If you live in the United States, the data broker Radaris likely knows a great deal about you, and they are happy to sell what they know to anyone. But how much do we know about Radaris? Publicly available data indicates that in addition to running a dizzying array of people-search websites, the co-founders of Radaris operate multiple Russian-language dating services and affiliate programs. It also appears many of their businesses have ties to a California marketing firm that works with a Russian state-run media conglomerate currently sanctioned by the U.S. government.
Formed in 2009, Radaris is a vast people-search network for finding data on individuals, properties, phone numbers, businesses and addresses. Search for any American’s name in Google and the chances are excellent that a listing for them at Radaris.com will show up prominently in the results.
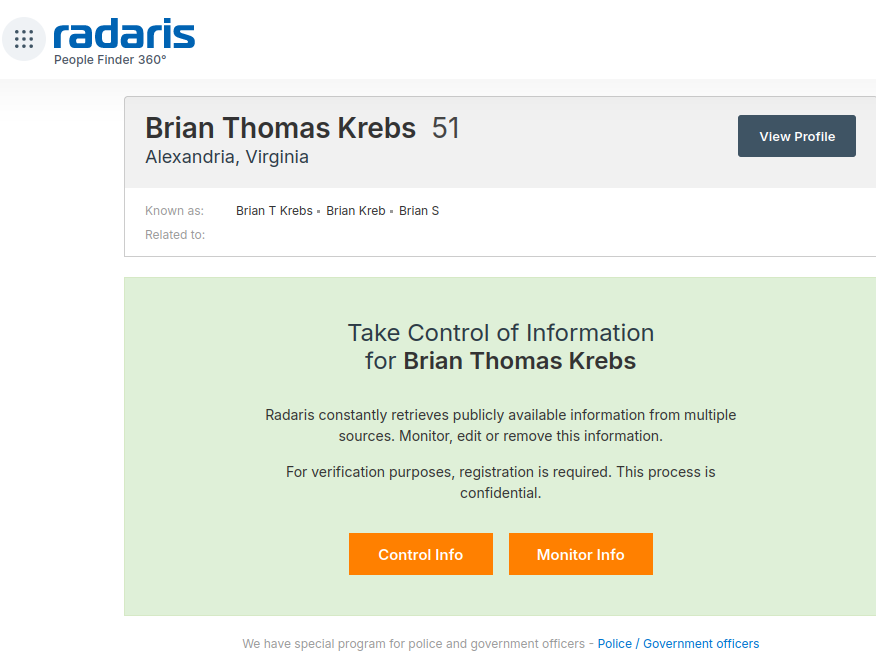
Radaris reports typically bundle a substantial amount of data scraped from public and court documents, including any current or previous addresses and phone numbers, known email addresses and registered domain names. The reports also list address and phone records for the target’s known relatives and associates. Such information could be useful if you were trying to determine the maiden name of someone’s mother, or successfully answer a range of other knowledge-based authentication questions.
Currently, consumer reports advertised for sale at Radaris.com are being fulfilled by a different people-search company called TruthFinder. But Radaris also operates a number of other people-search properties — like Centeda.com — that sell consumer reports directly and behave almost identically to TruthFinder: That is, reel the visitor in with promises of detailed background reports on people, and then charge a $34.99 monthly subscription fee just to view the results.
The Better Business Bureau (BBB) assigns Radaris a rating of “F” for consistently ignoring consumers seeking to have their information removed from Radaris’ various online properties. Of the 159 complaints detailed there in the last year, several were from people who had used third-party identity protection services to have their information removed from Radaris, only to receive a notice a few months later that their Radaris record had been restored.
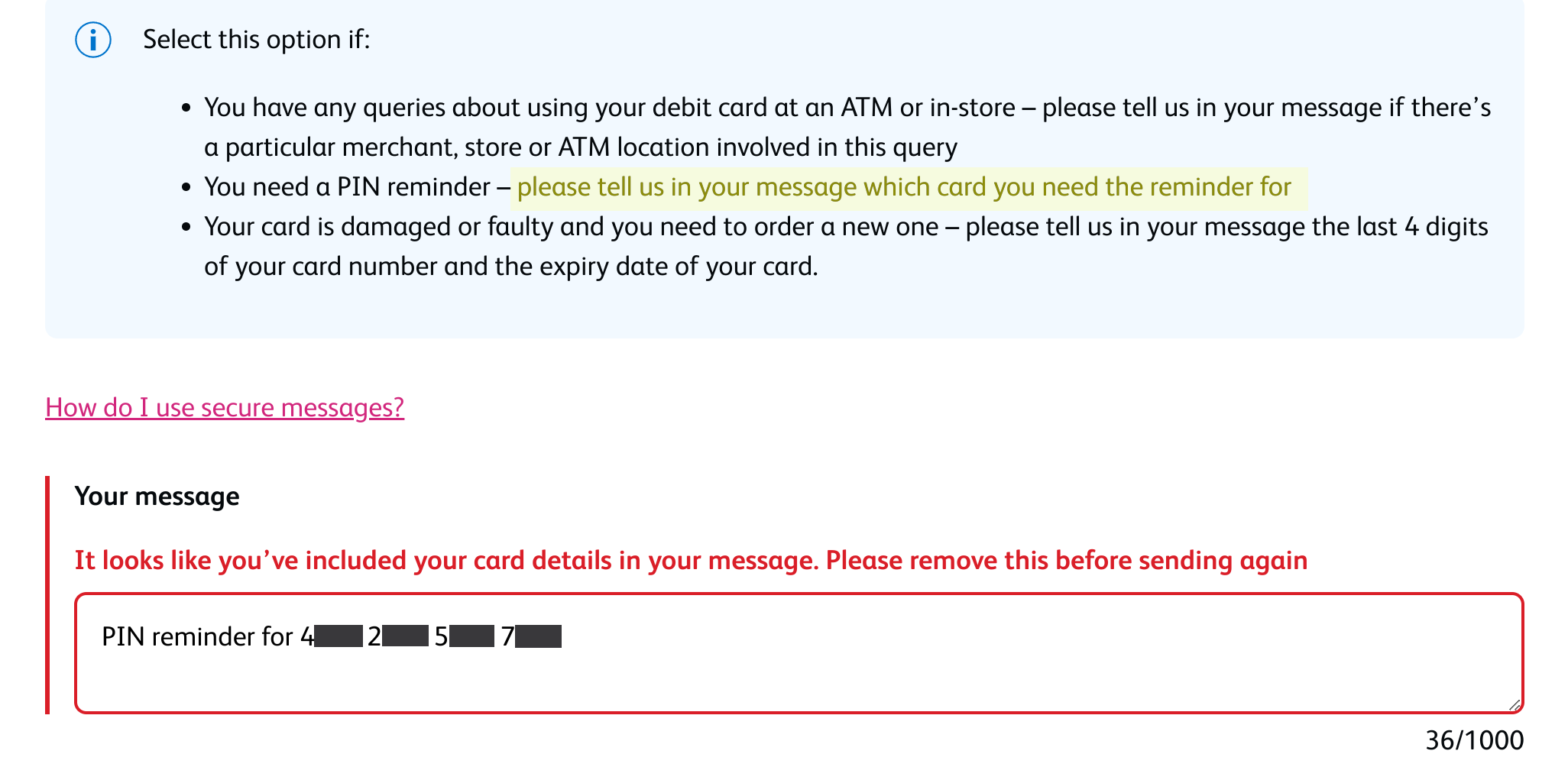
What’s more, Radaris’ automated process for requesting the removal of your information requires signing up for an account, potentially providing more information about yourself that the company didn’t already have (see screenshot above).
Radaris has not responded to requests for comment.
Radaris, TruthFinder and others like them all force users to agree that their reports will not be used to evaluate someone’s eligibility for credit, or a new apartment or job. This language is so prominent in people-search reports because selling reports for those purposes would classify these firms as consumer reporting agencies (CRAs) and expose them to regulations under the Fair Credit Reporting Act (FCRA).
These data brokers do not want to be treated as CRAs, and for this reason their people search reports typically do not include detailed credit histories, financial information, or full Social Security Numbers (Radaris reports include the first six digits of one’s SSN).
But in September 2023, the U.S. Federal Trade Commission found that TruthFinder and another people-search service Instant Checkmate were trying to have it both ways. The FTC levied a $5.8 million penalty against the companies for allegedly acting as CRAs because they assembled and compiled information on consumers into background reports that were marketed and sold for employment and tenant screening purposes.

An excerpt from the FTC’s complaint against TruthFinder and Instant Checkmate.
The FTC also found TruthFinder and Instant Checkmate deceived users about background report accuracy. The FTC alleges these companies made millions from their monthly subscriptions using push notifications and marketing emails that claimed that the subject of a background report had a criminal or arrest record, when the record was merely a traffic ticket.
“All the while, the companies touted the accuracy of their reports in online ads and other promotional materials, claiming that their reports contain “the MOST ACCURATE information available to the public,” the FTC noted. The FTC says, however, that all the information used in their background reports is obtained from third parties that expressly disclaim that the information is accurate, and that TruthFinder and Instant Checkmate take no steps to verify the accuracy of the information.
The FTC said both companies deceived customers by providing “Remove” and “Flag as Inaccurate” buttons that did not work as advertised. Rather, the “Remove” button removed the disputed information only from the report as displayed to that customer; however, the same item of information remained visible to other customers who searched for the same person.
The FTC also said that when a customer flagged an item in the background report as inaccurate, the companies never took any steps to investigate those claims, to modify the reports, or to flag to other customers that the information had been disputed.
WHO IS RADARIS?
According to Radaris’ profile at the investor website Pitchbook.com, the company’s founder and “co-chief executive officer” is a Massachusetts resident named Gary Norden, also known as Gary Nard.
An analysis of email addresses known to have been used by Mr. Norden shows he is a native Russian man whose real name is Igor Lybarsky (also spelled Lubarsky). Igor’s brother Dmitry, who goes by “Dan,” appears to be the other co-CEO of Radaris. Dmitry Lybarsky’s Facebook/Meta account says he was born in March 1963.

The Lybarsky brothers Dmitry or “Dan” (left) and Igor a.k.a. “Gary,” in an undated photo.
Indirectly or directly, the Lybarskys own multiple properties in both Sherborn and Wellesley, Mass. However, the Radaris website is operated by an offshore entity called Bitseller Expert Ltd, which is incorporated in Cyprus. Neither Lybarsky brother responded to requests for comment.
A review of the domain names registered by Gary Norden shows that beginning in the early 2000s, he and Dan built an e-commerce empire by marketing prepaid calling cards and VOIP services to Russian expatriates who are living in the United States and seeking an affordable way to stay in touch with loved ones back home.
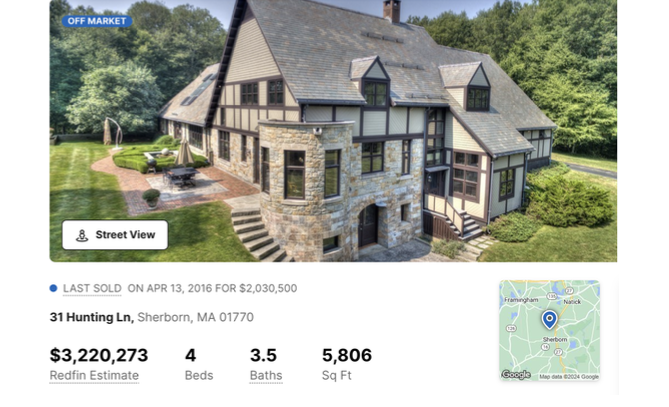
A Sherborn, Mass. property owned by Barsky Real Estate Trust and Dmitry Lybarsky.
In 2012, the main company in charge of providing those calling services — Wellesley Hills, Mass-based Unipoint Technology Inc. — was fined $179,000 by the U.S. Federal Communications Commission, which said Unipoint never applied for a license to provide international telecommunications services.
DomainTools.com shows the email address gnard@unipointtech.com is tied to 137 domains, including radaris.com. DomainTools also shows that the email addresses used by Gary Norden for more than two decades — epop@comby.com, gary@barksy.com and gary1@eprofit.com, among others — appear in WHOIS registration records for an entire fleet of people-search websites, including: centeda.com, virtory.com, clubset.com, kworld.com, newenglandfacts.com, and pub360.com.
Still more people-search platforms tied to Gary Norden– like publicreports.com and arrestfacts.com — currently funnel interested customers to third-party search companies, such as TruthFinder and PersonTrust.com.
The email addresses used by Gary Nard/Gary Norden are also connected to a slew of data broker websites that sell reports on businesses, real estate holdings, and professionals, including bizstanding.com, homemetry.com, trustoria.com, homeflock.com, rehold.com, difive.com and projectlab.com.
AFFILIATE & ADULT
Domain records indicate that Gary and Dan for many years operated a now-defunct pay-per-click affiliate advertising network called affiliate.ru. That entity used domain name servers tied to the aforementioned domains comby.com and eprofit.com, as did radaris.ru.

A machine-translated version of Affiliate.ru, a Russian-language site that advertised hundreds of money making affiliate programs, including the Comfi.com prepaid calling card affiliate.
Comby.com used to be a Russian language social media network that looked a great deal like Facebook. The domain now forwards visitors to Privet.ru (“hello” in Russian), a dating site that claims to have 5 million users. Privet.ru says it belongs to a company called Dating Factory, which lists offices in Switzerland. Privet.ru uses the Gary Norden domain eprofit.com for its domain name servers.
Dating Factory’s website says it sells “powerful dating technology” to help customers create unique or niche dating websites. A review of the sample images available on the Dating Factory homepage suggests the term “dating” in this context refers to adult websites. Dating Factory also operates a community called FacebookOfSex, as well as the domain analslappers.com.
RUSSIAN AMERICA
Email addresses for the Comby and Eprofit domains indicate Gary Norden operates an entity in Wellesley Hills, Mass. called RussianAmerican Holding Inc. (russianamerica.com). This organization is listed as the owner of the domain newyork.ru, which is a site dedicated to orienting newcomers from Russia to the Big Apple.
Newyork.ru’s terms of service refer to an international calling card company called ComFi Inc. (comfi.com) and list an address as PO Box 81362 Wellesley Hills, Ma. Other sites that include this address are russianamerica.com, russianboston.com, russianchicago.com, russianla.com, russiansanfran.com, russianmiami.com, russiancleveland.com and russianseattle.com (currently offline).
ComFi is tied to Comfibook.com, which was a search aggregator website that collected and published data from many online and offline sources, including phone directories, social networks, online photo albums, and public records.
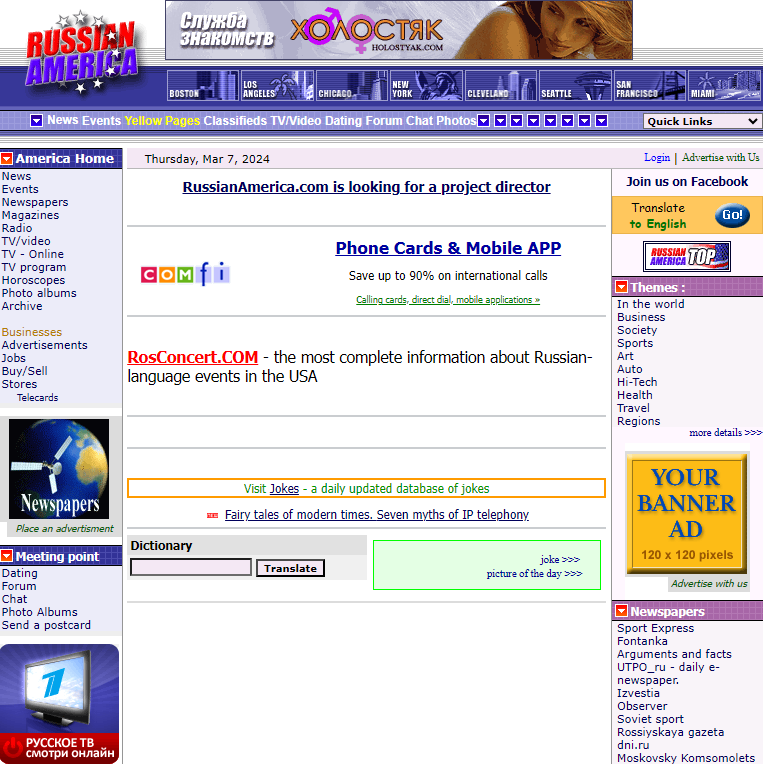
The current website for russianamerica.com. Note the ad in the bottom left corner of this image for Channel One, a Russian state-owned media firm that is currently sanctioned by the U.S. government.
AMERICAN RUSSIAN MEDIA
Many of the U.S. city-specific online properties apparently tied to Gary Norden include phone numbers on their contact pages for a pair of Russian media and advertising firms based in southern California. The phone number 323-874-8211 appears on the websites russianla.com, russiasanfran.com, and rosconcert.com, which sells tickets to theater events performed in Russian.
Historic domain registration records from DomainTools show rosconcert.com was registered in 2003 to Unipoint Technologies — the same company fined by the FCC for not having a license. Rosconcert.com also lists the phone number 818-377-2101.
A phone number just a few digits away — 323-874-8205 — appears as a point of contact on newyork.ru, russianmiami.com, russiancleveland.com, and russianchicago.com. A search in Google shows this 82xx number range — and the 818-377-2101 number — belong to two different entities at the same UPS Store mailbox in Tarzana, Calif: American Russian Media Inc. (armediacorp.com), and Lamedia.biz.
Armediacorp.com is the home of FACT Magazine, a glossy Russian-language publication put out jointly by the American-Russian Business Council, the Hollywood Chamber of Commerce, and the West Hollywood Chamber of Commerce.
Lamedia.biz says it is an international media organization with more than 25 years of experience within the Russian-speaking community on the West Coast. The site advertises FACT Magazine and the Russian state-owned media outlet Channel One. Clicking the Channel One link on the homepage shows Lamedia.biz offers to submit advertising spots that can be shown to Channel One viewers. The price for a basic ad is listed at $500.
In May 2022, the U.S. government levied financial sanctions against Channel One that bar US companies or citizens from doing business with the company.
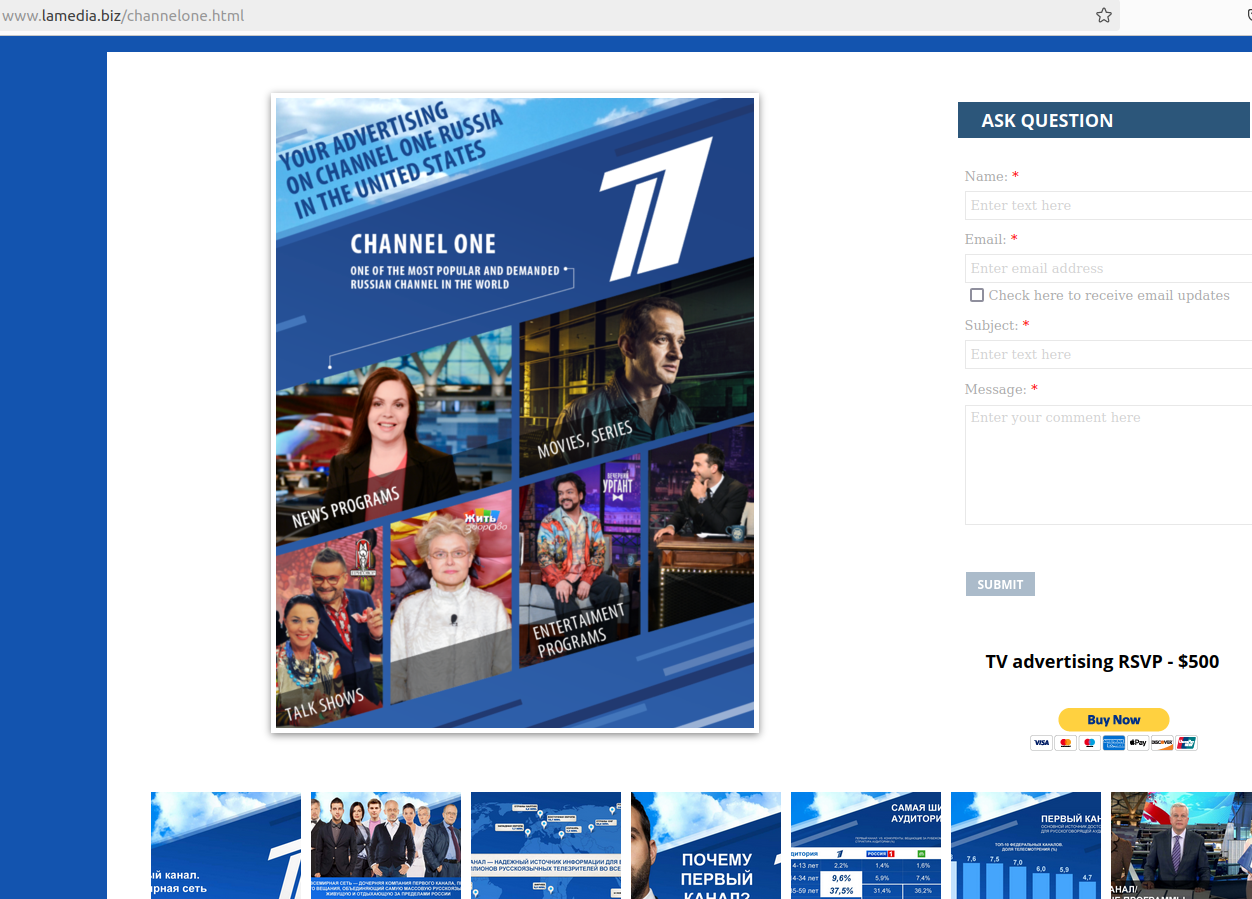
The website of lamedia.biz offers to sell advertising on two Russian state-owned media firms currently sanctioned by the U.S. government.
LEGAL ACTIONS AGAINST RADARIS
In 2014, a group of people sued Radaris in a class-action lawsuit claiming the company’s practices violated the Fair Credit Reporting Act. Court records indicate the defendants never showed up in court to dispute the claims, and as a result the judge eventually awarded the plaintiffs a default judgement and ordered the company to pay $7.5 million.
But the plaintiffs in that civil case had a difficult time collecting on the court’s ruling. In response, the court ordered the radaris.com domain name (~9.4M monthly visitors) to be handed over to the plaintiffs.
However, in 2018 Radaris was able to reclaim their domain on a technicality. Attorneys for the company argued that their clients were never named as defendants in the original lawsuit, and so their domain could not legally be taken away from them in a civil judgment.
“Because our clients were never named as parties to the litigation, and were never served in the litigation, the taking of their property without due process is a violation of their rights,” Radaris’ attorneys argued.
In October 2023, an Illinois resident filed a class-action lawsuit against Radaris for allegedly using people’s names for commercial purposes, in violation of the Illinois Right of Publicity Act.
On Feb. 8, 2024, a company called Atlas Data Privacy Corp. sued Radaris LLC for allegedly violating “Daniel’s Law,” a statute that allows New Jersey law enforcement, government personnel, judges and their families to have their information completely removed from people-search services and commercial data brokers. Atlas has filed at least 140 similar Daniel’s Law complaints against data brokers recently.
Daniel’s Law was enacted in response to the death of 20-year-old Daniel Anderl, who was killed in a violent attack targeting a federal judge (his mother). In July 2020, a disgruntled attorney who had appeared before U.S. District Judge Esther Salas disguised himself as a Fedex driver, went to her home and shot and killed her son (the judge was unharmed and the assailant killed himself).
Earlier this month, The Record reported on Atlas Data Privacy’s lawsuit against LexisNexis Risk Data Management, in which the plaintiffs representing thousands of law enforcement personnel in New Jersey alleged that after they asked for their information to remain private, the data broker retaliated against them by freezing their credit and falsely reporting them as identity theft victims.
Another data broker sued by Atlas Data Privacy — pogodata.com — announced on Mar. 1 that it was likely shutting down because of the lawsuit.
“The matter is far from resolved but your response motivates us to try to bring back most of the names while preserving redaction of the 17,000 or so clients of the redaction company,” the company wrote. “While little consolation, we are not alone in the suit – the privacy company sued 140 property-data sites at the same time as PogoData.”
Atlas says their goal is convince more states to pass similar laws, and to extend those protections to other groups such as teachers, healthcare personnel and social workers. Meanwhile, media law experts say they’re concerned that enacting Daniel’s Law in other states would limit the ability of journalists to hold public officials accountable, and allow authorities to pursue criminals charges against media outlets that publish the same type of public and governments records that fuel the people-search industry.
PEOPLE-SEARCH CARVE-OUTS
There are some pending changes to the US legal and regulatory landscape that could soon reshape large swaths of the data broker industry. But experts say it is unlikely that any of these changes will affect people-search companies like Radaris.
On Feb. 28, 2024, the White House issued an executive order that directs the U.S. Department of Justice (DOJ) to create regulations that would prevent data brokers from selling or transferring abroad certain data types deemed too sensitive, including genomic and biometric data, geolocation and financial data, as well as other as-yet unspecified personal identifiers. The DOJ this week published a list of more than 100 questions it is seeking answers to regarding the data broker industry.
In August 2023, the Consumer Financial Protection Bureau (CFPB) announced it was undertaking new rulemaking related to data brokers.
Justin Sherman, an adjunct professor at Duke University, said neither the CFPB nor White House rulemaking will likely address people-search brokers because these companies typically get their information by scouring federal, state and local government records. Those government files include voting registries, property filings, marriage certificates, motor vehicle records, criminal records, court documents, death records, professional licenses, bankruptcy filings, and more.
“These dossiers contain everything from individuals’ names, addresses, and family information to data about finances, criminal justice system history, and home and vehicle purchases,” Sherman wrote in an October 2023 article for Lawfare. “People search websites’ business pitch boils down to the fact that they have done the work of compiling data, digitizing it, and linking it to specific people so that it can be searched online.”
Sherman said while there are ongoing debates about whether people search data brokers have legal responsibilities to the people about whom they gather and sell data, the sources of this information — public records — are completely carved out from every single state consumer privacy law.
“Consumer privacy laws in California, Colorado, Connecticut, Delaware, Indiana, Iowa, Montana, Oregon, Tennessee, Texas, Utah, and Virginia all contain highly similar or completely identical carve-outs for ‘publicly available information’ or government records,” Sherman wrote. “Tennessee’s consumer data privacy law, for example, stipulates that “personal information,” a cornerstone of the legislation, does not include ‘publicly available information,’ defined as:
“…information that is lawfully made available through federal, state, or local government records, or information that a business has a reasonable basis to believe is lawfully made available to the general public through widely distributed media, by the consumer, or by a person to whom the consumer has disclosed the information, unless the consumer has restricted the information to a specific audience.”
Sherman said this is the same language as the carve-out in the California privacy regime, which is often held up as the national leader in state privacy regulations. He said with a limited set of exceptions for survivors of stalking and domestic violence, even under California’s newly passed Delete Act — which creates a centralized mechanism for consumers to ask some third-party data brokers to delete their information — consumers across the board cannot exercise these rights when it comes to data scraped from property filings, marriage certificates, and public court documents, for example.
“With some very narrow exceptions, it’s either extremely difficult or impossible to compel these companies to remove your information from their sites,” Sherman told KrebsOnSecurity. “Even in states like California, every single consumer privacy law in the country completely exempts publicly available information.”
Below is a mind map that helped KrebsOnSecurity track relationships between and among the various organizations named in the story above:
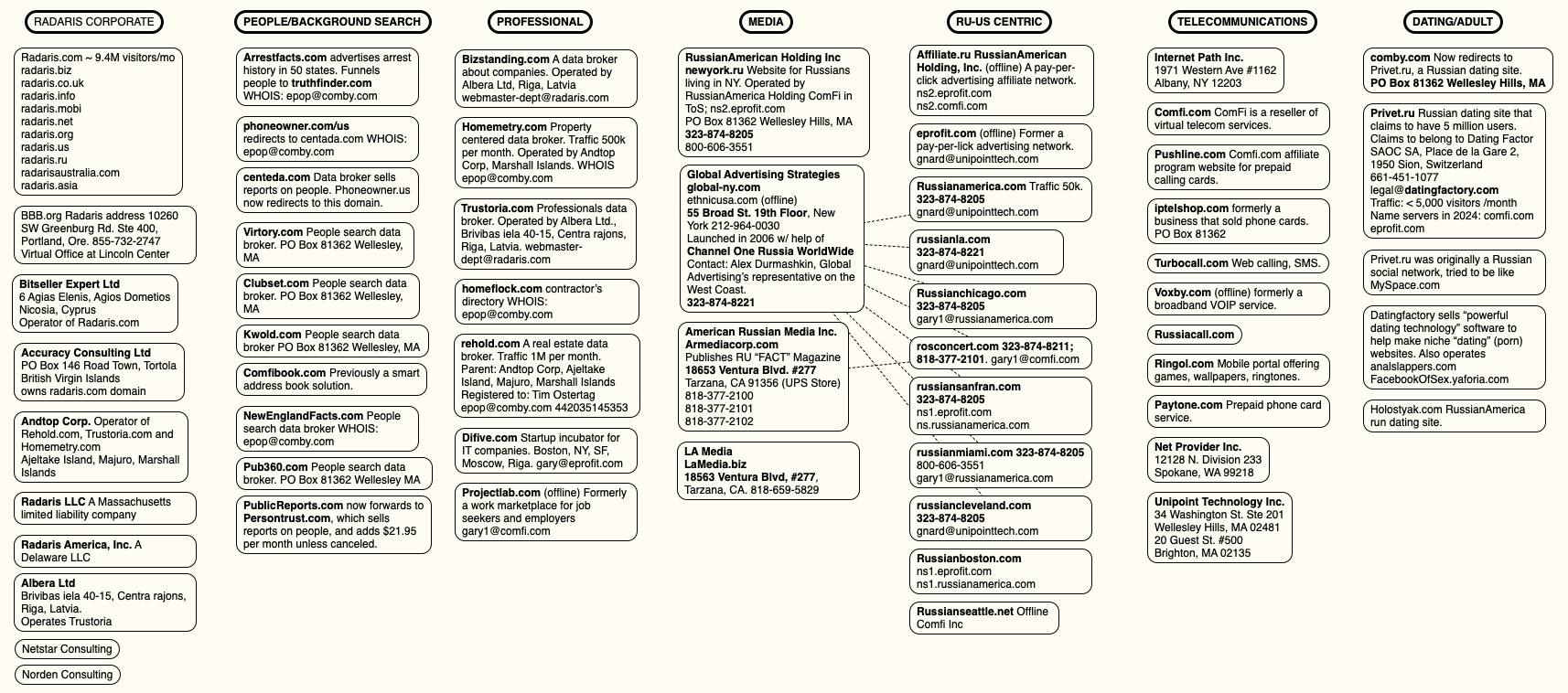
A mind map of various entities apparently tied to Radaris and the company’s co-founders. Click to enlarge.







 Closing arguments in the trial between various people and
Closing arguments in the trial between various people and 























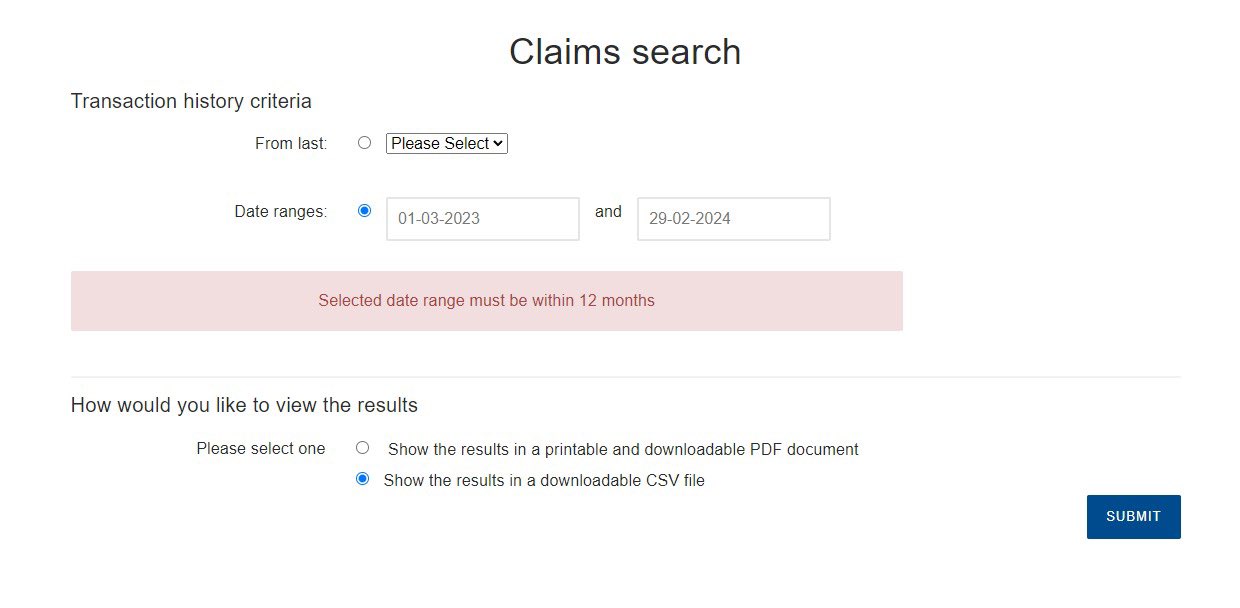







 Tightening the feedback loop Link to heading One thing we notice ever so often is that although Phosh’s source code is publicly available and upcoming changes are open for review the feedback loop between changes being made to the development branch and users noticing the change can still be quiet long.
This can be problematic as we ideally want to catch a regression or broken use case triggered by a change on the development branch (aka main) before the general availability of a new version.
Tightening the feedback loop Link to heading One thing we notice ever so often is that although Phosh’s source code is publicly available and upcoming changes are open for review the feedback loop between changes being made to the development branch and users noticing the change can still be quiet long.
This can be problematic as we ideally want to catch a regression or broken use case triggered by a change on the development branch (aka main) before the general availability of a new version.


















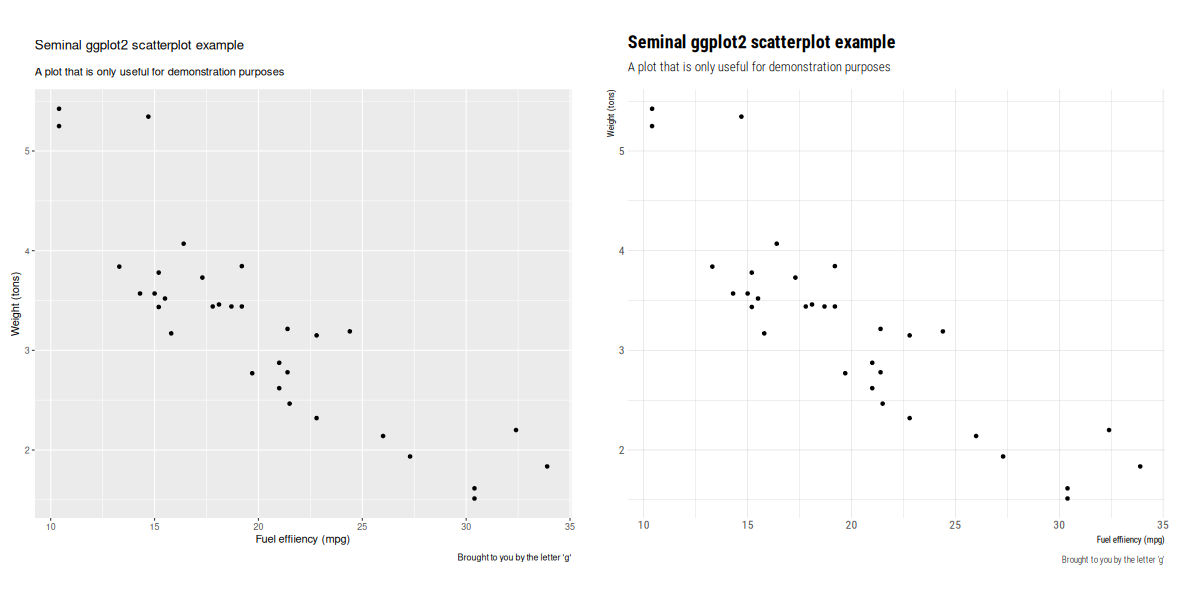







 While we couldn’t go with 6 on our upcoming LTS release, I do recommend
While we couldn’t go with 6 on our upcoming LTS release, I do recommend  March. Busy days.
March. Busy days.


!['Thank you for the loveliest evening I've ever had...' [normal] '...east of the Mississippi.' [instant intrigue!]](https://imgs.xkcd.com/comics/geographic_qualifiers.png "'Thank you for the loveliest evening I've ever had...' [normal] '...east of the Mississippi.' [instant intrigue!]")




![[later] I'm pleased to report we're now identifying and replacing hundreds of outdated metrics per hour.](https://imgs.xkcd.com/comics/goodharts_law.png "[later] I'm pleased to report we're now identifying and replacing hundreds of outdated metrics per hour.")






 Witch Wells AZ Sunset
Witch Wells AZ Sunset





{kind=link}