commissions will include some members who are chosen (after clearance) from a random pool of common citizens. Secrecy will not be used as a convenient way to evade accountability.
4. THE SUSTAINABILITY ACT will make it America’s priority to pioneer technological paths toward energy independence, emphasizing economic health that also conserves both national and world resources. Ambitious efficiency and conservation standards may be accompanied by compromise free market solutions that emphasize a wide variety of participants, with the goal of achieving more with less, while safeguarding the planet for our children.
5. THE POLITCAL REFORM ACT will ensure that the nation’s elections take place in a manner that citizens can trust and verify. Political interference in elections will be a federal crime. Strong auditing procedures and transparency will be augmented by whistleblower protections. New measures will distance government officials from lobbyists. Campaign finance reform will reduce the influence of Big Money over politicians. The definition of a ‘corporation’ shall be clarified: so that corporations are neither ‘persons’ nor entitled to use money or other means to meddle in politics, nor to coerce their employees to act politically.
Gerrymandering will be forbidden by national law.
The Voting Rights Act will be reinforced, overcoming all recent Court rationalizations to neuter it.
6. THE TAX REFORM ACT will simplify the tax code, while ensuring that everybody pays their fair share. Floors for the Inheritance Tax and Alternative Tax will be raised to ensure they only affect the truly wealthy, while loopholes used to evade those taxes will be closed. Modernization of the IRS and funding for auditors seeking illicitly hidden wealth shall be ensured by IRS draw upon major penalties that have been imposed by citizen juries.
All tax breaks for the wealthy will be suspended during time of war, so that the burdens of any conflict or emergency are shared by all.
7. THE AMERICAN EXCELLENCE ACT will provide incentives for American students to excel at a range of important fields. This nation must especially maintain its leadership, by training more experts and innovators in science and technology. Education must be a tool to help millions of students and adults adapt, to achieve and keep high-paying 21st Century jobs.
8. THE HEALTHY CHILDREN ACT will provide basic coverage for all of the nation's children to receive preventive care and needed medical attention. Whether or not adults should get insurance using market methods can be argued separately.
But under this act, all U.S. citizens under the age of 25 shall immediately qualify as “seniors” under Medicare, an affordable step that will relieve the nation’s parents of stressful worry. A great nation should see to it that the young reach adulthood without being handicapped by preventable sickness.
9. THE CYBER HYGIENE ACT: Adjusting liability laws for a new and perilous era, citizens and small companies whose computers are infested and used by ‘botnets’ to commit crimes shall be deemed immune from liability for resulting damages, providing that they download and operate a security program from one of a dozen companies that have been vetted and approved for effectiveness by the US Department of Commerce. Likewise, companies that release artificial intelligence programs shall face lessened liability if those programs persistently declare their provenance and artificiality and potential dangers.
NEW PARAGRAPH: IGUS shall supervise an audit of US and state government computer systems for access security, hygiene and modernization needs – prioritizing first those used by defense and intelligence agencies and the U.S. Treasury and Social Security systems.
10. THE TRUTH AND RECONCILIATION ACT: Without interfering in the president's constitutional right to issue pardons for federal offenses, Congress will pass a law defining the pardon process, so that all persons who are excused for either convictions or possible crimes must at least explain those crimes, under oath, before an open congressional committee, before walking away from them with a presidential pass.
If the crime is not described in detail, then a pardon cannot apply to any excluded portion. Further, we shall issue a challenge that no president shall ever issue more pardons than both of the previous administrations, combined.
If it is determined that a pardon was given on quid pro quo for some bribe, emolument, gift or favor, then this act clarifies that such pardons are null and void. Moreover, this applies retroactively for any such pardons in the past.
We will further reverse the current principle of federal supremacy in criminal cases that forbids states from prosecuting for the same crime. Instead, one state with grievance in a federal case may separately try the culprit for a state offense, which - upon conviction by jury - cannot be excused by presidential pardon.
Congress shall act to limit the effect of Non-Disclosure Agreements (NDAs)that squelch public scrutiny of officials and the powerful. With arrangements to exchange truth for clemency, both current and future NDAs shall decay over a reasonable period of time.
Incentives such as clemency will draw victims of blackmail to come forward and expose their blackmailers.
11. THE IMMUNITY LIMITATION ACT: The Supreme Court has ruled that presidents should be free to do their jobs without undue distraction by legal procedures and jeopardies. Taking that into account, we shall nevertheless – by legislation – firmly reject the artificial and made-up notion of blanket Presidential Immunity or that presidents are inherently above the law.
Instead, the Inspector General of the United States (IGUS) shall supervise legal cases that are brought against the president so that they may be handled by the president’s chosen counsel in order of importance or severity, in such a way that the sum of all such external legal matters will take up no more than ten hours a week of a president’s time. While this may slow such processes, the wheels of law will not be fully stopped.
Civil or criminal cases against a serving president may be brought to trial by a simple majority consent of both houses of Congress, though no criminal or civil punishment may be exacted until after the president leaves office, either by end-of-term or impeachment and Senate conviction.
In the event that Congress is thwarted from acting on impeachment or trial, e.g. by some crime that prevents certain members from voting, their proxies may be voted in such matters by their party caucus, until their states complete election of replacements.
(Note: that last paragraph is a late-addition to cover the scenario that was defended by one of Donald Trump’s own attorneys… that in theory a president might shoot enough members of Congress to evade impeachment (or else enough Supreme Court justices) and remain immune from prosecution or any other remedy.)
12. THE FACT ACT: The Fact Act will begin by restoring the media Rebuttal Rule, prying open "echo chamber" propaganda mills. Any channel, or station, or Internet podcast, or meme distributor that accepts advertising or reaches more than 10,000 followers will be required to offer five minutes per day during prime time and ten minutes at other times to reputable and vigorous adversaries. Until other methods are negotiated, each member of Congress shall get to choose one such vigorous adversary, ensuring that all perspectives may be involved.
The Fact Act will further fund experimental Fact-Challenges, where major public disagreements may be openly and systematically and reciprocally confronted with demands for specific evidence.
The Fact Act will restore full funding and staffing to both the Congressional Office of Technology Assessment and the executive Office of Science and Technology Policy (OTSP). Every member of Congress shall be funded to hire a science and fact advisor from their home district, who may interrogate the advisory bodies – an advisor who may also answer questions of fact on the member’s behalf.
This bill further requires that the President must fill, by law, the position of White House Science Adviser from a diverse and bipartisan slate of qualified candidates offered by the Academy of Science. The Science Adviser shall have uninterrupted access to the President for at least two one-hour sessions per month.4
13. THE VOTER ID ACT: Under the 13th and 14th Amendments, this act requires that states mandating Voter ID requirements must offer substantial and effective compliance assistance, helping affected citizens to acquire their entitled legal ID and register to vote.
Any state that fails to provide such assistance, substantially reducing the fraction of eligible citizens turned away at the polls, shall be assumed in violation of equal protection and engaged in illegal voter suppression. If such compliance assistance has been vigorous and effective for ten years, then that state may institute requirements for Voter ID.
In all states, registration for citizens to vote shall be automatic with a driver’s license or passport or state-issued ID, unless the citizen opts-out.
14. THE WYOMING RULE: Congress shall end the arrangement (under the Permanent Apportionment Act of 1929) for perpetually limiting the House of Representatives to 435 members. Instead, it will institute the Wyoming Rule, that the least-populated state shall get one representative and all other states will be apportioned representatives according to their population by full-integer multiples of the smallest state. The Senate’s inherent bias favoring small states should be enough. In the House, all citizens should get votes of equal value. https://thearp.org/blog/the-wyoming-rule/
15: IMMIGRATION REFORM: There are already proposed immigration law reforms on the table, worked out by sincere Democrats and sincere Republicans, back when the latter were a thing. These bipartisan reforms will be revisited, debated, updated and then brought to a vote.
In addition, if a foreign nation is among the top five sources of refugees seeking U.S. asylum from persecution in their homelands, then by law it shall be incumbent upon the political and social elites in that nation to help solve the problem, or else take responsibility for causing their citizens to flee.
Upon verification that their regime is among those top five, that nation’s elites will be billed, enforceably, for U.S. expenses in giving refuge to that nation’s citizens. Further, all trade and other advantages of said elites will be suspended and access to the United States banned, except for the purpose of negotiating ways that the U.S. can help in that nation’s rise to both liberty and prosperity, thus reducing refugee flows in the best possible way.
16: THE EXECUTIVE OFFICE MANAGER: By law we shall establish under IGUS (the Inspectorate) a civil service position of White House Manager, whose function is to supervise all non-political functions and staff. This would include the Executive Mansion’s physical structure and publicly-owned contents, but also policy-neutral services such as the switchboard, kitchens, Travel Office, medical office, and Secret Service protection details, since there are no justifications for the President or political staff to have whim authority over such apolitical employees.
With due allowance and leeway for needs of the Office of President, public property shall be accounted-for. The manager will allocate which portions of any trip expense should be deemed private and thereupon – above a basic allowance – shall be billed to the president or his/her party.
This office shall supervise annual physical and mental examination by external experts for all senior office holders including the President, Vice President, Cabinet members and leaders of Congress.
Any group of twenty senators or House members or state governors may choose one periodical, network or other news source to get credentialed to the White House Press Pool, spreading inquiry across all party lines and ensuring that all rational points of view get access.
17: EMOLUMENTS AND GIFTS ACT: Emoluments and gifts and other forms of valuable beneficence bestowed upon the president, or members of Congress, or judges, or their families or staffs, shall be more strictly defined and transparently controlled. All existing and future presidential libraries or museums or any kind of shrine shall strictly limit the holding, display or lending of gifts to, from, or by a president or ex-president, which shall instead be owned and held (except for facsimiles) by the Smithsonian and/or sold at public auction.
Donations by corporations or wealthy individuals to pet projects of a president or other members of government, including inauguration events, shall be presumed to be illegal bribery unless they are approved by a nonpartisan ethical commission.
18: BUDGETS: If Congress fails to fulfill its budgetary obligations or to raise the debt ceiling, the result will not be a ‘government shutdown.’ Rather, all pay and benefits will cease going to any Senator or Representative whose annual income is above the national average, until appropriate legislation has passed, at which point only 50% of any backlog arrears may be made-up.
19: THE RURAL AMERICA AND HOUSING ACT: Giant corporations and cartels are using predatory practices to unfairly corner, control or force-out family farms and small rural businesses. We shall upgrade FDR-era laws that saved the American heartland for the people who live and work there, producing the nation’s food. Subsidies and price supports shall only go to family farms or co-ops. Monopolies in fertilizer, seeds and other supplies will be broken up and replaced by competition. Living and working and legal conditions for farm workers and food processing workers will be improved by steady public and private investments.
Cartels that buy-up America’s stock of homes and home-builders will be investigated for collusion to limit construction and/or drive up rents and home prices and appropriate legislation will follow.
20: THE INTENT OF CONGRESS ACT: We shall pass an act preventing the Supreme Court from canceling laws based on contorted interpretations of Congressional will or intent. For example, the Civil Rights Bill shall not be interpreted as having “completed” the work assigned to it by Congress, when it clearly has not done so. In many cases, this act will either clarify Congressional purpose and intent or else amend certain laws to ensure that Congressional intent is crystal clear, removing that contorted rationalization. This will not interfere in Supreme Court decisions based on Constitutionality. But interpretations of Congressional intent should at least consult with Congress, itself.
21: THE LIBERAL AGENDA: Okay. Your turn. Our turn. Beyond the 60% rule.
· Protect women’s autonomy, credibility and command over their own bodies,
· Ease housing costs: stop private corps buying up large tracts of homes, colluding on prices. (See #19.)
· Help working families with child care and elder care.
· Consumer protection, empower the Consumer Financial Protection Board.
· At least allow student debt refinancing, which the GOP dastardly disallowed.
· Restore the postal savings bank for the un-banked, ensuring every citizen has a basic account that can be used to cash paychecks and run a debit card,
· Basic, efficient, universal background checks for gun purchases, with possible exceptions.
· A national Election Day holiday, for those who actually vote.
· Carefully revive the special prosecutor law.
· Expand and re-emphasize protections under the Civil Service Act.
· Anti-trust breakup of monopoly/duopolies.
·
….AND SO ON… I do not leave those huge items as afterthoughts! They are important. But they will entail huge political fights and restoration of the ability to legislate through negotiation and compromise (now explicitly forbidden int the Republican Congressional caucuses).
Can we learn from the mistakes of Bill Clinton and Barack Obama? Who tried to shoot for the moon in the one Congressional session when each of them had a Congress? And hence failed to accomplish a thing? In contrast Joe Bien's session from 2021-22 was a miracle year when Pelosi+Schumer+Bernie/Liz/AOC together pushed for the achievable... and succeeded!
Do I wish they also passed some of the 35+ proposals listed here? Sure. We'd be in better shape, even if only protecting the JAGs and IGs and such!
Indeed, by going for the achievable, we might GAIN power to do the harder stuff.
III. Conclusion
All right. I know this proposal – that we do a major riff off of the 1994 Republican Contract with America – will garner one top complaint: We don't want to look like copycats!
And yet, by satirizing that totally-betrayed “contract,” we poke GOP hypocrisy… while openly reaching out to the wing of conservatism that truly believed the promises, back in 94, perhaps winning some of them over, by offering deliverable metrics to get it right this time…
…while boldly outlining reasonable liberal measures that the nation desperately needs.
I do not insist that the measures I posed -- in my rough draft "Democratic Deal" -- are the only ones possible! (Some might even seem crackpot… till you think them over.) New proposals would be added or changed.
Still, this list seems reasonable enough to debate, refine, and possibly offer to focus groups. Test marketing (the way Gingrich did!) should tell us whether Americans would see this as "copycat"…
...or else a clever way to turn the tables, in an era when agility must be an attribute of political survival.
---------------------------------------------------------
And after that, I will intermittently examine others, while responding to your comments and criticisms. (Please post them in the LATEST blog, so I will see them.)


 Many individuals use Tor to reduce their visibility to widespread internet surveillance.
Many individuals use Tor to reduce their visibility to widespread internet surveillance. Tor users attempting to contribute to Wikipedia are shown a screen that informs them that they are not allowed to edit Wikipedia.
Tor users attempting to contribute to Wikipedia are shown a screen that informs them that they are not allowed to edit Wikipedia. An exploratory mapping of our themes in terms of the value a type of contribution represents to the Wikipedia community and the importance of anonymity in facilitating it. Anonymity-protecting tools play a critical role in facilitating contributions on the right side of the figure, while edits on the left are more likely to occur even when anonymity is impossible. Contributions toward the top reflect valuable forms of participation in Wikipedia, while edits at the bottom reflect damage.
An exploratory mapping of our themes in terms of the value a type of contribution represents to the Wikipedia community and the importance of anonymity in facilitating it. Anonymity-protecting tools play a critical role in facilitating contributions on the right side of the figure, while edits on the left are more likely to occur even when anonymity is impossible. Contributions toward the top reflect valuable forms of participation in Wikipedia, while edits at the bottom reflect damage.

 Got rid of documents I had for last year's Tax return. Now I have the least document in my bookshelf out of the year.
Got rid of documents I had for last year's Tax return. Now I have the least document in my bookshelf out of the year.
















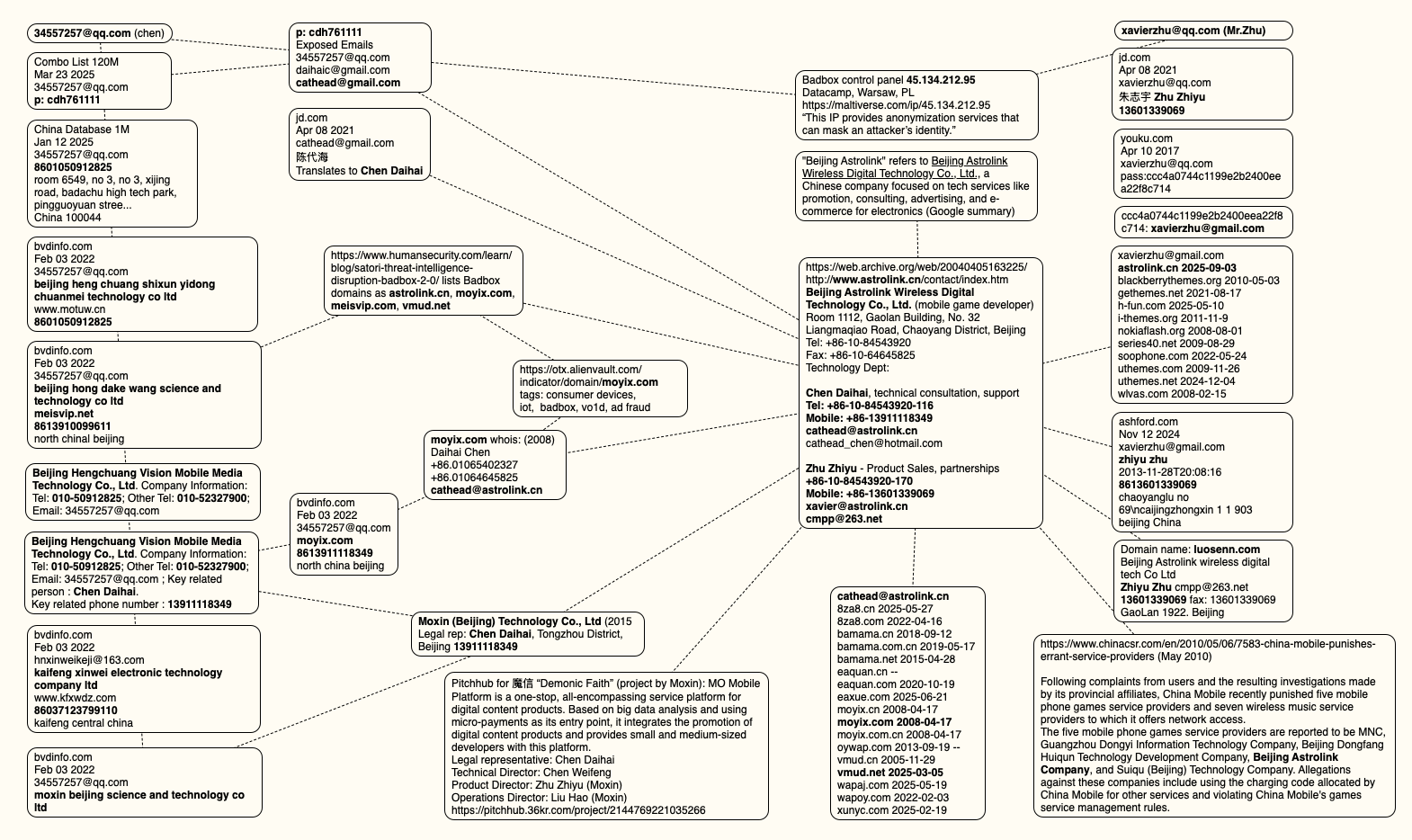
















 I have officially reached the 6-week mark, the halfway point of my Outreachy internship. The time has flown by incredibly fast, yet it feels short because there is still so much exciting work to do.
I have officially reached the 6-week mark, the halfway point of my Outreachy internship. The time has flown by incredibly fast, yet it feels short because there is still so much exciting work to do.


 . I am an intern here at Outreachy working with Debian OpenQA Image testing team. The work consists of testing Images with OpenQA. The internship has reached midpoint and here are some of the highlights that I have had so far.
. I am an intern here at Outreachy working with Debian OpenQA Image testing team. The work consists of testing Images with OpenQA. The internship has reached midpoint and here are some of the highlights that I have had so far.
































 NB: The context menu allows to switch the fonts on systems where the above snippet has not (yet) been installed. So good enough for a one-off.
NB: The context menu allows to switch the fonts on systems where the above snippet has not (yet) been installed. So good enough for a one-off.















{kind=link}
{kind=link}